

2023数据采集与融合实践作业一
-
作业①:
-
实验要求:
用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
输出信息:
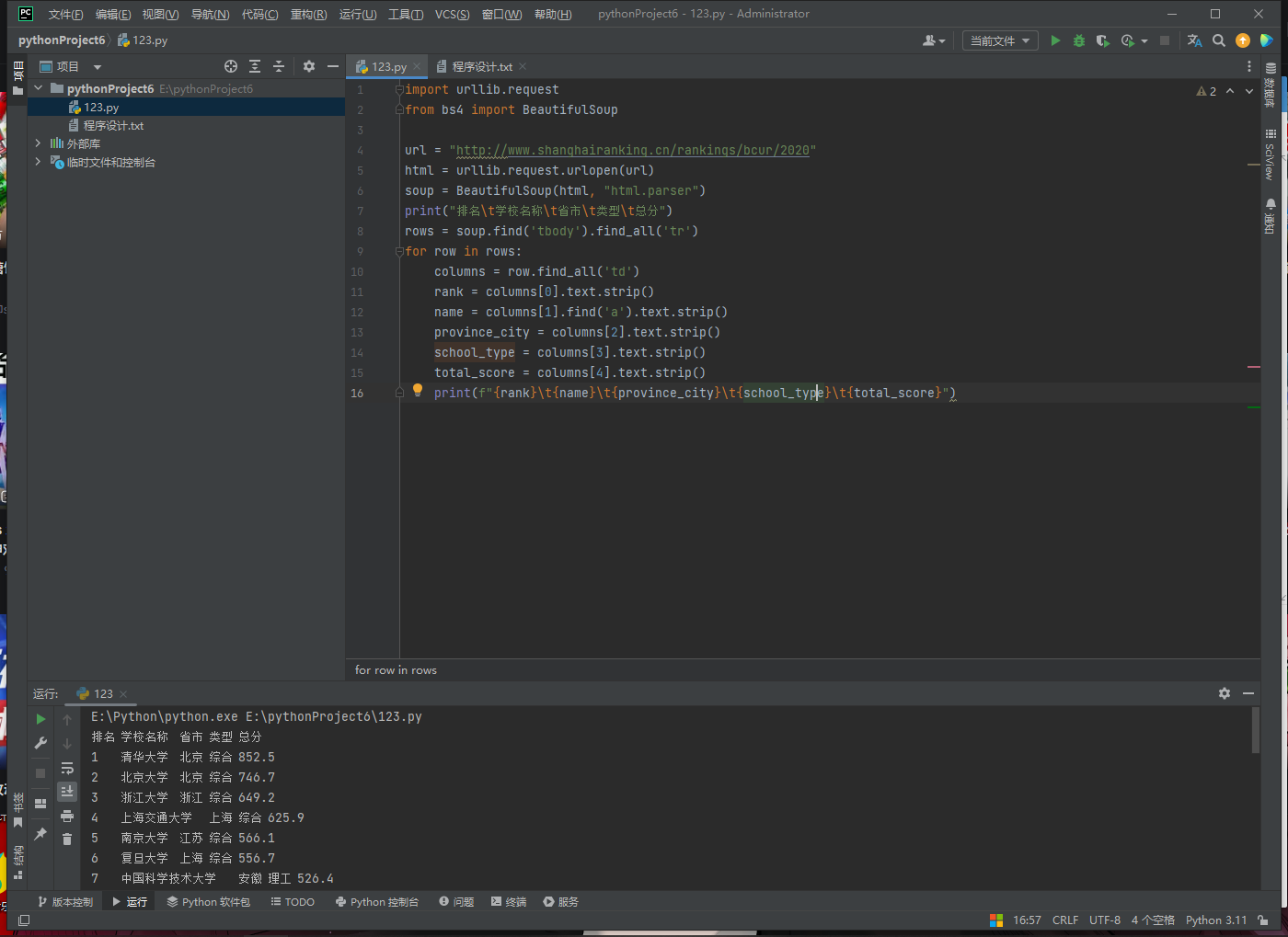
排名 学校名称 省市 学校类型 总分
1 清华大学 北京 综合 852.5
2...... -
import urllib.request
from bs4 import BeautifulSoup
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
html = urllib.request.urlopen(url)
soup = BeautifulSoup(html, "html.parser")
print("排名\t学校名称\t省市\t类型\t总分")
rows = soup.find('tbody').find_all('tr')
for row in rows:
columns = row.find_all('td')
rank = columns[0].text.strip()
name = columns[1].find('a').text.strip()
province_city = columns[2].text.strip()
school_type = columns[3].text.strip()
total_score = columns[4].text.strip()
print(f"{rank}\t{name}\t{province_city}\t{school_type}\t{total_score}")运行结果如下!
心得感想
过使用requests和BeautifulSoup库方法定向爬取数据,加深了requests和BeautifulSoup库的使用方法。
作业②:
-
-
实验要求:
用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
输出信息:
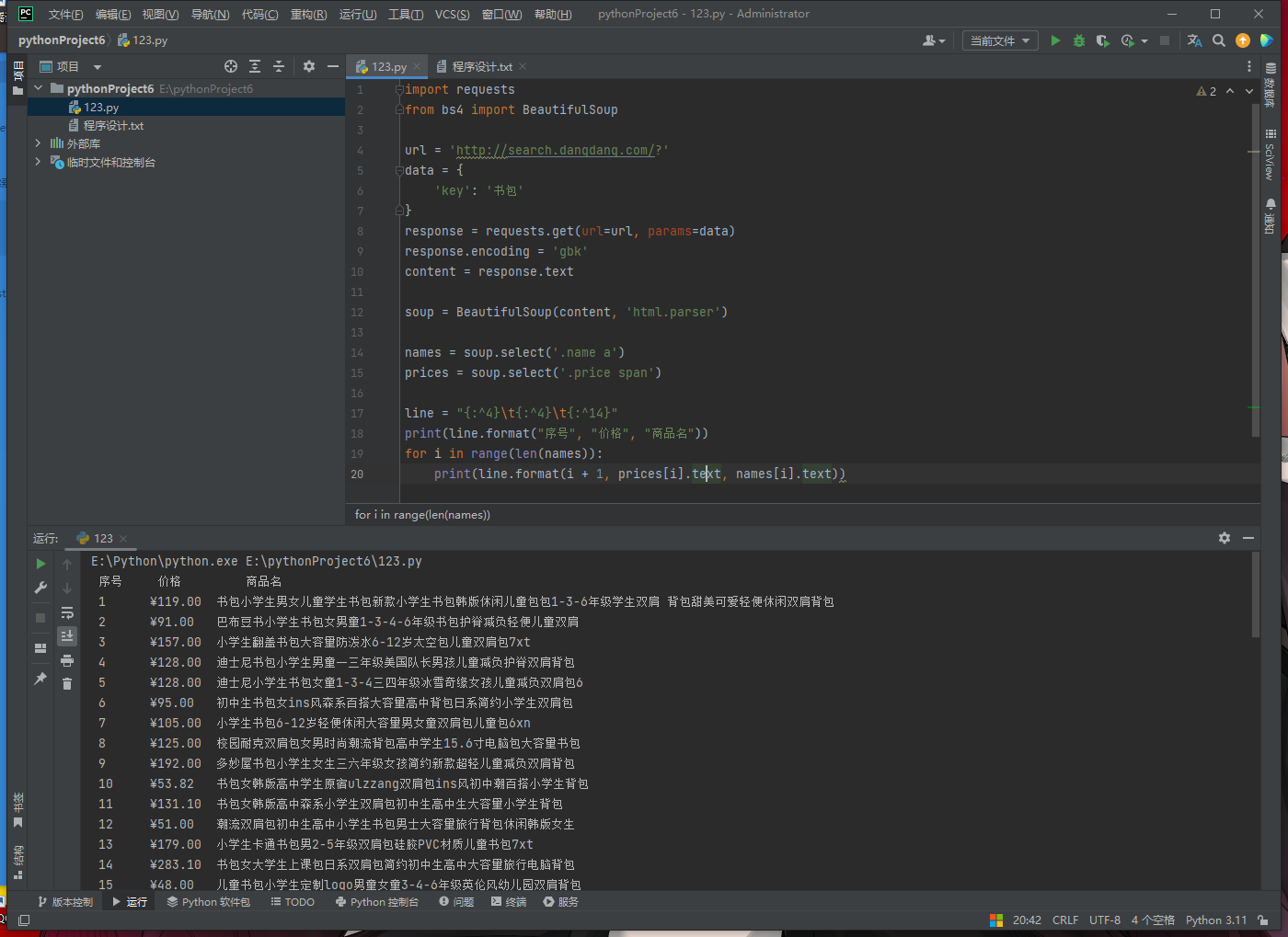
序号 价格 商品名
1 65.00 xxx
2...... -
import requests
from bs4 import BeautifulSoup
url = 'http://search.dangdang.com/?'
data = {
'key': '书包'
}
response = requests.get(url=url, params=data)
response.encoding = 'gbk'
content = response.text
soup = BeautifulSoup(content, 'html.parser')
names = soup.select('.name a')
prices = soup.select('.price span')
line = "{:^4}\t{:^4}\t{:^14}"
print(line.format("序号", "价格", "商品名"))
for i in range(len(names)):
print(line.format(i + 1, prices[i].text, names[i].text))运行结果如下
心得感想
这个作业是用re库和requests库来解决大学排名的爬取,让我对re库和requests库有了进一步的了解.
作业③:
-
实验要求:
要求:爬取一个给定网页( https://xcb.fzu.edu.cn/info/1071/4481.htm)或者自选网页的所有JPEG和JPG格式文件
输出信息:将自选网页内的所有JPEG和JPG文件保存在一个文件夹中
import requests
import re
import os
from random import randint as ri
def download_images(url, save_dir):
if not os.path.exists(save_dir):
os.makedirs(save_dir)
response = requests.get(url)
html = response.text
image_urls = re.findall('img .*?src=["\'](.*?)["\']', html)
for image_url in image_urls:
img_name = str(ri(1, 9999)) + '.jpg'
image_path = os.path.join(save_dir, img_name)
image_response = requests.get('https://xcb.fzu.edu.cn/' + image_url)
with open(image_path, 'wb') as f:
f.write(image_response.content)
url = 'https://xcb.fzu.edu.cn/info/1071/4481.htm'
save_dir = 'images'
download_images(url, save_dir)运行后下载的图片如下
心得感想
创建保存图片的目录(如果目录不存在)再使用`requests.get`方法发送GET请求获取指定URL的网页内容,将内容存储在`html`变量中。这里我使用了正则表达式找到所有图片的URL,利用`re.findall`方法。遍历所有的图片URL再生成一个随机的图片名称(使用`randint`方法),然后使用`os.path.join`方法拼接保存路径。用`requests.get`方法获取每个图片的内容,将内容写入到对应的保存路径。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)