Kaggle-data-cleaning(4)
Character-encodings
教程
What are encodings?
什么是编码,字符编码是从原始二进制字节字符串(看起来像:01101000010100100)到构成人类可读文本(例如“ hi”)的字符的映射的特定规则集。 有许多不同的编码,如果您尝试使用与最初编写的编码不同的编码来阅读文本,则最终会得到称为“ mojibake”的混乱文本(类似于mo-gee-bah-kay)。 这是mojibake的示例æ–‡å—化ã??
您可能还会以“未知”字符结尾。 当您用来读取字节字符串的编码中的特定字节与字符之间没有映射时,就会打印出以下内容:����������
如今,字符编码不匹配已经比以前少见了,但是肯定仍然是一个问题。 有很多不同的字符编码,但是您需要了解的主要编码是UTF-8。
注意:UTF-8是标准的文本编码。 所有Python代码都位于UTF-8中,理想情况下,所有数据也都应为UTF-8。 当事情不在UTF-8中时,您就会遇到麻烦。
在Python 3中使用文本时,会遇到两种主要的数据类型。一种是字符串(str),这是默认情况下的文本。其他数据是字节数据类型(bytes),它是整数序列。 您可以通过指定字符串的编码方式将其转换为字节:
before = "This is the euro symbol: €"
# encode it to a different encoding, replacing characters that raise errors after = before.encode("utf-8", errors="replace") # check the type type(after)
除了编码之外,还具备解码功能
# convert it back to utf-8 print(after.decode("utf-8"))
但是,当我们尝试使用其他编码将字节映射到字符串时,会出现错误。 这是因为我们试图使用的编码不知道如何处理我们试图传递的字节。 您需要告诉Python字节串实际上应该在其中的编码。我们可以将不同的编码视为录制音乐的不同方式。 您可以在CD,盒式磁带或8轨上录制相同的音乐。 虽然音乐听起来大致相同,但您需要使用正确的设备来播放每种录制格式的音乐。 正确的解码器就像卡带播放器或CD播放器。 如果您尝试在CD播放器中播放卡带,将无法使用。
比如after是使用utf8编码的,我们现在尝试使用ascii解码:
# try to decode our bytes with the ascii encoding print(after.decode("ascii"))
报错:

如果我们尝试使用错误的编码来将字符串映射为字节,也会遇到麻烦。 就像我之前说过的那样,Python 3默认将字符串设置为UTF-8,因此,如果我们尝试将它们视为使用另一种编码形式,则会造成问题。
例如,如果我们尝试使用encode()将字符串转换为ASCII字节,则可以要求字节与文本为ASCII时的字节相同。 但是,由于我们的文本不是ASCII,所以会有一些字符无法处理。 我们可以自动替换ASCII无法处理的字符。 但是,如果这样做,则所有非ASCII字符都将被未知字符替换。 然后,当我们将字节转换回字符串时,该字符将被未知字符替换。 与此有关的危险部分是,没有办法知道它应该是哪个字符。 这意味着我们可能刚刚使数据无法使用!
举个例子:
# start with a string before = "This is the euro symbol: €" # encode it to a different encoding, replacing characters that raise errors after = before.encode("ascii", errors = "replace") # convert it back to utf-8 print(after.decode("ascii")) # We've lost the original underlying byte string! It's been # replaced with the underlying byte string for the unknown character :(
Output:
This is the euro symbol: ?
这很糟糕,我们希望避免这样做! 最好尽快将所有文本转换为UTF-8并将其保留为该编码。 将非UTF-8输入转换为UTF-8的最佳时间是读文件时,我们将在下面讨论。
Reading in files with encoding problems
您将遇到的大多数文件可能都使用UTF-8编码。 这是Python默认情况下期望的,因此大多数时候您都不会遇到问题。 但是,有时会出现如下错误:
# try to read in a file not in UTF-8 kickstarter_2016 = pd.read_csv("../input/kickstarter-projects/ks-projects-201612.csv")
报错:

请注意,当我们尝试将UTF-8字节解码为ASCII时,会得到与UnicodeDecodeError相同的错误!这告诉我们该文件实际上不是UTF-8。我们不知道它实际上是什么编码。解决该问题的一种方法是尝试测试一堆不同的字符编码,然后查看它们中的任何一种是否起作用。但是,更好的方法是使用chardet模块尝试自动猜测正确的编码是什么。并非100%保证是正确的,但通常比尝试猜测要快。
我将只看该文件的前一万个字节。通常,这足以使人猜出编码是什么,并且比尝试查看整个文件要快得多。 (特别是对于大文件,这可能非常慢。)仅查看文件第一部分的另一个原因是,通过查看错误消息,我们可以看到第一个问题是第11个字符。因此,我们可能只需要查看文件的开头部分,以了解发生了什么情况。
# look at the first ten thousand bytes to guess the character encoding with open("../input/kickstarter-projects/ks-projects-201801.csv", 'rb') as rawdata: result = chardet.detect(rawdata.read(10000)) # check what the character encoding might be print(result)
Output:
{'encoding': 'Windows-1252', 'confidence': 0.73, 'language': ''}
因此,chardet对正确的编码是“ Windows-1252”有73%的置信度。 让我们看看是否正确:
# read in the file with the encoding detected by chardet kickstarter_2016 = pd.read_csv("../input/kickstarter-projects/ks-projects-201612.csv", encoding='Windows-1252') # look at the first few lines kickstarter_2016.head()
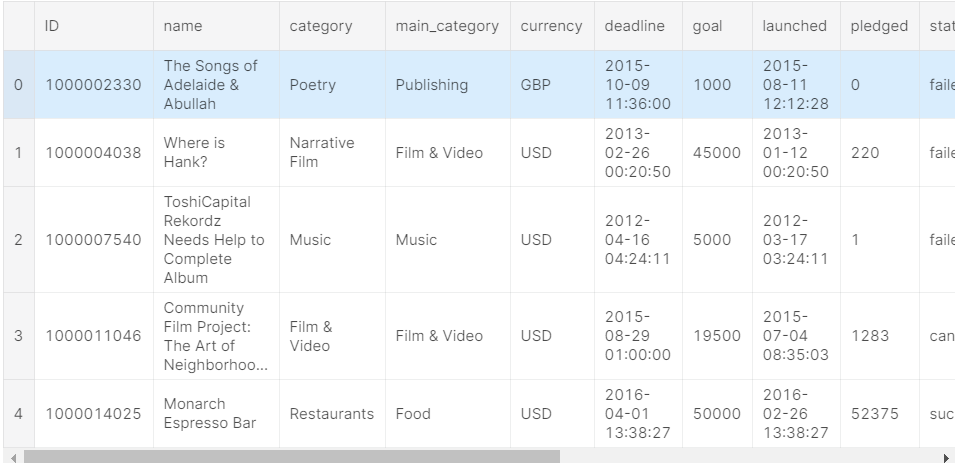
正确!但如果编码chardet猜错了怎么办? 由于chardet基本上只是个花哨的猜测者,因此有时它会猜测错误的编码。 您可以尝试做的一件事是查看文件的更多或更少,然后查看是否得到不同的结果,然后尝试执行该操作。
Saving your files with UTF-8 encoding
最后,一旦解决了将文件放入UTF-8的所有麻烦,您可能会希望保持这种状态。 最简单的方法是使用UTF-8编码保存文件。 好消息是,由于UTF-8是Python中的标准编码,因此当您保存文件时,默认情况下它将保存为UTF-8:
# save our file (will be saved as UTF-8 by default!) kickstarter_2016.to_csv("ks-projects-201801-utf8.csv")
这样保存的文件格式就是UTF-8了
练习
1) What are encodings?
You're working with a dataset composed of bytes. Run the code cell below to print a sample entry.
sample_entry = b'\xa7A\xa6n' print(sample_entry) print('data type:', type(sample_entry))
Output:
b'\xa7A\xa6n' data type: <class 'bytes'>
您会注意到它没有使用标准的UTF-8编码。
使用下一个代码单元创建变量new_entry,该变量将编码从“ big5-tw”更改为“ utf-8”。 new_entry应该具有bytes数据类型。
new_entry = sample_entry.decode("big5-tw") print(new_entry) new_entry=new_entry.encode("utf-8", errors="replace") # Check your answer q1.check()
Output:
你好
2) Reading in files with encoding problems
使用下面的代码单元在路径“ ../input/fatal-police-shootings-in-the-us/PoliceKillingsUS.csv”中读取该文件。找出正确的编码方式,然后将文件读入DataFrame Police_killings。
with open("../input/fatal-police-shootings-in-the-us/PoliceKillingsUS.csv", 'rb') as rawdata: result = chardet.detect(rawdata.read(10000)) # check what the character encoding might be print(result) # TODO: Load in the DataFrame correctly. police_killings = pd.read_csv("../input/fatal-police-shootings-in-the-us/PoliceKillingsUS.csv",encoding='ascii') print(police_killings.head(5)) # Check your answer q2.check()
Output:
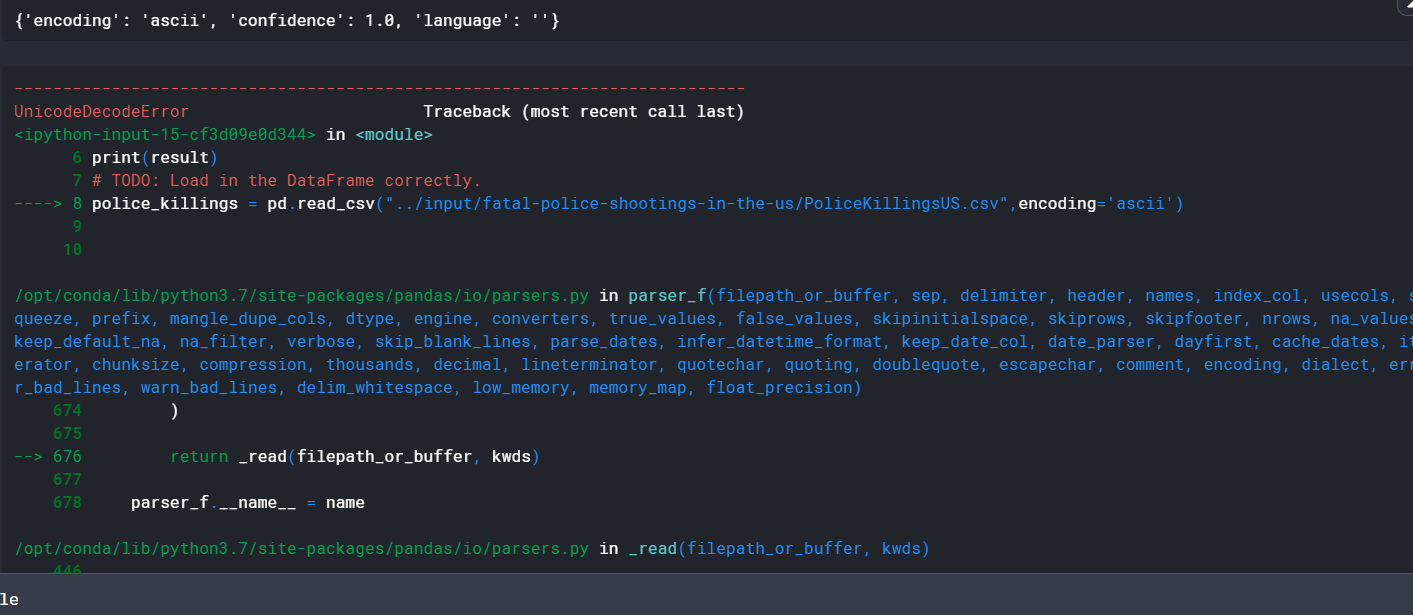
原以为10000行置信度100%已经稳了,结果还是一堆问题,将区间调大为100000:
编码格式变化:

代码改为:
# look at the first ten thousand bytes to guess the character encoding with open("../input/fatal-police-shootings-in-the-us/PoliceKillingsUS.csv", 'rb') as rawdata: result = chardet.detect(rawdata.read(100000)) # check what the character encoding might be print(result) # TODO: Load in the DataFrame correctly. police_killings = pd.read_csv("../input/fatal-police-shootings-in-the-us/PoliceKillingsUS.csv",encoding='Windows-1252') print(police_killings.head(5)) # Check your answer q2.check()
Output:

3) Saving your files with UTF-8 encoding
使用UTF-8编码将警察杀人数据集的版本保存到CSV。 保存此文件后,您的答案将被标记为正确。
注意:使用to_csv()方法时,仅提供文件名(例如“ my_file.csv”)。 这会将文件保存在文件路径“ /kaggle/working/my_file.csv”中。
# TODO: Save the police killings dataset to CSV police_killings = pd.read_csv("../input/fatal-police-shootings-in-the-us/PoliceKillingsUS.csv",encoding='Windows-1252') print(police_killings) police_killings.to_csv("PoliceKillingsUS.csv") # Check your answer q3.check()
