Kaggle-data-cleaning(3)
Parsing-dates
教程
实际情况下我们的保存文件之中日期往往为字符串。
Pandas使用“ object” dtype来存储各种类型的数据类型,但是大多数情况下,当您看到带有dtype“ object”的列时,它就会包含字符串。
如果在此处查看pandas dtype文档,您会发现还有一个特定的datetime64 dtypes。 因为我们列的dtype是object而不是datetime64,所以我们可以说Python不知道此列包含日期。
那我们怎么将日期列转化为日期时间呢?这需要解析日期
Convert our date columns to datetime
现在我们知道我们的日期列未被识别为日期,是时候进行转换以便将其识别为日期了。 之所以称为“解析日期”,是因为我们要接收字符串并标识其组成部分。
我们可以使用称为“ strftime指令”的指南来熊猫显示日期格式,您可以在此链接上找到更多信息。 基本想法是,您需要指出日期的哪些部分在哪里以及它们之间的标点符号。 日期中可能有很多部分,但最常见的是%d表示日期,%m表示月份,%y表示两位数字的年份和%Y表示四位数的年份。
如
- 1/17/07形式为 "%m/%d/%y"
- 17-1-2007 形式为"%d-%m-%Y"
在代码层面,可以书写为如下形式
# create a new column, date_parsed, with the parsed dates landslides['date_parsed'] = pd.to_datetime(landslides['date'], format="%m/%d/%y")
现在,当我检查新列的前几行时,我可以看到dtype是datetime64。 我还可以看到我的日期已经重新排列,以便它们适合默认的订单日期时间对象(年-月-日)。
Select the day of the month
我们想获取某一天的信息:
# get the day of the month from the date_parsed column day_of_month_landslides = landslides['date_parsed'].dt.day day_of_month_landslides.head()
如果尝试从原始“日期”列中获取相同的信息,则会收到错误消息:AttributeError: Can only use .dt accessor with datetimelike values。 这是因为dt.day不知道如何处理dtype为“ object”的列。 即使我们的数据帧中包含日期,我们也必须先解析它们,然后才能以一种有用的方式与它们进行交互。
Plot the day of the month to check the date parsing
解析日期的最大危险之一是将月份和日期混淆在一起。 to_datetime()函数确实具有非常有用的错误消息,但是再次检查我们提取的月份中的几天是否有意义也没有什么害处。
为此,让我们绘制一个月中各天的直方图。 我们希望它的值在1到31之间,并且由于没有理由假设该滑坡在一个月的某些天比其他几天更普遍,因此分布相对均匀。 (因为并非所有月份都有31天,所以减少31)。让我们看看是否是这种情况:
# remove na's day_of_month_landslides = day_of_month_landslides.dropna() # plot the day of the month sns.distplot(day_of_month_landslides, kde=False, bins=31)
练习
1) Check the data type of our date column
You'll be working with the "Date" column from the earthquakes dataframe. Investigate this column now: does it look like it contains dates? What is the dtype of the column?
# TODO: Your code here!
print(earthquakes.head(5))
print(earthquakes.Date.dtype)
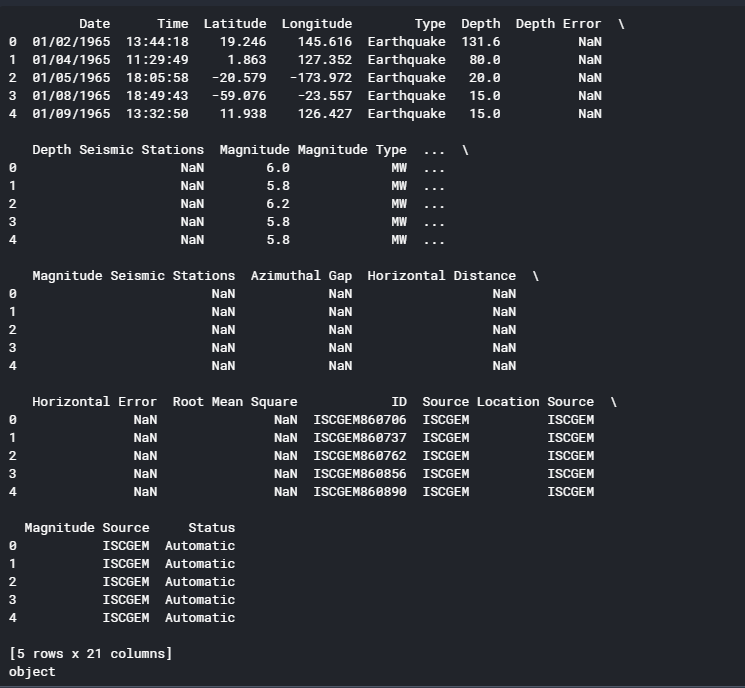
存在日期列,且其值为Object类型
2) Convert our date columns to datetime
正常情况下,日期应该有固定唯一的格式,但是实际情况下很存在多种格式,如下图所示:
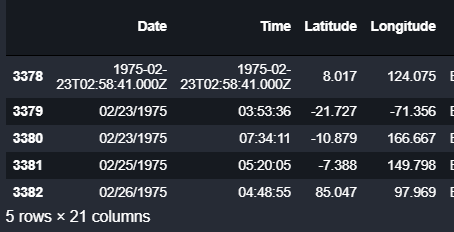
我们想看看其广泛性
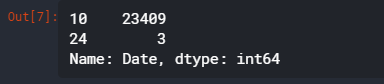
date_lengths = earthquakes.Date.str.len()
date_lengths.value_counts()
先找出到底是那些行不安分:
indices = np.where([date_lengths == 24])[1] print('Indices with corrupted data:', indices) earthquakes.loc[indices]
Output:
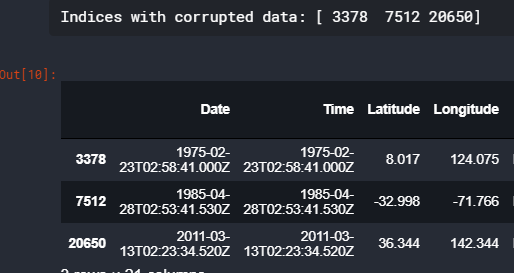
找到了三个坏蛋
Given all of this information, it's your turn to create a new column "date_parsed" in the earthquakes dataset that has correctly parsed dates in it.
Note: When completing this problem, you are allowed to (but are not required to) amend the entries in the "Date" and "Time" columns. Do not remove any rows from the dataset.
由于数据不是很多,手动处理即可
# TODO: Your code here earthquakes.loc[3378, "Date"] = "02/23/1975" earthquakes.loc[7512, "Date"] = "04/28/1985" earthquakes.loc[20650, "Date"] = "03/13/2011" print(earthquakes.loc[3378, "Date"]) earthquakes['date_parsed'] = pd.to_datetime(earthquakes['Date'], format="%m/%d/%Y") # Check your answer q2.check()
3) Select the day of the month
Create a Pandas Series day_of_month_earthquakes containing the day of the month from the "date_parsed" column.
直接将解析好的数据调用dt访问器的day即可
# try to get the day of the month from the date column day_of_month_earthquakes = earthquakes['date_parsed'].dt.day print(day_of_month_earthquakes) # Check your answer q3.check()
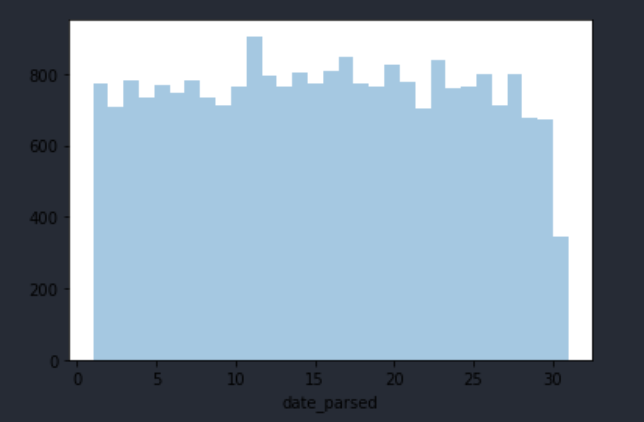
4) Plot the day of the month to check the date parsing
Plot the days of the month from your earthquake dataset.
# TODO: Your code here! day_of_month_earthquakes = day_of_month_earthquakes.dropna() sns.distplot(day_of_month_earthquakes, kde=False, bins=31)