Kaggle-data-cleaning(1)
Handling-missing-values
教程
数据清理是数据科学的关键部分,但可能会令人沮丧。 为什么您的某些文本字段出现乱码? 对于那些缺失的值,您应该怎么做? 为什么日期格式不正确? 如何快速清理不一致的数据输入? 在本课程中,您将学习为什么会遇到这些问题,更重要的是,如何解决这些问题!
在本课程中,您将学习如何解决一些最常见的数据清除问题,从而可以更快地实际分析数据。 您将通过五个动手练习来处理真实,混乱的数据,并回答一些最常提出的数据清理问题。
在本笔记本中,我们将研究如何处理缺失的值。
Take a first look at the data
获取新数据集时,要做的第一件事就是看一些数据集。 这样一来,您就可以正确读取所有内容,并了解数据的状况。 在这种情况下,让我们看看是否存在任何缺失值,将使用NaN或None来表示。使用pd.head()等打印表,如下
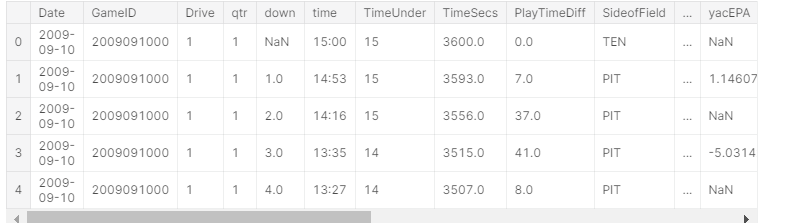
可以看出yacEPA的值有一部分为缺失值
How many missing data points do we have
现在我们知道我们确实缺少一些值。 让我们看看每列中有多少。
# get the number of missing data points per column missing_values_count = nfl_data.isnull().sum() # look at the # of missing points in the first ten columns missing_values_count[0:10]
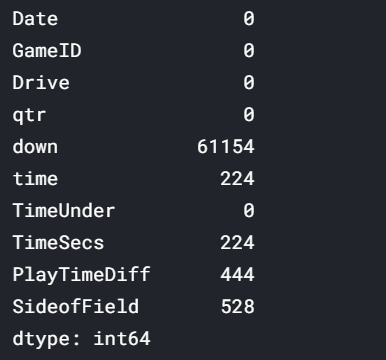
好像很多缺失值! 查看数据集中缺失多少百分比的值可能会有所帮助,以使我们更好地了解此问题的严重性:
# how many total missing values do we have? total_cells = np.product(nfl_data.shape) total_missing = missing_values_count.sum() # percent of data that is missing percent_missing = (total_missing/total_cells) * 100 print(percent_missing)
Output:
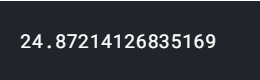
可以看出缺失值接近总值的25%,所以对缺失值的处理是一件很重要的事情
Figure out why the data is missing
在这一点上,我们进入了我喜欢称之为“数据直觉”的数据科学部分,这是指“真正地查看您的数据并试图弄清楚为什么它是这样以及它将如何发展”。影响您的分析”。它可能是数据科学令人沮丧的一部分,尤其是如果您是该领域的新手并且没有太多经验。为了处理缺失的值,您需要使用自己的直觉来找出为什么缺少该值。您可以要求自己帮助解决这一问题的最重要的问题之一是:
是否由于未记录或不存在而缺少该值?
如果缺少某个值是因为该值不存在(例如没有任何孩子的某人的最大孩子的身高),那么尝试猜测它可能是没有意义的。您可能希望将这些值保留为NaN。另一方面,如果某个值由于未记录而丢失,则可以尝试根据该列和行中的其他值来猜测该值。这被称为归因,我们接下来将学习如何做! :)
让我们来看一个例子。查看nfl_data数据帧中缺失值的数量,我注意到“ TimesSec”列中有很多缺失值:
通过查看文档,我可以看到此列包含有关进行游戏时游戏中剩余秒数的信息。 这意味着这些值可能会丢失,因为它们没有被记录,而不是因为它们不存在。 因此,对我们来说,尝试猜测它们应该是什么而不是仅仅将它们保留为NA是有意义的。
另一方面,还有其他字段,例如“ PenalizedTeam”,也缺少很多字段。 但是,在这种情况下,该字段会丢失,因为如果没有处罚,那么说哪支球队受到处罚就没有意义了。 对于此列,将其保留为空或添加第三个值(如“ nether”)并使用该值替换NA会更有意义。
如果您进行非常仔细的数据分析,则可以在此逐一查看每一列,以找出填补这些缺失值的最佳策略。 在本笔记本的其余部分中,我们将介绍一些“快速而肮脏的”技术,这些技术可以帮助您消除缺失的值,但可能最终还会删除一些有用的信息或给您的数据增加一些干扰。
Drop missing values
如果您很着急或没有理由弄清楚为什么缺少值,那么您必须采取的一种选择就是删除任何包含缺少值的行或列。 (注意:对于重要的项目,我一般不建议使用这种方法!花时间浏览数据并真正地逐一查看所有缺少值的列以真正了解您的数据集通常是值得的 )
如果您确定要删除缺少值的行,则pandas确实有一个方便的函数dropna()来帮助您完成此操作。 让我们在我们的NFL数据集中尝试一下!
使用df.dropna()默认删去有缺失值的行
使用参数df.dropna(axis=1)可以删去有缺失值的列
Filling in missing values automatically
另一种选择是尝试填写缺少的值。 接下来,我将获得NFL数据的一小部分,以使其能够很好地打印。
使用如下的形式:
# replace all NA's with 0 subset_nfl_data.fillna(0)
这样有一些弊端
也可以更精明一些,将丢失的值替换为同一列中紧随其后的任何值。 (这对于观测值具有某种逻辑顺序的数据集非常有意义。)
将所有NA替换为同一列中紧随其后的值(后面的一列需要存在且不为NA),然后将所有剩余的NA替换为0
# replace all NA's the value that comes directly after it in the same column, # then replace all the remaining na's with 0 subset_nfl_data.fillna(method='bfill', axis=0).fillna(0)
练习
1) Take a first look at the data
# TODO: Your code here! print(sf_permits)

明显有缺失值
2) How many missing data points do we have?
What percentage of the values in the dataset are missing? Your answer should be a number between 0 and 100. (If 1/4 of the values in the dataset are missing, the answer is 25.)
# TODO: Your code here! missing_values_count=sf_permits.isnull().sum() total_cells = np.product(sf_permits.shape) total_missing = missing_values_count.sum() # percent of data that is missing percent_missing = (total_missing/total_cells) * 100 print(percent_missing) # Check your answer q2.check()
3) Figure out why the data is missing
Look at the columns "Street Number Suffix" and "Zipcode" from the San Francisco Building Permits dataset. Both of these contain missing values.
- Which, if either, are missing because they don't exist?
- Which, if either, are missing because they weren't recorded?
Once you have an answer, run the code cell below.
# Check your answer (Run this code cell to receive credit!) col=["Street Number Suffix","Zipcode"] print(sf_permits.loc[:,col]) q3.check()
Output:
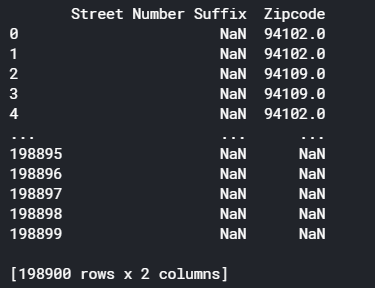
地址有些不包含街道号码后缀,而通常所有地址都有邮政编码
所以如果“街道编号后缀”列中的值丢失,则可能是因为该值不存在。 如果缺少“邮政编码”列中的值,则不会记录该值。
4) Drop missing values: rows
If you removed all of the rows of sf_permits with missing values, how many rows are left?
Note: Do not change the value of sf_permits when checking this.
# TODO: Your code here! # sf_permits.dropna() print(sf_permits.dropna().shape)
Output:
(0, 43)
所以每一行至少都有一个值缺失
5) Drop missing values: columns
Now try removing all the columns with empty values.
- Create a new DataFrame called
sf_permits_with_na_droppedthat has all of the columns with empty values removed. - How many columns were removed from the original
sf_permitsDataFrame? Use this number to set the value of thedropped_columnsvariable below.
# TODO: Your code here sf_permits_with_na_dropped = sf_permits.dropna(axis=1) print(sf_permits_with_na_dropped) dropped_columns = sf_permits.shape[1]-sf_permits_with_na_dropped.shape[1] print(dropped_columns) # Check your answer q5.check()
6) Fill in missing values automatically
Try replacing all the NaN's in the sf_permits data with the one that comes directly after it and then replacing any remaining NaN's with 0. Set the result to a new DataFrame sf_permits_with_na_imputed.
# TODO: Your code here sf_permits_with_na_imputed = sf_permits.fillna(method='bfill', axis=0).fillna(0) # Check your answer q6.check()
