
用MPI进行分布式内存编程(1)
《并行程序设计导论》第三章部分程序
程序3.1运行实例
#include<stdio.h> #include<string.h> #include<mpi.h> const int MAX_STRING=100; int main() { char greet[MAX_STRING]; int comm_sz; //进程数 int my_rank; //进程号 MPI_Init(NULL,NULL); //初始化 MPI_Comm_size(MPI_COMM_WORLD,&comm_sz); //返回进程数 MPI_Comm_rank(MPI_COMM_WORLD,&my_rank); //返回进程号 if(my_rank!=0) { sprintf(greet,"Greeting from process %d of %d",my_rank,comm_sz); MPI_Send(greet,strlen(greet)+1,MPI_CHAR,0,0,MPI_COMM_WORLD); //通信,发送 } else { printf("Greeting from process %d of %d",my_rank,comm_sz); int q; for( q=1;q<comm_sz;q++) { MPI_Recv(greet,MAX_STRING,MPI_CHAR,q,0,MPI_COMM_WORLD,MPI_STATUS_IGNORE);//通信,接收 printf("%s\n",greet); } } MPI_Finalize(); //告知系统MPI已使用完毕 return 0; }
在天河平台运行结果
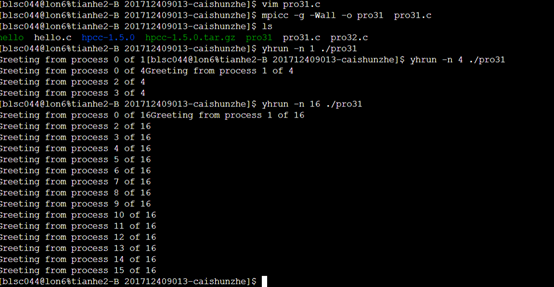
自己虚拟机运行结果

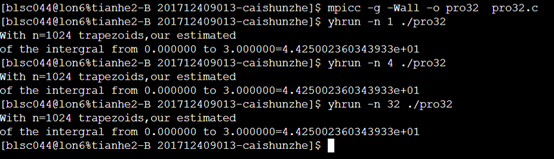
3.2运行实例
#include<stdio.h> #include<string.h> #include<mpi.h> double f(double x) { return x*x+x*x*x+5; } double Trap(double left_endpt,double right_endpt,int trap_count,double base_len) { double estimate,x; int i; estimate=(f(left_endpt)+f(right_endpt))/2.0; //梯形面积 for(i =1;i<=trap_count-1;++i) { x=left_endpt+i*base_len; estimate+=f(x); } estimate=estimate*base_len; return estimate; } int main() { int my_rank,comm_sz,n=1024,local_n; double a=0.0,b=3.0,h,local_a,local_b; double local_int,total_int; int source; MPI_Init(NULL,NULL); //初始化 MPI_Comm_size(MPI_COMM_WORLD,&comm_sz); //返回进程数 MPI_Comm_rank(MPI_COMM_WORLD,&my_rank); //返回进程号 h=(b-a)/n; local_n=n/comm_sz; local_a=a+my_rank*local_n*h; local_b=local_a+local_n*h; local_int=Trap(local_a,local_b,local_n,h); if(my_rank!=0) { MPI_Send(&local_int,1,MPI_DOUBLE,0,0,MPI_COMM_WORLD); } else { total_int=local_int; for(source=1;source<comm_sz;source++) { MPI_Recv(&local_int,1,MPI_DOUBLE,source,0,MPI_COMM_WORLD,MPI_STATUS_IGNORE); //接受其他节点信息 total_int+=local_int; } } if(my_rank==0) { printf("With n=%d trapezoids,our estimated\n",n); printf("of the intergral from %f to %f=%.15e\n",a,b,total_int); } MPI_Finalize(); return 0; }
天河运行结果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号