Mapreduce数据分析实例
数据包
百度网盘
链接:https://pan.baidu.com/s/1v9M3jNdT4vwsqup9N0mGOA
提取码:hs9c
复制这段内容后打开百度网盘手机App,操作更方便哦
1、 数据清洗说明:
(1) 第一列是时间;
(2) 第二列是卖出方;
(3) 第三列是买入方;
(4) 第四列是票的数量;
(5) 第五列是金额。
卖出方,买入方一共三个角色,机场(C开头),代理人(O开头)和一般顾客(PAX)
2、 数据清洗要求:
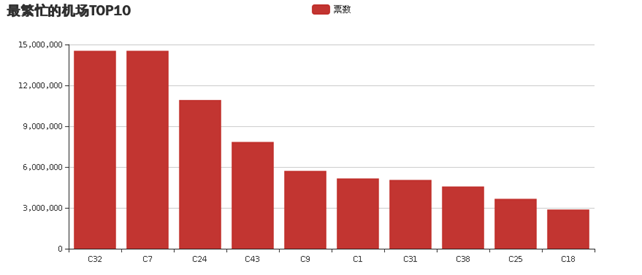
(1)统计最繁忙的机场Top10(包括买入卖出);
(2)统计最受欢迎的航线;(起点终点一致(或相反))
(3)统计最大的代理人TOP10;
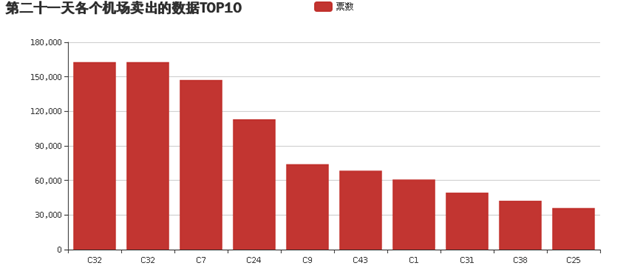
(4)统计某一天的各个机场的卖出数据top10。
3、 数据可视化要求:
(1)上述四中统计要求可以用饼图、柱状图等显示;
(2)可用关系图展示各个机场之间的联系程度(以机票数量作为分析来源)。
实验关键部分代码(列举统计最繁忙机场的代码,其他代码大同小异):
数据初步情理,主要是过滤出各个机场个总票数
1. package mapreduce; 2. import java.io.IOException; 3. import java.net.URI; 4. import org.apache.hadoop.conf.Configuration; 5. import org.apache.hadoop.fs.Path; 6. import org.apache.hadoop.io.LongWritable; 7. import org.apache.hadoop.io.Text; 8. import org.apache.hadoop.mapreduce.Job; 9. import org.apache.hadoop.mapreduce.Mapper; 10. import org.apache.hadoop.mapreduce.Reducer; 11. import org.apache.hadoop.mapreduce.lib.chain.ChainMapper; 12. import org.apache.hadoop.mapreduce.lib.chain.ChainReducer; 13. import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 14. import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; 15. import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 16. import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; 17. import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner; 18. import org.apache.hadoop.fs.FileSystem; 19. import org.apache.hadoop.io.IntWritable; 20. public class ChainMapReduce { 21. private static final String INPUTPATH = "hdfs://localhost:9000/mapreducetest/region.txt"; 22. private static final String OUTPUTPATH = "hdfs://localhost:9000/mapreducetest/out1"; 23. public static void main(String[] args) { 24. try { 25. Configuration conf = new Configuration(); 26. FileSystem fileSystem = FileSystem.get(new URI(OUTPUTPATH), conf); 27. if (fileSystem.exists(new Path(OUTPUTPATH))) { 28. fileSystem.delete(new Path(OUTPUTPATH), true); 29. } 30. Job job = new Job(conf, ChainMapReduce.class.getSimpleName()); 31. FileInputFormat.addInputPath(job, new Path(INPUTPATH)); 32. job.setInputFormatClass(TextInputFormat.class); 33. ChainMapper.addMapper(job, FilterMapper1.class, LongWritable.class, Text.class, Text.class, IntWritable.class, conf); 34. ChainReducer.setReducer(job, SumReducer.class, Text.class, IntWritable.class, Text.class, IntWritable.class, conf); 35. job.setMapOutputKeyClass(Text.class); 36. job.setMapOutputValueClass(IntWritable.class); 37. job.setPartitionerClass(HashPartitioner.class); 38. job.setNumReduceTasks(1); 39. job.setOutputKeyClass(Text.class); 40. job.setOutputValueClass(IntWritable.class); 41. FileOutputFormat.setOutputPath(job, new Path(OUTPUTPATH)); 42. job.setOutputFormatClass(TextOutputFormat.class); 43. System.exit(job.waitForCompletion(true) ? 0 : 1); 44. } catch (Exception e) { 45. e.printStackTrace(); 46. } 47. } 48. public static class FilterMapper1 extends Mapper<LongWritable, Text, Text, IntWritable> { 49. private Text outKey = new Text(); 50. private IntWritable outValue = new IntWritable(); 51. @Override 52. protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) 53. throws IOException,InterruptedException { 54. String line = value.toString(); 55. if (line.length() > 0) { 56. String[] arr = line.split(","); 57. int visit = Integer.parseInt(arr[3]); 58. if(arr[1].substring(0, 1).equals("C")||arr[2].substring(0, 1).equals("C")){ 59. outKey.set(arr[1]); 60. outValue.set(visit); 61. context.write(outKey, outValue); 62. } 63. } 64. } 65. } 66. 67. public static class SumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { 68. private IntWritable outValue = new IntWritable(); 69. @Override 70. protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) 71. throws IOException, InterruptedException { 72. int sum = 0; 73. for (IntWritable val : values) { 74. sum += val.get(); 75. } 76. outValue.set(sum); 77. context.write(key, outValue); 78. } 79. } 80. 81. 82. }
数据二次清理,进行排序
package mapreduce; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class OneSort { public static class Map extends Mapper<Object , Text , IntWritable,Text >{ private static Text goods=new Text(); private static IntWritable num=new IntWritable(); public void map(Object key,Text value,Context context) throws IOException, InterruptedException{ String line=value.toString(); String arr[]=line.split("\t"); num.set(Integer.parseInt(arr[1])); goods.set(arr[0]); context.write(num,goods); } } public static class Reduce extends Reducer< IntWritable, Text, IntWritable, Text>{ private static IntWritable result= new IntWritable(); public void reduce(IntWritable key,Iterable<Text> values,Context context) throws IOException, InterruptedException{ for(Text val:values){ context.write(key,val); } } } public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException{ Configuration conf=new Configuration(); Job job =new Job(conf,"OneSort"); job.setJarByClass(OneSort.class); job.setMapperClass(Map.class); job.setReducerClass(Reduce.class); job.setOutputKeyClass(IntWritable.class); job.setOutputValueClass(Text.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); Path in=new Path("hdfs://localhost:9000/mapreducetest/out1/part-r-00000"); Path out=new Path("hdfs://localhost:9000/mapreducetest/out2"); FileInputFormat.addInputPath(job,in); FileOutputFormat.setOutputPath(job,out); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
从hadoop中读取文件
-
package mapreduce; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.net.URI; import java.util.ArrayList; import java.util.List; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; public class ReadFile { public static List<String> ReadFromHDFS(String file) throws IOException { //System.setProperty("hadoop.home.dir", "H:\\文件\\hadoop\\hadoop-2.6.4"); List<String> list=new ArrayList(); int i=0; Configuration conf = new Configuration(); StringBuffer buffer = new StringBuffer(); FSDataInputStream fsr = null; BufferedReader bufferedReader = null; String lineTxt = null; try { FileSystem fs = FileSystem.get(URI.create(file),conf); fsr = fs.open(new Path(file)); bufferedReader = new BufferedReader(new InputStreamReader(fsr)); while ((lineTxt = bufferedReader.readLine()) != null) { String[] arg=lineTxt.split("\t"); list.add(arg[0]); list.add(arg[1]); } } catch (Exception e) { e.printStackTrace(); } finally { if (bufferedReader != null) { try { bufferedReader.close(); } catch (IOException e) { e.printStackTrace(); } } } return list; } public static void main(String[] args) throws IOException { List<String> ll=new ReadFile().ReadFromHDFS("hdfs://localhost:9000/mapreducetest/out2/part-r-00000"); for(int i=0;i<ll.size();i++) { System.out.println(ll.get(i)); } } }
前台网页代码
<%@page import="mapreduce.ReadFile"%> <%@page import="java.util.List"%> <%@page import="java.util.ArrayList"%> <%@page import="org.apache.hadoop.fs.FSDataInputStream" %> <%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%> <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Insert title here</title> <% List<String> ll= ReadFile.ReadFromHDFS("hdfs://localhost:9000/mapreducetest/out2/part-r-00000");%> <script src="../js/echarts.js"></script> </head> <body> <div id="main" style="width: 900px;height:400px;"></div> <script type="text/javascript"> // 基于准备好的dom,初始化echarts实例 var myChart = echarts.init(document.getElementById('main')); // 指定图表的配置项和数据 var option = { title: { text: '最繁忙的机场TOP10' }, tooltip: {}, legend: { data:['票数'] }, xAxis: { data:["<%=ll.get(ll.size()-1)%>"<%for(int i=ll.size()-3;i>=ll.size()-19;i--){ if(i%2==1){ %>,"<%=ll.get(i)%>" <% } } %>] }, yAxis: {}, series: [{ name: '票数', type: 'bar', data: [<%=ll.get(ll.size()-2)%> <%for(int i=ll.size()-1;i>=ll.size()-19;i--){ if(i%2==0){ %>,<%=ll.get(i)%> <% } } %>] }] }; // 使用刚指定的配置项和数据显示图表。 myChart.setOption(option); </script> <h2 color="red"><a href="NewFile.jsp">返回</a></h2> </body>
结果截图:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号