

【并发编程和MySQL入门】周总结
目录
1. 操作系统的发展史
1.1 五大组成
- 控制器:控制计算机各个硬件的工作
- 运算器:数字运算,逻辑运算(核心)
- 存储器:内存,外存
- 输入设备:给计算机内部传递数据
- 输出设备:让计算机给外界传递数据
1.2 三大核心硬件
- CPU:是计算机中真正干活的人
- 内存:给CPU准备需要运行的代码
- 硬盘:永远存储将来可能要运行的代码
- 强调:CPU是整个计算机执行效率的核心
1.3 穿孔卡片
- CPU利用率非常的低
- 好处是程序员可以一个人独占计算机,想干嘛就干嘛
1.4 联机批处理系统
- 缩短录入数据的时候,让CPU连续工作的时间变长>:提升CPU利用率
1.5 脱节批处理系统
- 是现代计算机的雏形>:提升CPU利用率
1.6 总结
- 操作系统的发展史也可以看成史CPU利用率提升的发展史
2. 多道技术
2.1 前提
- 一个核心/一个CPU/一个真正干活的
2.2 单道技术
- 所有的程序排队执行,总耗时是所有程序耗时之和
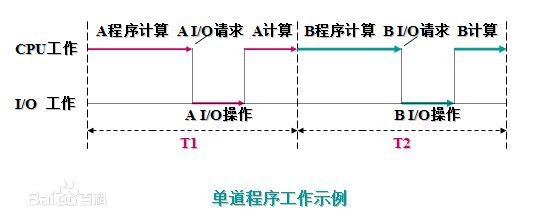
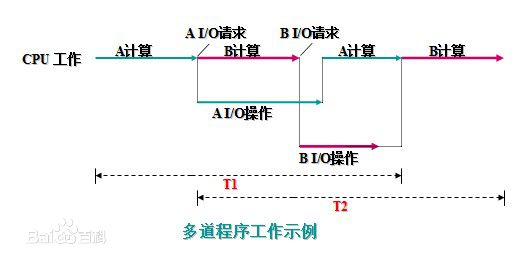
2.3 多道技术
- 计算机利用空闲时间提前准备好一些数据,提高效率,总耗时短
- 切换+保存状态
1. CPU在两种下会切换(去执行其他程序)
1.程序自身进入IO操作
IO操作:输入输出操作
获取用户输入
time.sleep()
读取文件
保存文件
2.程序长时间占用CPU
2. 保存状态
每次切换之前要记录下当前执行的状态,之后切回来基于当前状态继续执行
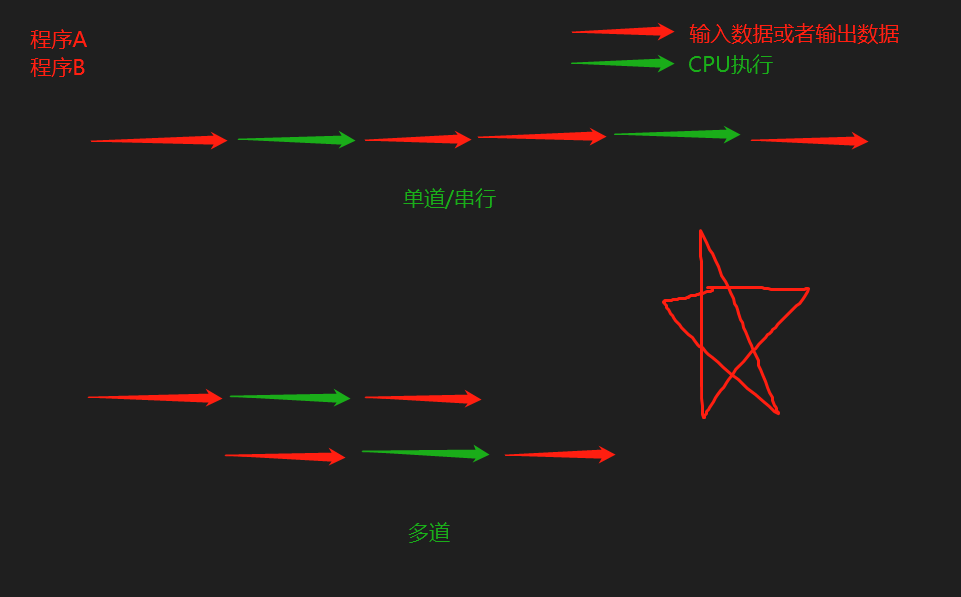
2.4 理解
- 做饭耗时50min,洗衣耗时30min,烧水耗时10min
- 单道技术:50+30+10
- 多道技术:50
3.进程简介
3.1 如何理解进程
- 程序:一堆躺在文件上的死代码
- 进程:正在被运行的程序(活的)
3.2 进程的调度算法
3.2.1 先来先服务算法
- 针对耗时比较短的程序不太友好
3.2.2 短作业优先调度
- 针对耗时比较长的程度不友好
3.2.3 时间片轮转法+多级反馈队列
- 将固定的时间均分成很多分,所有的程序来了都公平的分一份
- 分配多次之后如果还有程序需要运行,则将其分到下一层
- 越往下表示程序总耗时越长,每次分的时间片越多,但是优先级越低
3.3 进程的并行与并发
3.3.1 并行
- 多个进程同时执行,单个CPU肯定无法实现并行,必须要有多个CPU
3.3.1 并发
- 多个进程看上去像同时执行就可以称之为并发
- 单个CPU完成可以实现并发的效果,如果是并行那么肯定也是属于并发
3.3.2 描述一个网址非常牛逼能够同时服务很多人的话术
- 我这个网站很牛逼,能够支持14亿并行量(高并行)>>不合理,哪有那么多CPU(集群也不现实)
- 我这个网站很牛逼,能够支持14亿并发量(高并发)>> 非常合理,国内最牛逼的网站>>: 12306
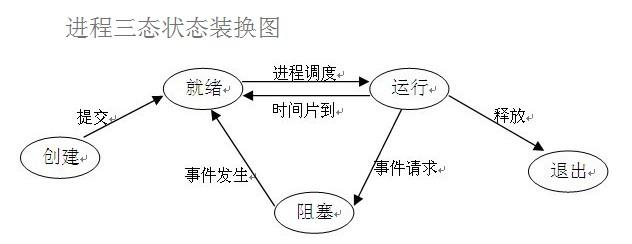
3.4 进程三状态
- 所有的进程想要被运行,必须先经过就绪态
- 运行过程中如果出现了IO操作,则进入阻塞态
- 运行过程中如果时间片用完,则继续进入就绪态
- 阻塞态相要进入运行态必须先经过就绪态
3.5 同步和异步
- 用于描述任务的提交状态
- 同步:提交完任务之后原地等待任务的结果,期间不做任何事
- 异步:提交完任务之后不原地等待直接去做其他事,结果自动提醒
3.6 阻塞与非阻塞
- 用于描述进程的执行状态
- 阻塞:阻塞态
- 非阻塞:就绪态,运行态
3.7 同步异步与阻塞非阻塞
- 同步阻塞:在银行排队,并且在队伍中什么事情都不做
- 同步非阻塞:在银行排队,并且在队伍中做点其他事
- 异步阻塞:取号,在旁边座位上等着叫号,期间不做事
- 异步非阻塞:取号,在旁边座位上等着叫号,期间为所欲为
4. 进程运用
4.1 创建进程的多种方式
4.1.1 双击桌面程序图标
4.1.2 代码创建进程
- 创建进程的代码在不同的操作系统中,底层原理有区别,在windows中创建进程类似于导入模块,if name == 'main': 启动脚本。在mac,liunx中,创建进程类似于直接拷贝,不需要启动脚本,但是为了兼容性 也可以使用
- 代码案例
# 1. 方式一
from multiprocessing import Process
import time
def task(name):
print(f'{name}正在运行')
time.sleep(3)
print(f'{name}运行结束')
if __name__ == '__main__':
p = Process(target=task, args=('jason',)) # 创建一个进程对象
# p.start() # 告诉操作系统创建一个进程(异步操作)
task('jason') # 普通的函数调用是同步操作
print('主进程')
# 2. 方式二
class MyProcess(Process):
def __init__(self,name):
super().__init__()
self.name = name
def run(self):
print(f'{self.name}正在运行')
time.sleep(3)
print(f'{self.name}运行结束')
if __name__ == '__main__':
obj = MyProcess('jason')
obj.start()
print('主进程')
4.2 join方法
4.2.1 定义
- jion:主进程等待子进程运行之后在运行
4.2.2 代码案例
# 1. 注意start 和 join 位置,位置不同结果不同
import time
from multiprocessing import Process
def task(name, n):
print(f'{name}正在运行')
time.sleep(n)
print(f'{name}运行结束')
if __name__ == '__main__':
p1 = Process(target=task, args=('jason', 1)) # args就是通过元组的形式给函数传参
p2 = Process(target=task, args=('jason', 2)) # 可以通过kwargs={'name':'jason', 'n':1} 太麻烦 没必要
p3 = Process(target=task, args=('jason', 3))
start_time = time.time()
p1.start()
p1.join()
p2.start()
p2.join()
p3.start()
p3.join()
# p1.start()
# p1.join()
# p2.start()
# p2.join()
# p3.start()
# p3.join()
end_time = time.time() - start_time
print('总耗时:%s' % end_time)
print('主进程')
4.3 进程间数据默认隔离
4.3.1 本质
- 多个进程数据彼此之间默认是相互隔离的,如果真的想要交互,需要借助于'管道'或者'队列'
- 代码案例
from multiprocessing import Process
money = 100
def task():
global money
money = 666
print('子进程打印的money', money)
if __name__ == '__main__':
p = Process(target=task)
p.start()
p.join()
print('父进程打印的money', money)
4.4 进程间通信(IPC机制)
4.4.1 队列运用
- 什么是队列 :先进先出
- 创建队列对象:
# 1.创建队列对象
q = Queue(3) # 括号内指定队列可以容纳的数据个数 默认:2147483647
- 往队列添加数据
# 2.往队列添加数据
q.put(11)
print(q.full()) # 判断队列是否已经存满
q.put(22)
q.put(33)
print(q.full())
q.put(44) # 超出数据存放极限,那么程序一致处于阻塞态,直到队列中有数据被取出
- 从队列中取数据
print(q.get_nowait())
print(q.get_nowait())
print(q.get_nowait()) # 队列中如果没用数据可取,直接报错
print(q.get())
print(q.empty()) # 判断队列是否已经空了
print(q.get())
print(q.get())
print(q.empty())
print(q.get()) # 超出数据获取极限 那么程序一致处于阻塞态 直到队列中有数据被添加
# q.full(),q.empty(),q.get_nowait()在多进程下不能准确使用(失效)
4.4.2 IPC机制
- 主进程与子进程通信
- 子进程与子进程通信
- 代码实例
from multiprocessing import Queue, Process
def procedure(q):
q.put('子进程procedure往队里中添加了数据')
def consumer(q):
print('子进程的consumer从队列中获取数据', q.get())
if __name__ == '__main__':
q = Queue() # 在主进程中产生q对象 确保所有的子进程使用的是相同的q
p1 = Process(target=procedure, args=(q,))
p2 = Process(target=consumer, args=(q,))
p1.start()
p2.start()
print('主进程')
4.6 进程相关方法
4.6.1 相关方法
- 查看进程号
# 1.查看进程号
from multiprocessing import current_process
import os
current_process().pid
os.getpid()
os.getppid()
print(os.getpid()) # 获取当前进程的进程号
print(os.getppid()) # 获取父进程的进程号
- 销毁子进程
p1.terminate()
- 判断进程是否存活
p1.is_alive()
4.6.2 守护进程
- 本质:伴随着守护对象的存活而存活,死亡而死亡
- 代码实例
from multiprocessing import Process
import time
def task(name):
print('a:%s存活' % name)
time.sleep(3)
print('a:%s嗝屁' % name)
if __name__ == '__main__':
p = Process(target=task, args=('基佬',))
# p.daemon = True # 将子进程设置为守护进程:主进程代码结束 子进程立刻结束
p.daemon = True # 必须在start之前执行
p.start()
print('天子Jason寿终正寝')
4.6.3 生产者消费者模型
- 生产者: 产生数据
- 消费者: 处理数据
- 完成的生产者消费者模型至少有三个部分
1. 生产者
2. 消息队列/数据库
3. 消费者
4.6.4 僵尸进程与孤儿进程
- 僵尸进程 :进程已经运行结束,但是相关的资料并吗,没用完全清空,需要父进程参与回收
- 孤儿进程 :父进程意外死亡,子进程正常运行,该子进程就称之为孤儿进程。孤儿进程也不是没有人管,操作系统会自动分配福利院接受。
4.7 将TCP服务端制作成并发效果
4.7.1 方式一:将数据交互代码封装成函数循环
# 1. 服务端
import socket
from multiprocessing import Process
# 数据交互的封装成函数
def talk(sock):
while True:
data = sock.recv(1024)
print(data.decode('utf8'))
sock.send(data.upper())
if __name__ == '__main__':
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen(5)
while True:
sock, addr = server.accept()
# 开设进程去完成数据交互
p = Process(target=talk, args=(sock,))
p.start()
# 客户端
import socket
client = socket.socket()
client.connect(('127.0.0.1', 8080))
while True:
client.send(b'hello baby')
data = client.recv(1024)
print(data.decode('utf8'))
4.7.2 方式二:把服务端对象封装成函数
import socket
from multiprocessing import Process
# 方式2 服务端对象的函数
def get_server():
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen(5)
return server
# 数据交互的封装成函数
def talk(sock):
while True:
data = sock.recv(1024)
print(data.decode('utf8'))
sock.send(data.upper())
if __name__ == '__main__':
# server = socket.socket()
# server.bind(('127.0.0.1', 8080))
# server.listen(5)
server = get_server()
while True:
sock, addr = server.accept()
# 开设进程去完成数据交互
p = Process(target=talk, args=(sock,))
p.start()
5. 互斥锁
5.1 理解
- 多个程序同时操作一份数据的时候很容易产生数据错乱,为了避免数据错乱,我们需要互斥锁
- 将并发变成串行,虽然牺牲了程序的执行效率但是保证了数据安全
5.2 强调
- 互斥锁只应该出现在多个程序操作数据的地方,其他位置尽量不要加
5.3 相关知识
- 行锁:只针对当前操作的行加锁。行级锁能减少数据库操作的冲突。加锁粒度最小,但加锁的开销也最大。有可能会出现死锁的情况。行级锁按照使用方式分为共享锁和排他锁。
- 表锁:只针对当前的操作对整张表加锁,资源开销比行锁少,不会出现死锁的情况,但是发生锁冲突的概率很大。
- 乐观锁:乐观锁就是持比较乐观态度的锁。就是在操作数据时非常乐观,认为别的线程不会同时修改数据,所以不会上锁,但是在更新的时候会判断在此期间别的线程有没有更新过这个数据。
- 悲观锁:悲观锁就是持悲观态度的锁。就在操作数据时比较悲观,每次去拿数据的时候认为别的线程也会同时修改数据,所以每次在拿数据的时候都会上锁,这样别的线程想拿到这个数据就会阻塞直到它拿到锁。
6. 线程
6.1 理解
- 进程是资源单位:进程相当于是车间,进程负责给内部的线程提供相应的资源
- 线程是执行单位:线程相当于是车间的流水线,线程负责执行真正的功能
6.2 特征
- 一个进程至少含有一个线程
- 同一个进程下多个线程之间资源共享
- 多进程与多线程的区别
多进程:需要申请内存空间,需要拷贝全部代码,资源消耗大
多线程:不需要申请内存空间,也不需要拷贝全部代码,资源消耗小
6.3 创建线程的两种方式
- 开设线程不需要完整拷贝代码,所以无论什么系统都不会出现反复操作的情况,也不需要在启动脚本中执行,但是为了兼容性和统一性,习惯在启动脚本中编写
- 代码实例
# 方式一:封装函数
from threading import Thread
import time
def task(name):
print(f'{name}正在运行')
time.sleep(3)
print(f'{name}运行结束')
t = Thread(target=task, args=('jason',))
t.start()
print('主线程')
if __name__ == '__main__':
t = Thread(target=task, args=('jason',))
t.start()
print('主线程')
# 方式二:继承类
from threading import Thread
import time
class MyThread(Thread):
def __init__(self, name):
super().__init__()
self.name = name
def run(self):
print(f'{self.name}正在运行')
time.sleep(3)
print(f'{self.name}运行结束')
obj = MyThread('jason')
obj.start()
print('主线程')
6.4 join
- 定义:主线程等到子线程运行结束之后再运行
- 代码实例
# 主线程等到子线程运行结束之后再运行
from threading import Thread
import time
def task():
print('正在执行')
time.sleep(3)
print('运行结束')
t = Thread(target=task)
t.start()
t.join()
print('主线程')
6.5 同一个进程下线程间的数据共享
from threading import Thread
money = 1000
def func():
global money
money = 666
t = Thread(target=func)
t.start()
t.join() # 确保线程运行完毕 再查找money 结果更具有说服性
print(money)
6.6 线程对象相关方法
6.6.1 进程号
- 同一个进程下开设的多个线程拥有相同的进程号
6.6.2 线程名
from threading import Thread,current_thread
current_thread().name
主:MainThread 子:Thread-N
6.6.3 进程下的线程数
active_count()
6.7 守护线程
6.7.1 定义
- 守护线程伴随着被守护的线程的结束而结束
- 进程下所有的非守护线程结束,主线程(主进程)才能真正的结束
6.7.2 代码实例
from threading import Thread
import time
def task():
print('子线程运行task函数')
time.sleep(3)
print('子线程运行task结束')
t = Thread(target=task)
# t.daemon = True
t.start()
# t.daemon = True
print('主线程')
10. GIL全局解释器锁
10.1 理解
- python解释器也是由编程语言写出来的,Cpython-用c写出来的,Jpython-用Java写出来的,Pypython 用python写出来的,最常见的就是Cpython(默认)
10.2 官方文档对GIL的解释
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.)
- GIL的研究是Cpython解释器的特点,不是python语言的特点
- GIL本质也是一把互斥锁
- GIL的存在使得同一个进程下的多个线程无法同时执行(关键)<理解:单进程下的多线程无法利用多核优势,效率低>
- GIL的存在主要是因为Cpython解释器中垃圾回收机制不是线程安全的
10.3 图解
10.4 验证GIL的存在
10.4.1 同一个进程下的多个线程无法同时执行,单进程下的多线程无法利用多核优势,效率低
from threading import Thread
import time
money = 100
def task():
global money
tmp = money
time.sleep(0.1)
money = tmp - 1
t_list = []
for i in range(100):
t = Thread(target=task)
t.start()
t_list.append(t) # [线程1,线程2, 线程3 ...]
for t in t_list:
t.join()
# 等待所有的线程运行结束 查看money是多少
print(money)
10.4.2 针对不同的数据应该加不同的锁处理
'''GIL不会影响程序层面的数据也不会保证它的修改是安全的要想保证得自己加锁'''
from threading import Thread,Lock
import time
money = 100
mutex = Lock()
def task():
mutex.acquire()
global money
tmp = money
time.sleep(0.1)
money = tmp - 1
mutex.release()
t_list = []
for i in range(100):
t = Thread(target=task)
t.start()
t_list.append(t) # [线程1 线程2 线程3 ... 线程100]
for t in t_list:
t.join()
# 等待所有的线程运行结束 查看money是多少
print(money)
11. 验证python多线程是否有用
| 程序 | 单个CPU,IO密集型 | 单个CPU 计算机密集 |
|---|---|---|
| 多线程 | 申请额外的空间,消耗更多的资源 | 申请额外的空间,消耗更多的资源(总耗时+申请空间+拷贝代码+切换) |
| 多进程 | 消耗资源相对较少,通过多道技术 | 消耗资源相对较少,通过多道技术(总耗时+切换) |
| 总结 | 多线程有优势 | 多线程有优势 |
| 程序 | 多个CPU IO密集型 | 多个CPU 计算机密集 |
|---|---|---|
| 多进程 | 总耗时(单个进程的耗时+IO+申请空间+拷贝代码) | 总耗时(单个进程的耗时) |
| 多线程 | 总耗时(单个进程的耗时+IO) | 总耗时(多个进程的综合) |
| 总结 | 多线程有优势 | 多进程完胜 |
12. 死锁,信号量,event事件,池
12.1 死锁现象
12.1.1 定义
- 是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程
12.1.2 代码案例
from threading import Thread, Lock
import time
mutexA = Lock() # 类名加括号每执行一次就会产生一个新的对象
mutexB = Lock() # 类名加括号每执行一次就会产生一个新的对象
class MyThread(Thread):
def run(self):
self.func1()
self.func2()
def func1(self):
mutexA.acquire()
print(f'{self.name}抢到了A锁')
mutexB.acquire()
print(f'{self.name}抢到了B锁')
mutexB.release()
print(f'{self.name}释放了B锁')
mutexA.release()
print(f'{self.name}释放了A锁')
def func2(self):
mutexB.acquire()
print(f'{self.name}抢到了B锁')
time.sleep(1)
mutexA.acquire()
print(f'{self.name}抢到了A锁')
mutexA.release()
print(f'{self.name}释放了A锁')
mutexB.release()
print(f'{self.name}释放了B锁')
for i in range(10):
t = MyThread()
t.start()
12.2 信号量
12.2.1 本质
- 信号量的本质也是互斥锁,只不过它是多把锁
12.2.2 信号量在不同的知识体系中,意思可能有区别
- 在并发编程中,信号量就是多把互斥锁
- 在django中,信号量指的是达到某个条件自动触发(中间件)
12.2.3 对比
- Lock产生的是单把锁,类似于单间厕所
- 信号量相当于一次性创建多间厕所,类似于公共厕所
12.2.4 代码案例
from threading import Thread, Lock, Semaphore
import time
import random
sp = Semaphore(5) # 一次性产生五把锁
class MyThread(Thread):
def run(self):
sp.acquire()
print(self.name)
time.sleep(random.randint(1, 3))
sp.release()
for i in range(20):
t = MyThread()
t.start()
12.3 event事件
12.3.1 定义
- 子进程\子线程(程序)之间可以彼此等待彼此(子A运行到某一个代码位置后发信号告诉子B开始运行)
12.3.2 代码案例
from threading import Thread, Event
import time
event = Event() # 类似于造了一个红绿灯
def light():
print('红灯亮着的 所有人都不能动')
time.sleep(3)
print('绿灯亮了 油门踩到底 给我冲!!!')
event.set()
def car(name):
print('%s正在等红灯' % name)
event.wait()
print('%s加油门 飙车了' % name)
t = Thread(target=light)
t.start()
for i in range(5):
t = Thread(target=car, args=('熊猫PRO%s' % i,))
t.start()
12.4 池
12.4.1 判断
- 多进程,多线程在实际应用中是不是可以无限制的开进程和线程。
肯定不可以,会造成内存溢出受限于硬件水平,我们在开设多进程或者多线程的时候,还需要考虑硬件的承受范围
12.4.2 定义
- 池:降低程序的执行效率,保证计算机硬件的安全
- 进程池:提前创建好固定个数的进程供程序使用,后续不会再创建
- 线程池:提前创建好固定个数的线程供程序使用,后续不会再创建
12.4.3 线程池
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
from threading import current_thread
import time
pool = ThreadPoolExecutor(5) # 固定产生五个线程
def task(n):
print(current_thread().name)
# print(n)
time.sleep(1)
return '返回的结果'
def func(*args, **kwargs):
print('func', args, kwargs)
print(args[0].result())
for i in range(10):
# res = pool.submit(task,123) # 朝池子中提交任务(异步)
# print(res.result()) # 同步操作
pool.submit(task, 123).add_done_callback(func)
"""异步回调:异步任务执行完成后有结果就会自动触发该机制"""
12.4.4 进程池
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
from threading import current_thread
import os
import time
# pool = ThreadPoolExecutor(5) # 固定产生五个线程
pool = ProcessPoolExecutor(5) # 固定产生五个进程
def task(n):
# print(current_thread().name)
print(os.getpid()) # 进程号
# print(n)
time.sleep(1)
return '返回的结果'
def func(*args, **kwargs):
print('func', args, kwargs)
print(args[0].result())
if __name__ == '__main__':
for i in range(20):
# res = pool.submit(task,123) # 朝池子中提交任务(异步)
# print(res.result()) # 同步操作
pool.submit(task, 123).add_done_callback(func)
"""异步回调:异步任务执行完成后有结果就会自动触发该机制"""
13. 协程
13.1 本质
- 进程:资源单位
- 线程:执行单位
- 协程:单线程下实现并发(效率极高)
在代码层面欺骗CPU,让CPU觉得我们的代码里面没有IO操作,实际上IO操作被我们自己写的代码检测,一旦有,立刻让代码执行别的(该技术完全是程序员自己弄出来的,名字也是程序员自己起的,核心:自己写代码完成切换+保存状态)
13.2 协程实现TCP服务端并发
# 服务端代码
import socket
from gevent import monkey;monkey.patch_all()
from gevent import spawn
def communication(sock):
while True:
data = sock.recv(1024)
print(data.decode('utf8'))
sock.send(data.upper())
def get_server():
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen(5)
while True:
sock, addr = server.accept() # IO操作
spawn(communication, sock)
s1 = spawn(get_server)
s1.join()
# 客户端代码
import socket
from threading import Thread,current_thread
def get_client():
client = socket.socket()
client.connect(('127.0.0.1', 8080))
while True:
client.send(f'hello {current_thread().name}'.encode('utf8'))
data = client.recv(1024)
print(data.decode('utf8'))
for i in range(400):
t = Thread(target=get_client())
t.start()
14. 数据库简介
14.1 数据存取的演变史
| 发展史 | 理解 |
|---|---|
| 文本文件 | 1.文件路径不一致:C:\A.txt D:\A.txt 2.数据格式不一致:jason |
| 软件开发目录规范 | 1. 规定了数据文件的大致存储位置:db文件夹 2.针对数据格式还是没有完全统一:比如统一json文件但是内部键值对不同 |
| 数据库服务 | 1.统一了存取位置,也统一了数据格式(完全统一) |
14.2 数据库软件的应用史
14.2.1 理解
- 单机游戏:不同计算机上的想同程序,数据无法共享,数据库服务全部在本体完成
- 网络游戏:不同计算机上的相同程序,数据可以共享,数据库服务单独在网络架设(远程数据库服务)
14.3.2 远程数据库服务
- 数据库集群,让多台服务器运行相同的数据库服务
数据安全性问题
服务器负载问题
14.3 数据库的本质
14.3.1 数据库在不同角度下描述的意思不一样
- 站在底层原理的角度,数据库指的专用用于操作数据的进程,eg:运行在内存中的代码
- 站在现实应用的角度,数据库指的是拥有操作界面的应用程序,eg:用于操作进程的界面
14.3.2 理解
- 我们不做特殊说明的下提数据库其实都是在指数据库软件,我们也称数据库软件本质是一款cs架构的应用程序,言外之意所有的程序员理论上都可以编写:市面上已经有很多数据库软件
14.4 数据库分类
| 关系数据库 | 非关系数据库 |
|---|---|
| 1. 数据的组织方式有明确的表结构 2. 表里面有一些表的基本信息,关系型数据库存取数据的方式可以看成是表格 |
1. 数据的组织方式没有明确的表结构 2. 是以K:V健值对的形式组织的,{'name':'jason'}, |
| 1. 表与表之间可以建立数据库层面的关系 | 1. 数据之间无法直接建立数据库层面的关系 |
| 数据库软件:MySQL,PostgreSQL,MariaDB,Oracle,sqlite,db2,sql server | 数据库软件:redis,mongoDB,memcache |
| 1. MySQL:开源,使用最为广泛,数据库学习必学 2. PostgreSQL:开源 支持二次开发 3. MariaDB:开源 与MySQL是同一个作者,用法也极其相似 4. Oracle:收费,安全性极高,主要用于银行及各大重要机关 5. sqlite:小型数据库,主要用于本地测试(django框架自带该数据库) |
1. redis:目前最火,使用频率最高的缓存型数据库 2. mongoDB:稳定型数据库,最像关系型的非关系型,主要用于爬出,大数据memcache:已经被radis淘汰 |
15 MySQL简介
15.1 MySQL版本问题
- 5.6X:前几年使用频率最高的版本
- 5.7X:最近尝试迁移的版本(频率+)
- 8.0X:最新版,功能很强大,但是线上环境几乎不用(本地自己用非常好用)
虽然版本有区别,但是操作上几乎没有区别,主要体现在底层运作
15.2 下载与安装
- 访问官网
- 点击DOWNLOADS
- 点击GPL
- 点击communtiy server
- 点击archives
- 点击download
15.3 主要文件介绍
- bin文件夹 mysqld.exe服务端 mysql.exe客户端
- data文件夹 存取数据
- my-defult.ini 默认配置文件
15.4 基本使用
15.4.1 先启动服务端
- 可能会报错:拷贝关键信息去百度,两种报错
15.4.2 查找mysqld文件位置
- mysqld cmd窗口就是服务端,不用关闭
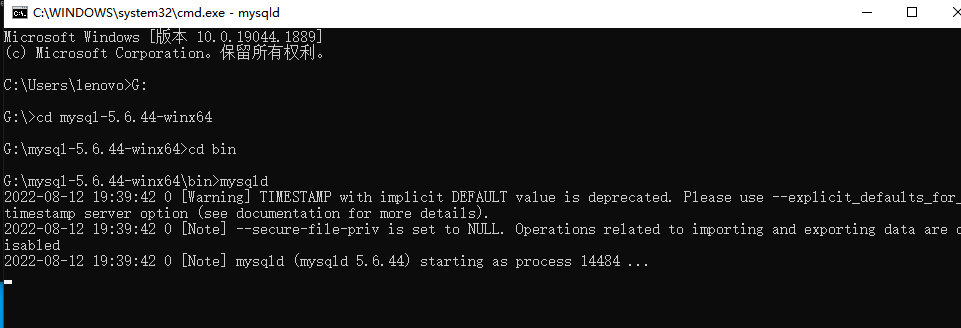
- 再次开启新的cmd窗口,mysql 直接回车会以游客模式进入,功能很少

- 游客模式和账户密码模式下的 show databases;
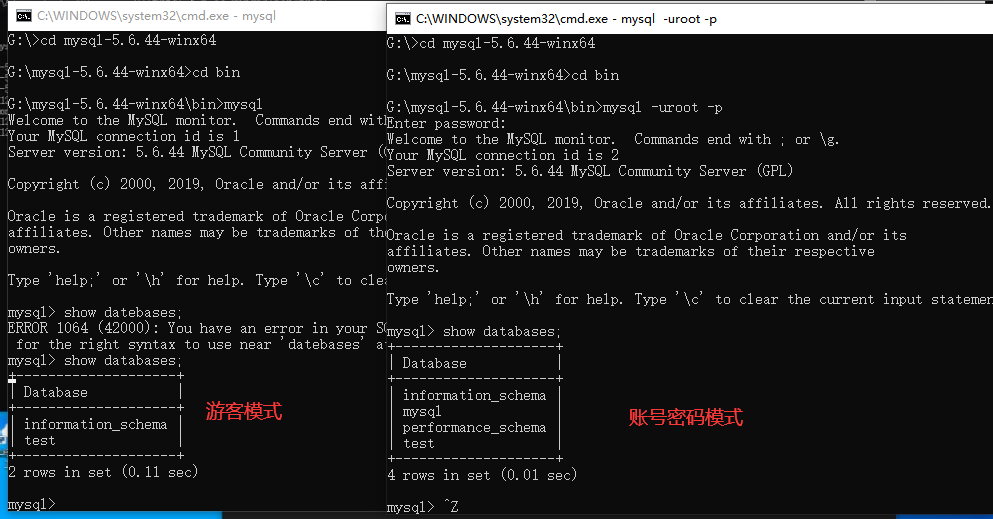
- 退出 exit和quit
15.5 系统服务制作
- 如何解决每次都需要切换路径查找文件的缺陷:添加环境变量
- 将mysql服务端作成系统服务
- 随着计算机的开启而启动,关闭而结束
- 以管理员身份打开cmd窗口
- 执行系统服务命令:mysqld --install
- 启动服务端
- 右键直接点击启动
- 命令启动 net start mysql
- 查看系统服务的命令:services.msc
- 关闭mysql服务端 net stop mysql
- 移除系统服务
- 先确保服务已经关闭
- 执行移除命令 mysqld --remove
15.6 修改密码
- 通用方式: # 直接在cmd中写 mysqladmin -u用户名 -p原密码 password 新密码
- 第一次修改:mysqladmin -uroot -p password 123
- 第二次修改:mysqladmin -uroot -p123 password 321
- 偏门方式(有些版本无法使用): # 需要先登录
set password=PASSWORD('新密码'); - 忘记密码
直接重装\拷贝对应文件
先关闭服务端 然后以不需要校验用户身份的方式启动 再修改 最后再安装正常方式启动
1.net stop mysql
2.mysqld --skip-grant-tables
3.mysql -uroot -p
4.update mysql.user set password=password(123) where Host='localhost' and User='root';
5.net stop mysql
6.net start mysql
15.7 SQL与NoSQL
- 数据库的服务端支持各种语言充当客户端
- MySQL客户端、python代码编写的客户端、java代码编写的客户端,为了能够兼容所有类型的客户端 有两种策略
- 服务端兼容:不合理 消耗数据库服务端资源
- 制定统一标准:SQL语句、NoSQL语句
- SQL与NoSQL
- SQL语句的意思是操作关系型数据库的语法
- NoSQL语句的意思操作非关系型数据库的语法
- SQL有时候也用来表示关系型数据库 NoSQL也用来表示非关系型数据库
15.8 针对库的基本SQL语句
1. SQL语句结束符是分号 ;
2. 取消SQL语句的执行 \c
3. 增 create database 库名;
4. 查
show databases;
show create database 库名;
3.改 alter database 库名 charset='gbk';
4.删 drop database 库名;
15.9 针对表的基本SQL语句
1.增
create table 表名(字段名 字段类型,字段名 字段类型,字段名 字段类型);
2.查
show tables;
show create table 表名;
describe 表名;
desc 表名;
3.改 alter table 旧表名 rename 新表名; # 改表名
4.删 drop table 表名;
15.10 针对记录的基本SQL语句
1.增
insert into 表名 values(数据,数据);
insert into 表名 values(数据,数据),(数据,数据),(数据,数据);
2.查
select * from 表名; # *表示查看所有字段
select 字段1,字段2 from 表名;
ps:如果表中字段较多出现了错乱 可以结尾写\G
3.改
update 表名 set 字段名=新数据 where 筛选条件;
4.删
delete from 表名; # 删除表中所有的数据
delete from 表名 where 筛选条件 # 按照条件删除数据


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)