

【并发编程】第2回 进程
1. 创建进程的多种方式
1.1 双击桌面程序图标
1.2 代码创建进程
- 创建进程的代码在不同的操作系统中,底层原理有区别,在windows中创建进程类似于导入模块,if name == 'main': 启动脚本。在mac,liunx中,创建进程类似于直接拷贝,不需要启动脚本,但是为了兼容性 也可以使用
1.2.1 方式1
- 代码编写
from multiprocessing import Process
import time
def task(name):
print(f'{name}正在运行')
time.sleep(3)
print(f'{name}运行结束')
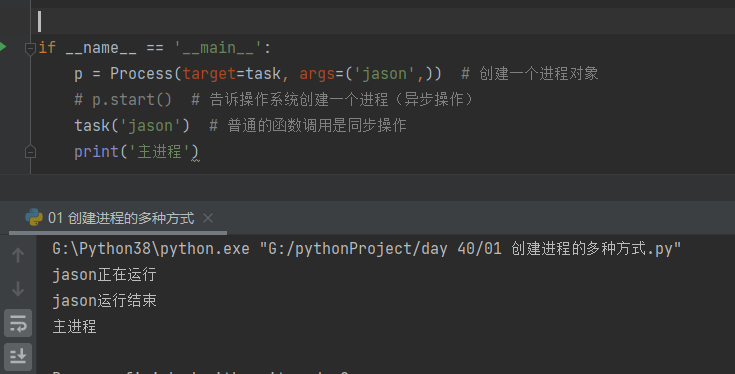
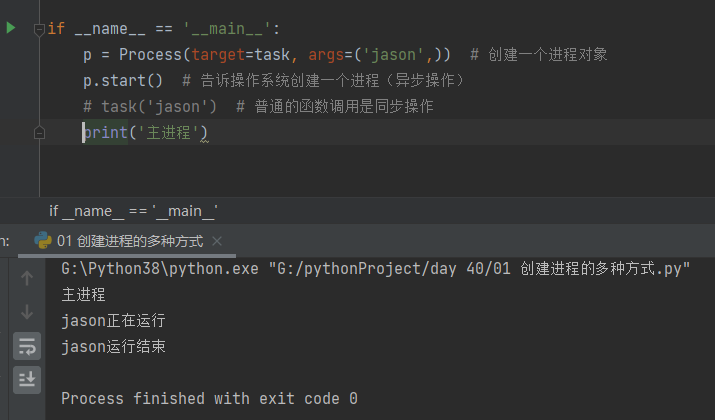
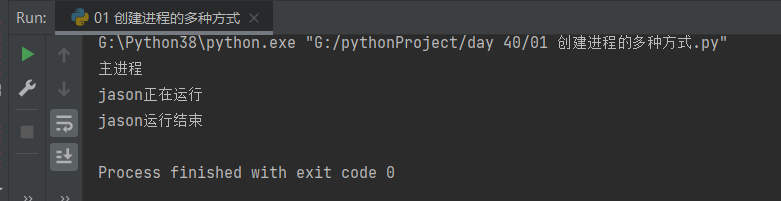
if __name__ == '__main__':
p = Process(target=task, args=('jason',)) # 创建一个进程对象
# p.start() # 告诉操作系统创建一个进程(异步操作)
task('jason') # 普通的函数调用是同步操作
print('主进程')
- 在task('jason') 情况下是普通的函数调用是同步操作先运行函数在运行主进程
- 在p.start()情况下,告诉操作系统创建一个进程(异步操作)先运行主进程在运行子进程
1.2.2 方式2
- 代码编写展示
class MyProcess(Process):
def __init__(self,name):
super().__init__()
self.name = name
def run(self):
print(f'{self.name}正在运行')
time.sleep(3)
print(f'{self.name}运行结束')
if __name__ == '__main__':
obj = MyProcess('jason')
obj.start()
print('主进程')
2. join方法
2.1 定义
- join:主进程等待子进程运行结束之后在运行
2.2 推导步骤1:直接在主进程代码中添加time.sleep()
- 不合理,因为无法准确把握子进程执行的时间
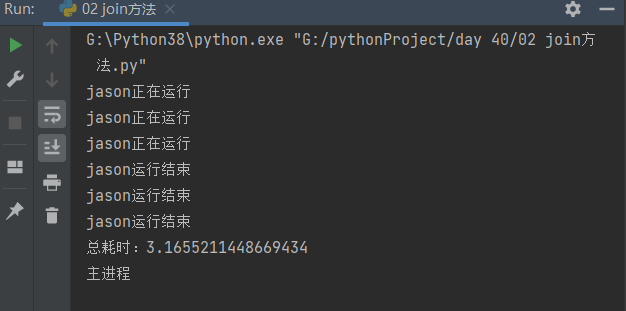
2.3 推导步骤2:join方法
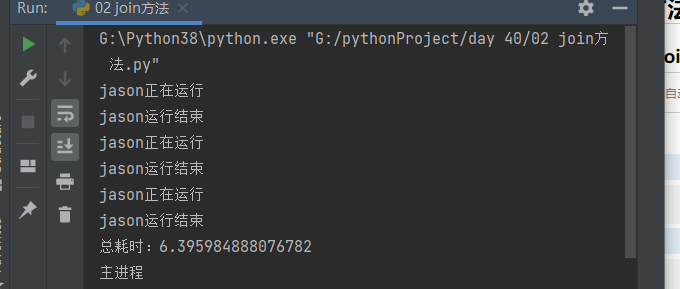
2.3.1 运行顺序p1.start(),p1.join()....
import time
from multiprocessing import Process
def task(name, n):
print(f'{name}正在运行')
time.sleep(n)
print(f'{name}运行结束')
if __name__ == '__main__':
p1 = Process(target=task, args=('jason', 1)) # args就是通过元组的形式给函数传参
p2 = Process(target=task, args=('jason', 2)) # 可以通过kwargs={'name':'jason', 'n':1} 太麻烦 没必要
p3 = Process(target=task, args=('jason', 3))
start_time = time.time()
p1.start()
p1.join()
p2.start()
p2.join()
p3.start()
p3.join()
end_time = time.time() - start_time
print('总耗时:%s' % end_time)
print('主进程')
2.3.2 运行顺序p1.start()...,p1.join()...
import time
from multiprocessing import Process
def task(name, n):
print(f'{name}正在运行')
time.sleep(n)
print(f'{name}运行结束')
if __name__ == '__main__':
p1 = Process(target=task, args=('jason', 1)) # args就是通过元组的形式给函数传参
p2 = Process(target=task, args=('jason', 2)) # 可以通过kwargs={'name':'jason', 'n':1} 太麻烦 没必要
p3 = Process(target=task, args=('jason', 3))
start_time = time.time()
p1.start()
p2.start()
p3.start()
p1.join()
p2.join()
p3.join()
end_time = time.time() - start_time
print('总耗时:%s' % end_time)
print('主进程')
3. 进程间数据默认隔离
3.1 本质
- 多个进程数据彼此之间默认是相互隔离的,如果真的想要交互,需要借助于'管道'或者'队列'
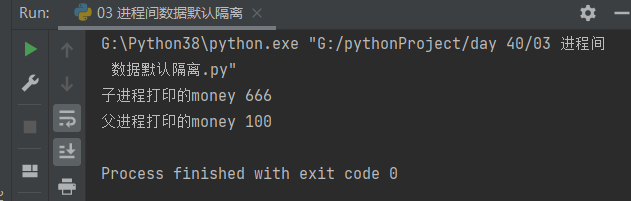
3.2 代码编写
from multiprocessing import Process
money = 100
def task():
global money
money = 666
print('子进程打印的money', money)
if __name__ == '__main__':
p = Process(target=task)
p.start()
p.join()
print('父进程打印的money', money)
4. 进程间通信(IPC机制)
4.1 预备知识
4.1.1 什么是队列:先进先出
4.1.2 创建队列对象
# 1.创建队列对象
q = Queue(3) # 括号内指定队列可以容纳的数据个数 默认:2147483647
4.1.3 往队列添加数据
# 2.往队列添加数据
q.put(11)
print(q.full()) # 判断队列是否已经存满
q.put(22)
q.put(33)
print(q.full())
q.put(44) # 超出数据存放极限,那么程序一致处于阻塞态,直到队列中有数据被取出
4.1.4 从队列中取数据
print(q.get_nowait())
print(q.get_nowait())
print(q.get_nowait()) # 队列中如果没用数据可取,直接报错
print(q.get())
print(q.empty()) # 判断队列是否已经空了
print(q.get())
print(q.get())
print(q.empty())
print(q.get()) # 超出数据获取极限 那么程序一致处于阻塞态 直到队列中有数据被添加
4.1.5 总结
- q.full(),q.empty(),q.get_nowait()在多进程下不能准确使用(失效)
4.2 IPC机制
- 主进程与子进程通信
- 子进程与子进程通信
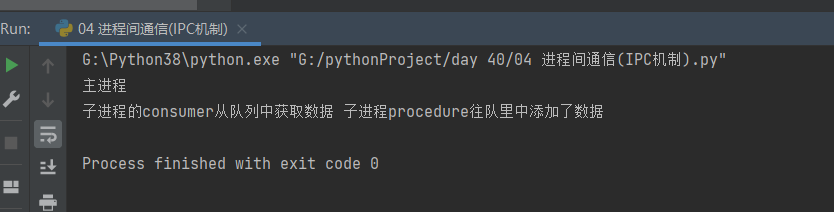
4.3 代码编写
from multiprocessing import Queue, Process
def procedure(q):
q.put('子进程procedure往队里中添加了数据')
def consumer(q):
print('子进程的consumer从队列中获取数据', q.get())
if __name__ == '__main__':
q = Queue() # 在主进程中产生q对象 确保所有的子进程使用的是相同的q
p1 = Process(target=procedure, args=(q,))
p2 = Process(target=consumer, args=(q,))
p1.start()
p2.start()
print('主进程')
5. 生产者消费者模型
5.1 生产者:产生数据
5.2 消费者:处理数据
5.3 理解
- 如爬取红牛分公司
- 生产者:获取网页数据的代码(函数) 爬
- 消费者:从网页数据中筛选出符合条件的数据(函数) 筛选
5.4 完成的生产者消费者模型至少有三个部分
- 生产者
- 消息队列/数据库
- 消费者
6. 进程相关方法
6.1 查看进程号
# 1.查看进程号
from multiprocessing import current_process
import os
current_process().pid
os.getpid()
os.getppid()
print(os.getpid()) # 获取当前进程的进程号
print(os.getppid()) # 获取父进程的进程号
6.2 销毁子进程
p1.terminate()
6.3 判断进程是否存活
p1.is_alive()
6.4 守护进程
6.4.1 如何理解守护
- 伴随着守护对象的存活而存活,死亡而死亡
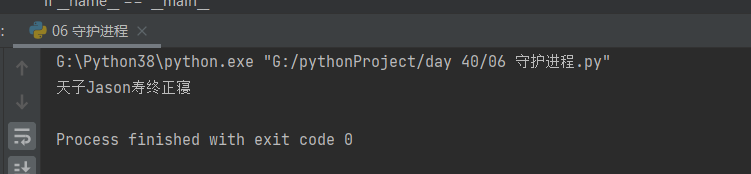
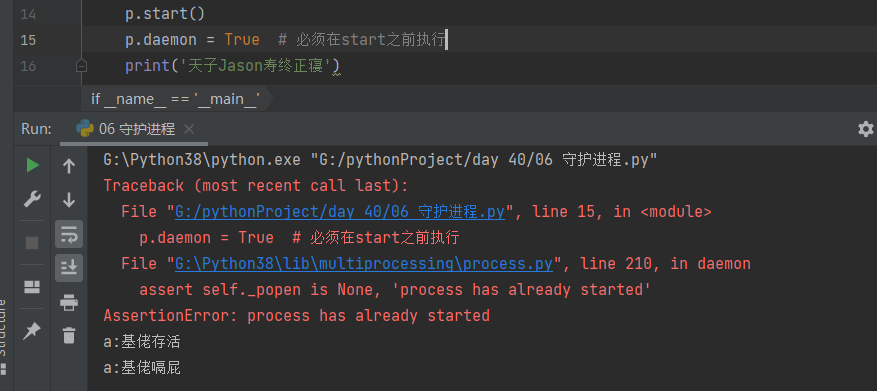
6.4.2 代码编写
- p.daemon = True 必须在start之前执行
from multiprocessing import Process
import time
def task(name):
print('a:%s存活' % name)
time.sleep(3)
print('a:%s嗝屁' % name)
if __name__ == '__main__':
p = Process(target=task, args=('基佬',))
# p.daemon = True # 将子进程设置为守护进程:主进程代码结束 子进程立刻结束
p.daemon = True # 必须在start之前执行
p.start()
print('天子Jason寿终正寝')
2. p.daemon = True 在start之后执行
7. 僵尸进程与孤儿进程
7.1 僵尸进程
- 进程已经运行结束,但是相关的资料并吗,没用完全清空,需要父进程参与回收
7.2 孤儿进程
- 父进程意外死亡,子进程正常运行,该子进程就称之为孤儿进程
- 孤儿进程也不是没有人管,操作系统会自动分配福利院接受
8. 互斥锁
模拟抢票
查票
买票
查票
买票
from multiprocessing import Process
import time
import json
import random
# 查票
def search(name):
with open(r'data.json', 'r', encoding='utf8') as f:
data = json.load(f)
print('%s在查票 当前余票为:%s' % (name, data.get('ticket_num')))
# 买票
def buy(name):
# 再次确认票
with open(r'data.json', 'r', encoding='utf8') as f:
data = json.load(f)
# 模拟网络延迟
time.sleep(random.randint(1, 3))
# 判断是否有票 有就买
if data.get('ticket_num') > 0:
data['ticket_num'] -= 1
with open(r'data.json', 'w', encoding='utf8') as f:
json.dump(data, f)
print('%s买票成功' % name)
else:
print('%s很倒霉 没有抢到票' % name)
def run(name):
search(name)
buy(name)
if __name__ == '__main__':
for i in range(10):
p = Process(target=run, args=('用户%s' % i,))
p.start()


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)