【python基础】第09回 数据类型内置方法 01
本章内容概要
1.数据类型的内置方法简介
2.整型相关方法
3.浮点型相关方法
4.字符串相关方法
5.列表相关方法
本章内容详情
1.数据类型的内置方法简介
数据类型是用来记录事物状态的,而事物的状态是不断变化的(如:一个人年龄的增长(操作int类型),单个人名的修改(操作str)类型,学生列表中增加学生(操作list类型)等),这意味着我们在开发程序时需要频繁对数据进行操作,为了提升我们的开发效率,python针对这些常用的操作,为每一种数据类型内置了一系列方法。
内置方法可以简单的理解成是每个数据类型自带的功能
使用数据类型的内置方法统一采用句号符
数据类型,方法名()
eg:
'zhang'.字符串具备的方法()
name = 'zhang'
name.字符串具备的方法()
ps:
如何快速查看某个数据类型的内置方法
借助于编辑器自动提示
我们在学习内置方法的过程中还会穿插一些其他用法
eg:
索引取值 按k取值
2.整型相关方法
2.1.关键字 int() 整型就是整数 主要用于计算 没有内置方法
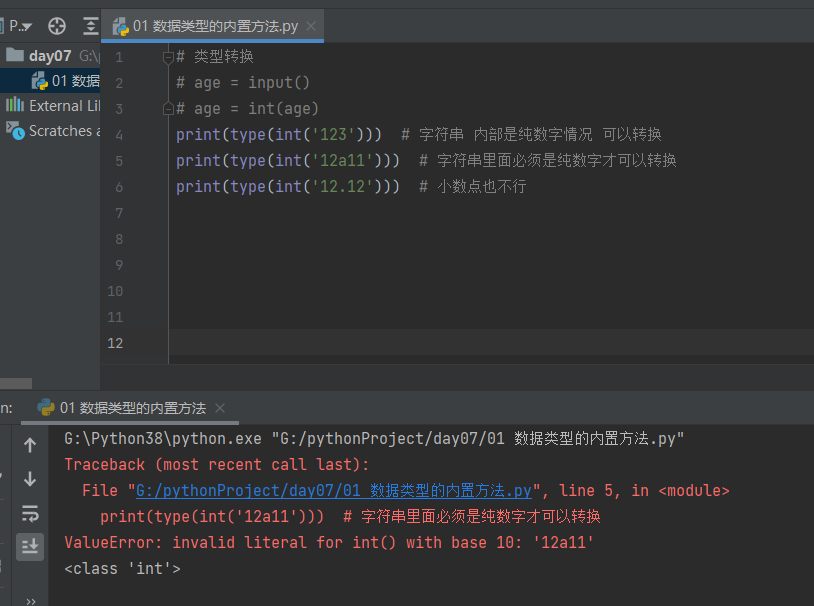
2.2类型转换 int(待转换的数据)
类型转换
print(type(int('123'))) # 字符串 内部是纯数字情况 可以转换 print(type(int('12a11'))) # 字符串里面必须是纯数字才可以转换 print(type(int('12.12'))) # 小数点也不行
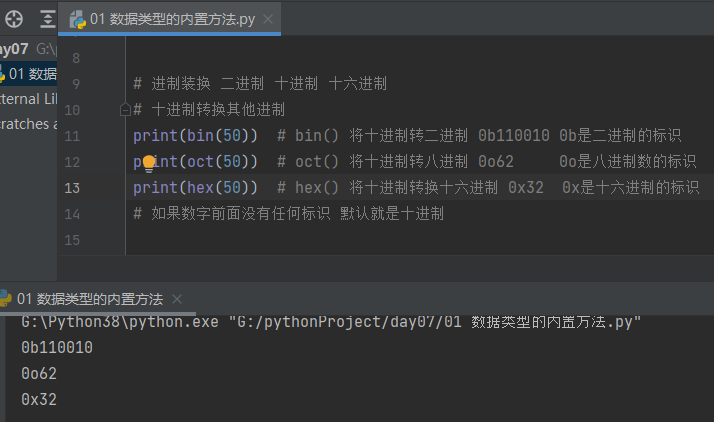
进制装换
# 进制装换 二进制 十进制 十六进制 # 十进制转换其他进制 print(bin(50)) # bin() 将十进制转二进制 0b110010 0b是二进制的标识 print(oct(50)) # oct() 将十进制转八进制 0o62 0o是八进制数的标识 print(hex(50)) # hex() 将十进制转换十六进制 0x32 0x是十六进制的标识 # 如果数字前面没有任何标识 默认就是十进制
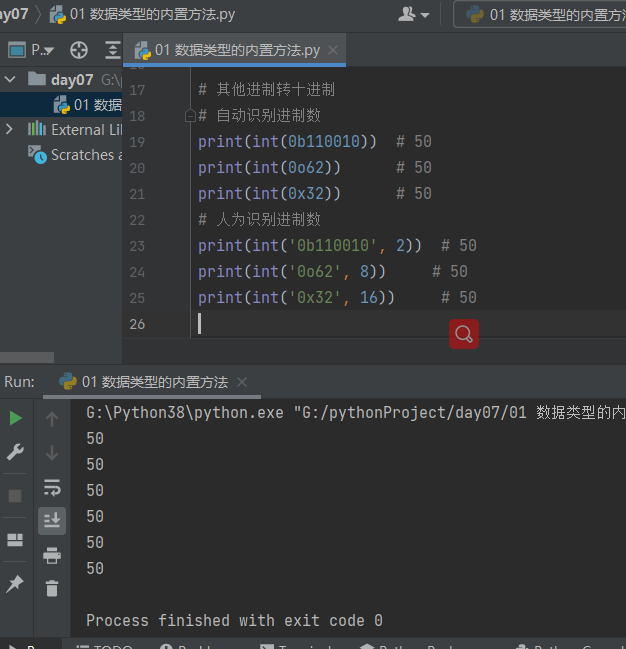
# 其他进制转十进制 # 自动识别进制数 print(int(0b110010)) # 50 print(int(0o62)) # 50 print(int(0x32)) # 50 # 人为识别进制数 print(int('0b110010', 2)) # 50 print(int('0o62', 8)) # 50 print(int('0x32', 16)) # 50
3.浮点型相关方法
3.1 关键字 float
3.2 类型转换
print(float('123')) # 123.0 print(type(float('123'))) # float
print(float('12.12')) # 只可以识别一个小数点 print(float('12a12')) # 不可以 print(float('12.12.12')) # 不可以
3.3 针对布尔值的特殊情况
没有特殊说明的情况下 1 对应 True 0 对应 Float
print(float(True)) # 1.0 print(float(False)) # 0.0 print(int(True)) # 1 print(int(False)) # 0
3.4 补充说明
a = 23.0 b = 1.2 c = a * b print(c) # 27.599999999999998

如图 结果为27.599999999999998 为什么呢?
python 对数字不敏感 很容易出错
那python 为什么还能做人工智能 数据分析 金融量化
是因为基于python开发的模块非常牛逼!!!
4.字符串相关方法
4.1 关键字 str
4.2 类型装换
# 类型转换:兼容所有数据值 print(str(123), type(str(123))) print(str(123.11), type(str(123.11))) print(str([1, 2, 3, 4]), type(str([1, 2, 3, 4]))) print(str({'name': 'jason'}), type(str({'name': 'jason'}))) print(str(True), type(str(True))) print(str((1, 2, 3, 4)), type(str((1, 2, 3, 4)))) print(str({1, 2, 3, 4}), type(str({1, 2, 3, 4})))
4.3 需要掌握的方法
4.3.1.1 索引取值:单个字符 支持负数
s1 = 'hello world'
# 1.索引取值:单个字符 支持负数
print(s1[0]) # h
print(s1[-1]) # d
print(s1[-2]) # l
4.3.1.2 切片取值:多个字符 支持负数 切片的顺序默认从左到右
print(s1[0:3]) # hel 从索引0的位置开始切到索引2的位置 顾头不顾尾 print(s1[-1:-3]) # 切片的顺序默认从左到右 所以返回为空 print(s1[-1:-3:-1]) # dl 可以通过第三个参数的正负一 控制方向 print(s1[-3:-1]) # rl 顾头不顾尾
4.3.1.3 间隔/方向
# 3.间隔/方向 print(s1[:]) # hello world 所以 print(s1[::]) # hello world 针对整个字符串 隔一个取一个 print(s1[0:5:1]) # hello 默认1可以不写 print(s1[0:5:2]) # hlo 间隔取一个
4.3.1.4 统计字符串中字符的个数 len
print(len(s1)) print(len('hello world')) # 可以看见字母只有十个 而结果是11 空格也算字符串
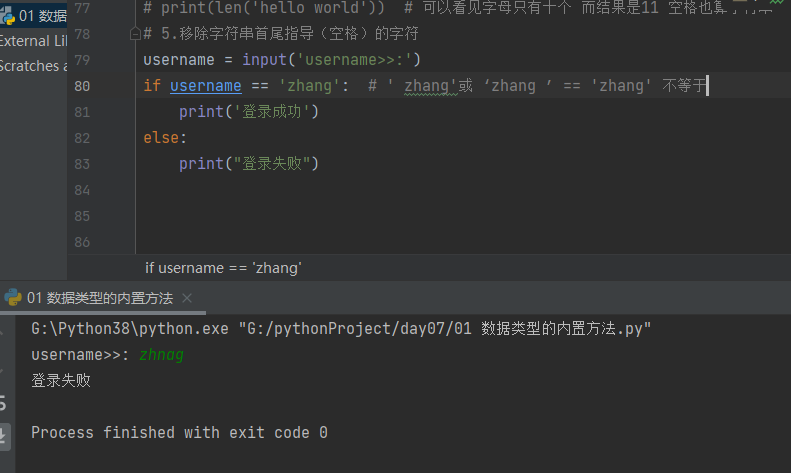
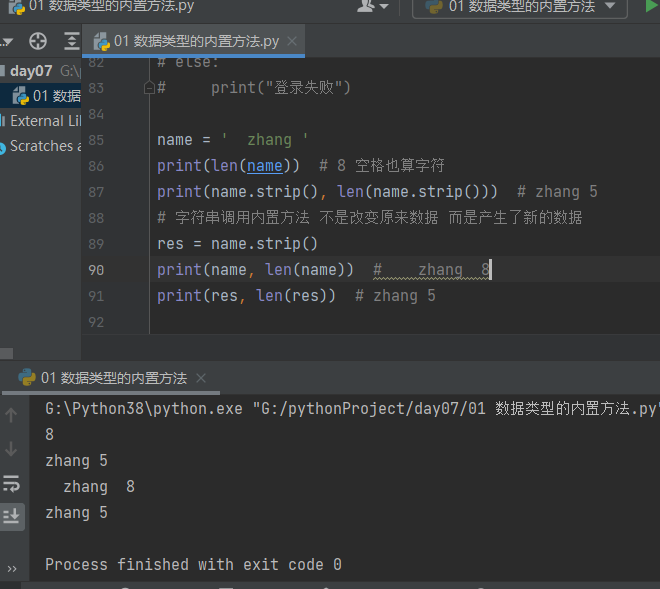
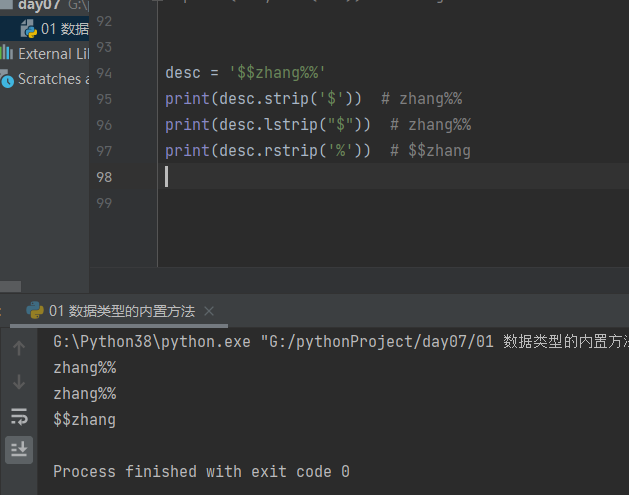
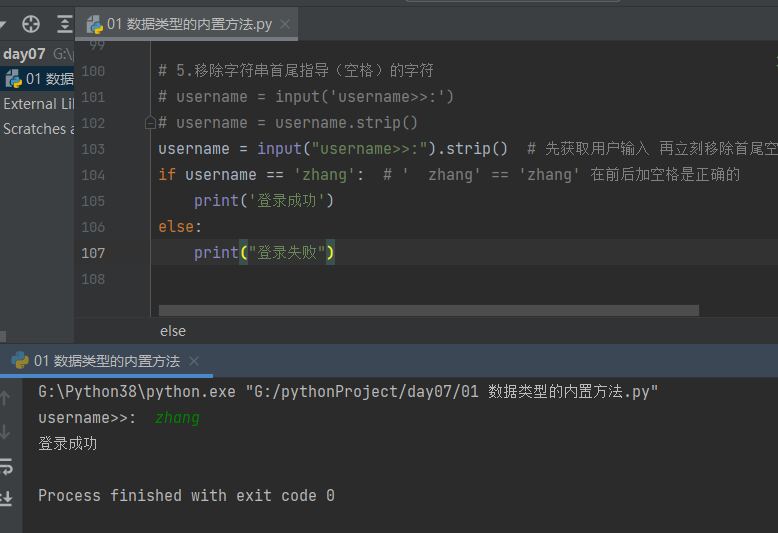
4.3.1.5 移除字符串首尾指导的字符 strip
# 5.移除字符串首尾指导(空格)的字符 中间不能 username = input('username>>:') if username == 'zhang': # ' zhang'或 ‘zhang ’ == 'zhang' 不等于 print('登录成功') else: print("登录失败")
name = ' zhang ' print(len(name)) # 8 空格也算字符 print(name.strip(), len(name.strip())) # zhang 5 # 字符串调用内置方法 不是改变原来数据 而是产生了新的数据 res = name.strip() print(name, len(name)) # zhang 8 print(res, len(res)) # zhang 5
desc = '$$zhang%%' print(desc.strip('$')) # zhang%% print(desc.lstrip("$")) # zhang%% left print(desc.rstrip('%')) # $$zhang right
# 5.移除字符串首尾指导(空格)的字符 # username = input('username>>:') # username = username.strip() username = input("username>>:").strip() # 先获取用户输入 再立刻移除首尾空格 最后绑定给变量名username if username == 'zhang': # ' zhang' == 'zhang' 在前后加空格是正确的 print('登录成功') else: print("登录失败")
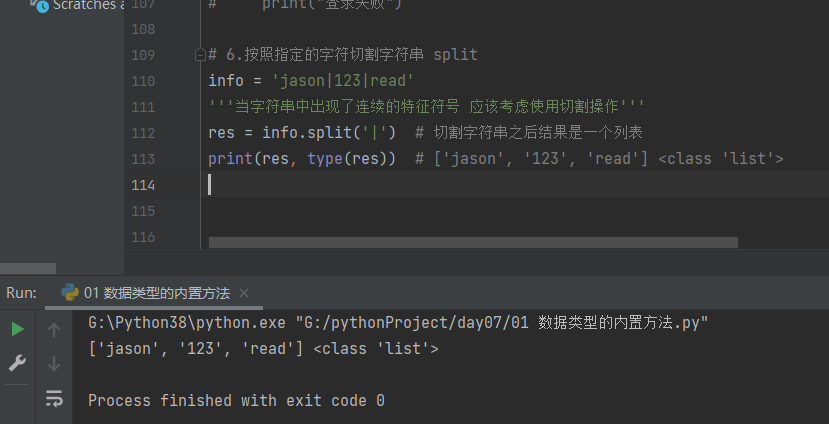
4.3.1.6 按照指定的字符切割字符串 split
# 6.按照指定的字符切割字符串 split info = 'jason|123|read' '''当字符串中出现了连续的特征符号 应该考虑使用切割操作''' res = info.split('|') # 切割字符串之后结果是一个列表 print(res, type(res)) # ['jason', '123', 'read'] <class 'list'>
name, pwd, hobby = info.split('|') # 等价于 name, pwd, hobby = ['jason', '123', 'read']
print(info.split('|', maxsplit=1)) # 从左往右 只切一次 ['jason', '123|read'] print(info.rsplit('|', maxsplit=1)) # 从右往左 只切一次 ['jason|123', 'read']

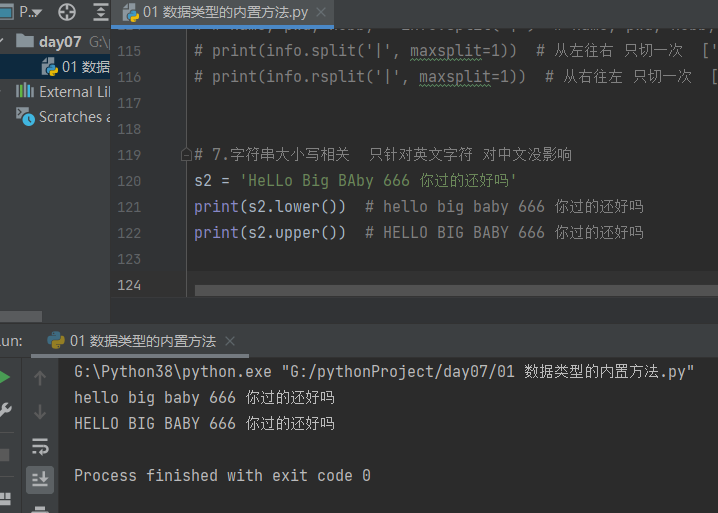
4.3.1.7 字符串大小写相关 lower 小写 upper 大写
# 7.字符串大小写相关 只针对英文字符 对中文没影响 s2 = 'HeLLo Big BAby 666 你过的还好吗' print(s2.lower()) # hello big baby 666 你过的还好吗 print(s2.upper()) # HELLO BIG BABY 666 你过的还好吗
print(s2.islower()) # 判断字符串中所有的字母是否是全小写 False print(s2.isupper()) # 判断字符串中所有的字母是否是全大写 False print('aaa'.islower()) # True print('AAA'.isupper()) # True

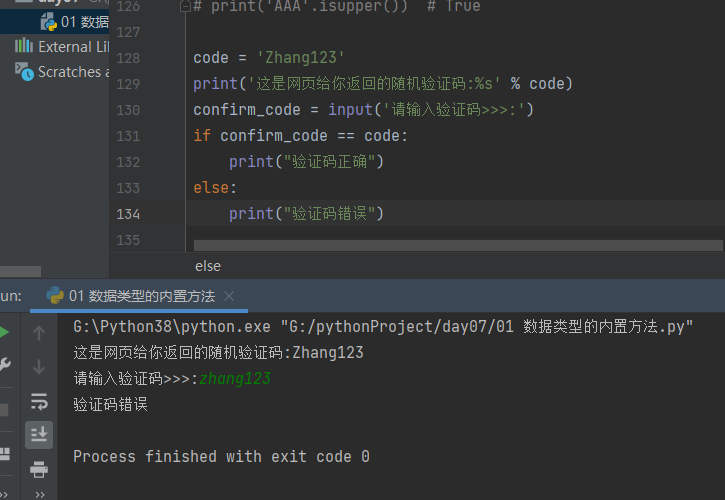
验证码例子:
看结果可知,输入的必须和提示的大小写字母一样才会正确,否则是错的
code = 'Zhang123' print('这是网页给你返回的随机验证码:%s' % code) confirm_code = input('请输入验证码>>>:') if confirm_code == code: print("验证码正确") else: print("验证码错误")
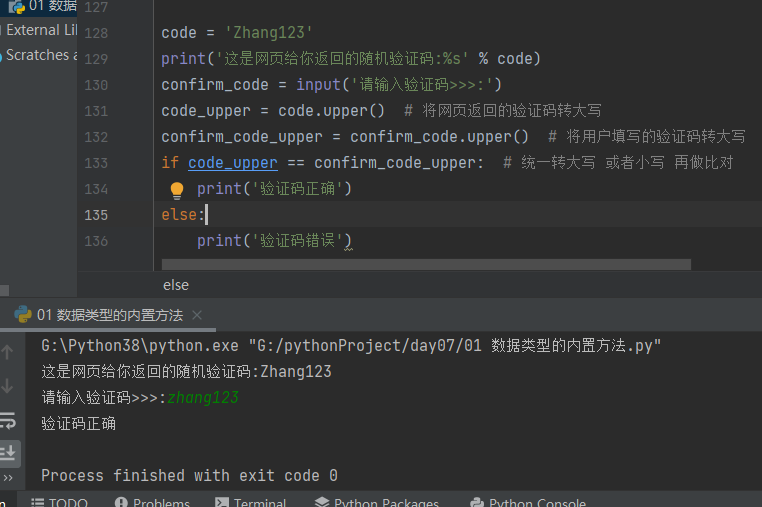
code = 'Zhang123' print('这是网页给你返回的随机验证码:%s' % code) confirm_code = input('请输入验证码>>>:') code_upper = code.upper() # 将网页返回的验证码转大写 confirm_code_upper = confirm_code.upper() # 将用户填写的验证码转大写 if code_upper == confirm_code_upper: # 统一转大写 或者小写 再做比对 print('验证码正确') else: print('验证码错误')
精简代码
code = 'Zhang123' print('这是网页给你返回的随机验证码:%s' % code) confirm_code = input('请输入验证码>>>:') # code_upper = code.upper() # 将网页返回的验证码转大写 # confirm_code_upper = confirm_code.upper() # 将用户填写的验证码转大写 # if code_upper == confirm_code_upper: # 统一转大写 或者小写 再做比对 if confirm_code.upper() == code.upper(): # 统一转大写 或者小写 再做比对 print('验证码正确') else: print('验证码错误')
4.3.1.8 字符串的格式话输出 format
方式1 跟%s 没有区别 没有任何优势
# 方式1: %s 占位 没有什么优势 rest = 'my name is {} my age is {}' print(rest.format('zhang', 21))

方式2 支持索引取值 并且支持重复使用
# 方式2: 支持索引取值 并且支持重复使用 rest2 = 'my name is {0} my age is {1}' print(rest2.format('zhang', 21)) rest2 = 'my name is {0} my age is {1} {0} {1} {1}' print(rest2.format('zhang', 21))
方式3 支持关键字取值(按K取值)并且支持重复使用
# 方式3: 支持关键字取值(按k 取值) 并且支持重复使用 rest3 = 'my name is {name} my age is {age}' print(rest3.format(name='zhang', age=12)) rest3 = 'my name is {name} my age is {age} {name} {age}' print(rest3.format(name='zhang', age=12))
方式4 重要 定义变量 f 打印
name = 'zhang' age = 12 print(f'my name is {name} my age is {age}') print(f'my name is {name} {name} my age is {age} {age}')
4.3.1.9 统计字符串中指定字符出现的次数 count
# 9.统计字符串中指定字符出现的次数 rest = 'zafhkjavbuqgiufqkjbckjbzbciuzzhfliuqhajbjb' print(rest.count('z')) print(rest.count('jb'))
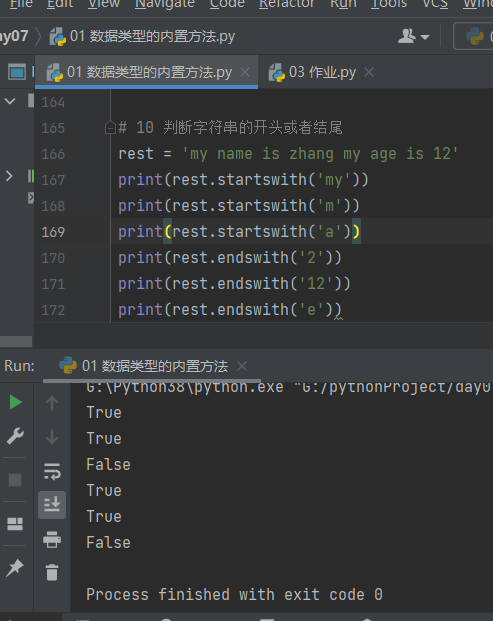
4.3.1.10 判断字符串的开头或者结尾 startswith开头 endswith结尾
# 10 判断字符串的开头或者结尾 rest = 'my name is zhang my age is 12' print(rest.startswith('my')) print(rest.startswith('m')) print(rest.startswith('a')) print(rest.endswith('2')) print(rest.endswith('12')) print(rest.endswith('e'))
4.3.1.11 字符串的替换 replace
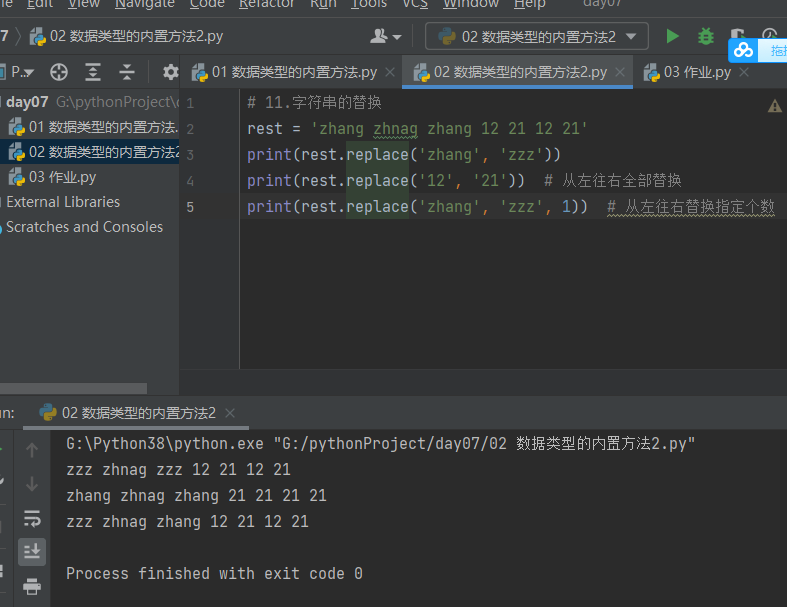
# 11.字符串的替换 rest = 'zhang zhnag zhang 12 21 12 21' print(rest.replace('zhang', 'zzz')) print(rest.replace('12', '21')) # 从左往右全部替换 print(rest.replace('zhang', 'zzz', 1)) # 从左往右替换指定个数
4.3.1.12 字符串的拼接 join
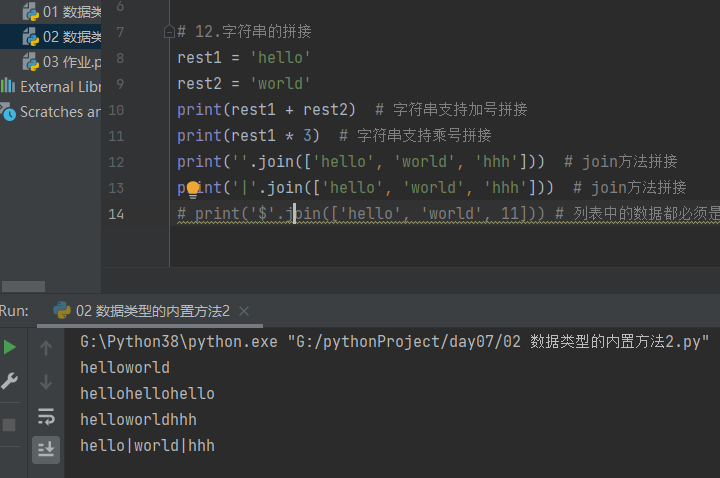
# 12.字符串的拼接 rest1 = 'hello' rest2 = 'world' print(rest1 + rest2) # 字符串支持加号拼接 print(rest1 * 3) # 字符串支持乘号拼接 print(''.join(['hello', 'world', 'hhh'])) # join方法拼接 print('|'.join(['hello', 'world', 'hhh'])) # join方法拼接
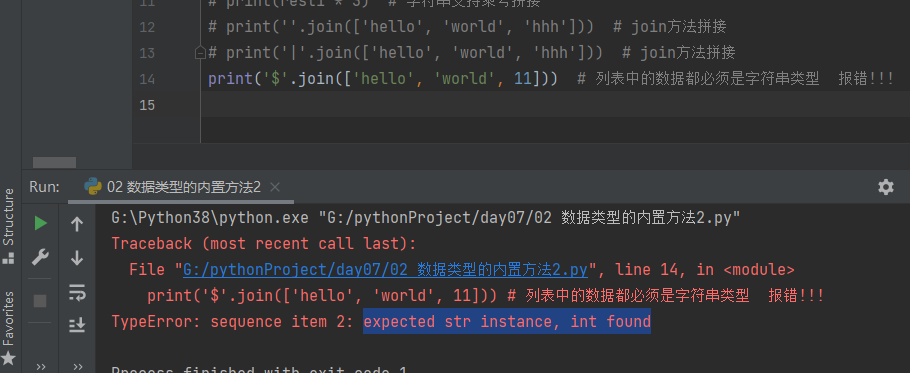
print('$'.join(['hello', 'world', 11])) # 列表中的数据都必须是字符串类型 报错!!!
4.3.1.13 判断字符串中是否是纯数字 isdigit
# 13.判断字符串中是否是纯数字 print('123'.isdigit()) # Ture print('123a'.isdigit()) # False print(''.isdigit()) # False
猜年龄判断输入是否数字
age = input('age>>:') # 先判断是否是纯数字 if age.isdigit(): age = int(age) else: print('输入不规范')
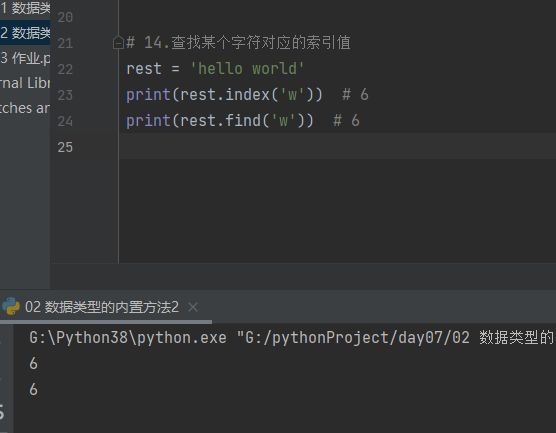
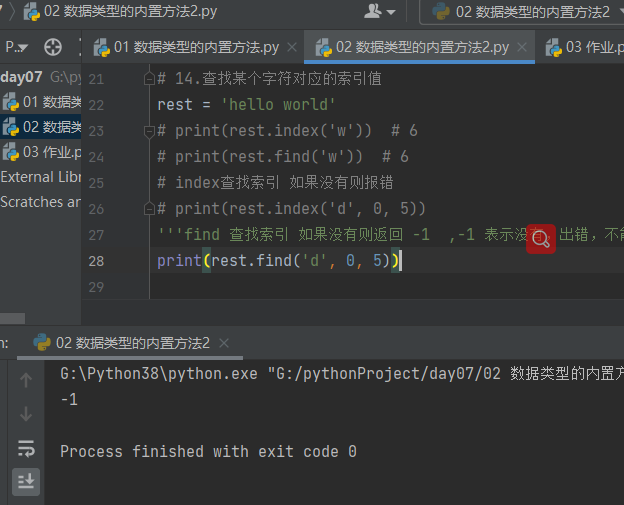
4.3.1.14 查找某个字符对应的索引值 index find
# 14.查找某个字符对应的索引值 rest = 'hello world' print(rest.index('w')) # 6 print(rest.find('w')) # 6
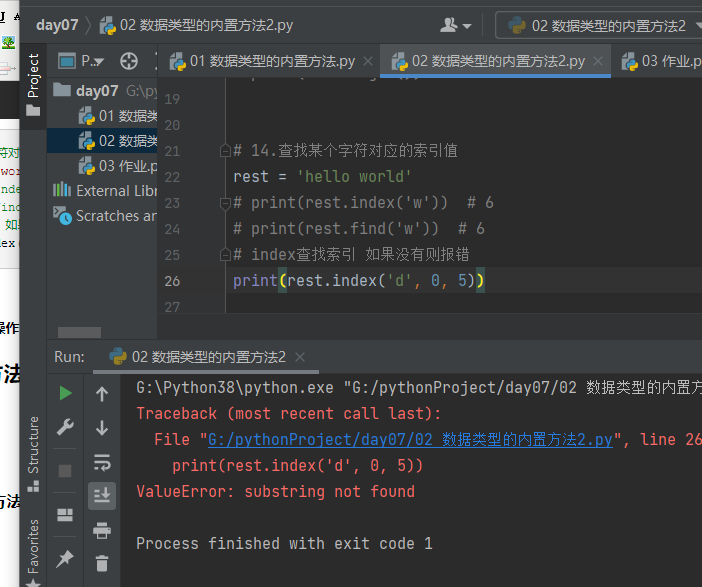
# 14.查找某个字符对应的索引值 rest = 'hello world' # print(rest.index('w')) # 6 # print(rest.find('w')) # 6 # index查找索引 如果没有则报错 print(rest.index('d', 0, 5))
rest = 'hello world' # print(rest.index('w')) # 6 # print(rest.find('w')) # 6 # index查找索引 如果没有则报错 # print(rest.index('d', 0, 5)) '''find 查找索引 如果没有则返回 -1 ,-1 表示没有,出错,不能执行''' print(rest.find('d', 0, 5))
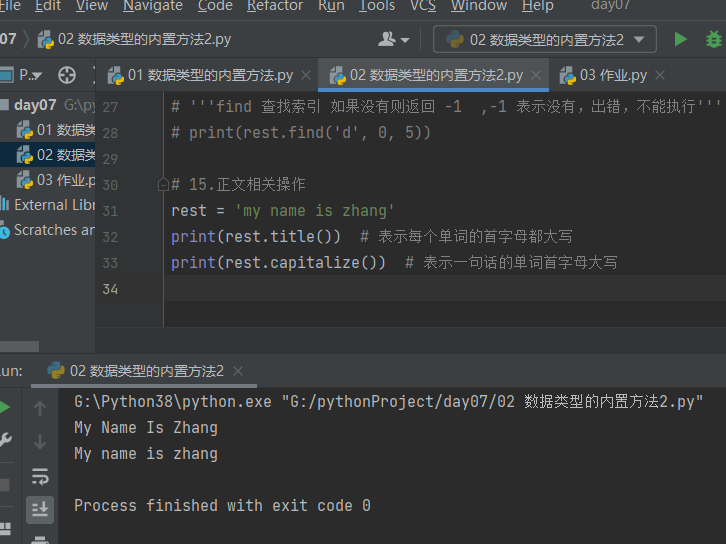
4.3.1.15 正文相关操作 开头首字母大写 title 首字母大写 capitalize
# 15.正文相关操作 rest = 'my name is zhang' print(rest.title()) # 表示每个单词的首字母都大写 print(rest.capitalize()) # 表示一句话的单词首字母大写
5.列表相关方法
5.1 关键字 list
5.2 类型转换
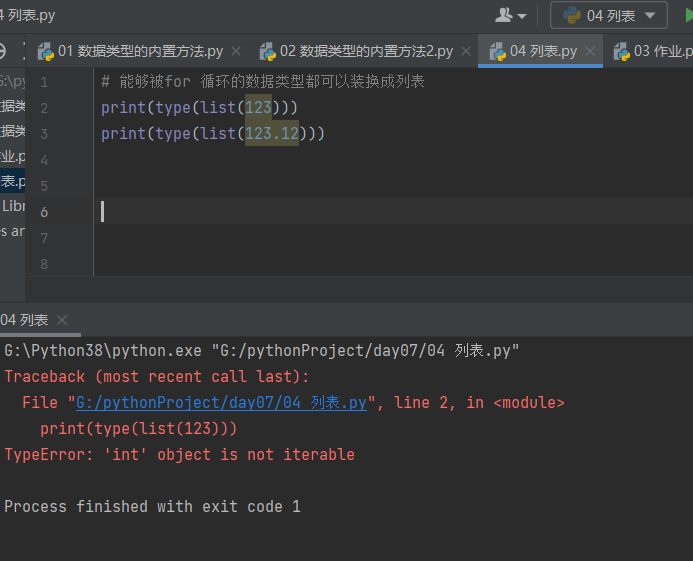
能够被for 循环的数据类型都可以装换成列表
# 能够被for 循环的数据类型都可以装换成列表 print(type(list(123))) print(type(list(123.12)))
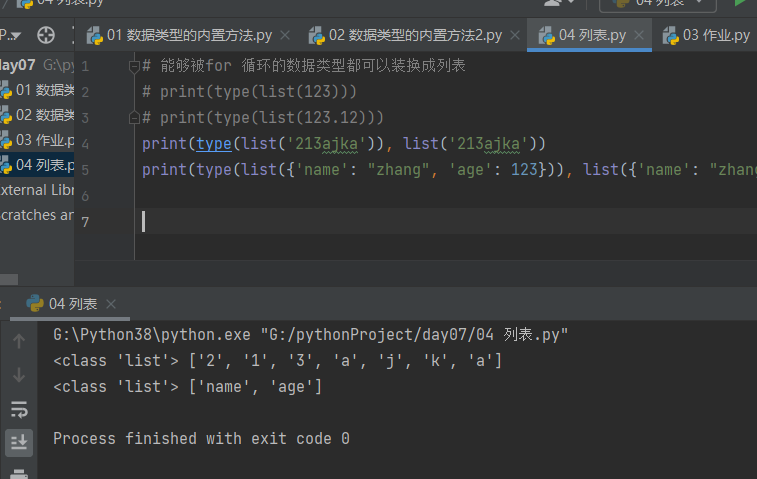
# print(type(list(123))) # print(type(list(123.12))) print(type(list('213ajka')), list('213ajka')) print(type(list({'name': "zhang", 'age': 123})), list({'name': "zhang", 'age': 123}))
5.3 需要掌握的方法
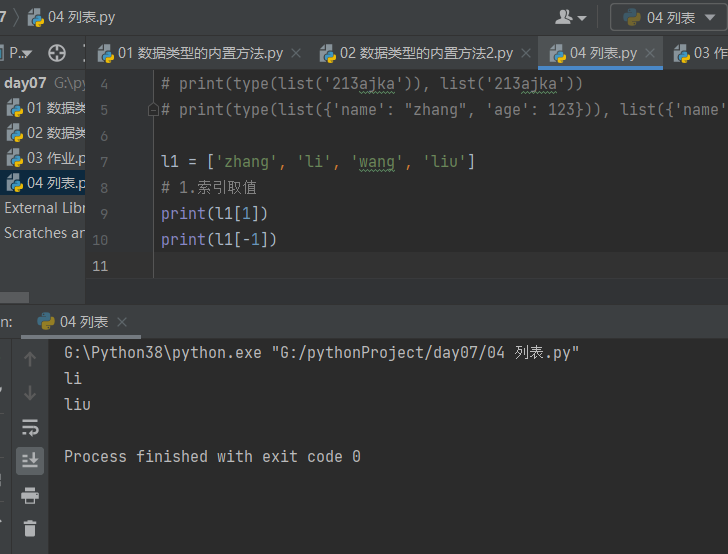
5.3.1 索引取值
l1 = ['zhang', 'li', 'wang', 'liu'] # 1.索引取值 print(l1[1]) print(l1[-1])
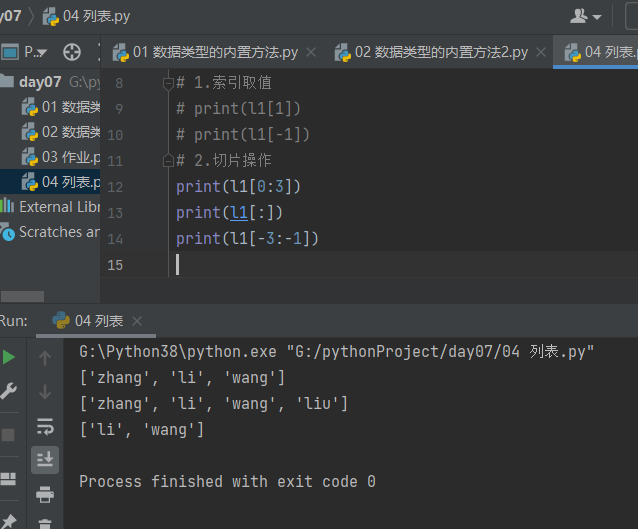
5.3.2 切片操作
# 2.切片操作 print(l1[0:3]) print(l1[:]) print(l1[-3:-1])
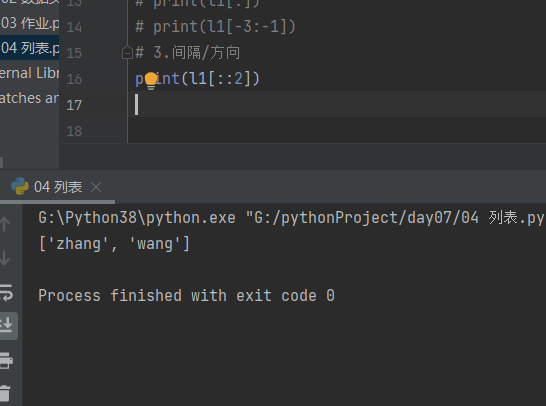
5.3.3 间隔/方向
# 3.间隔/方向 print(l1[::2])
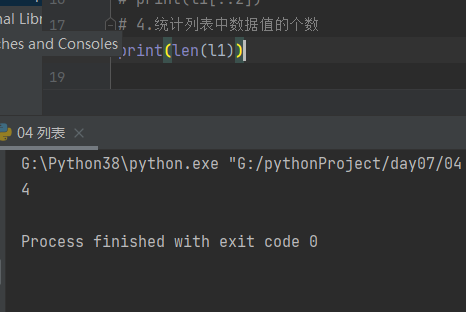
5.3.4 统计列表中数据值的个数
# 4.统计列表中数据值的个数 print(len(l1))
作业
1.基于字符串充当数据库完成用户登录(基础练习)
data_source = 'jason|123' # 一个用户数据
获取用户用户名和密码 将上述数据拆分校验用户信息是否正确
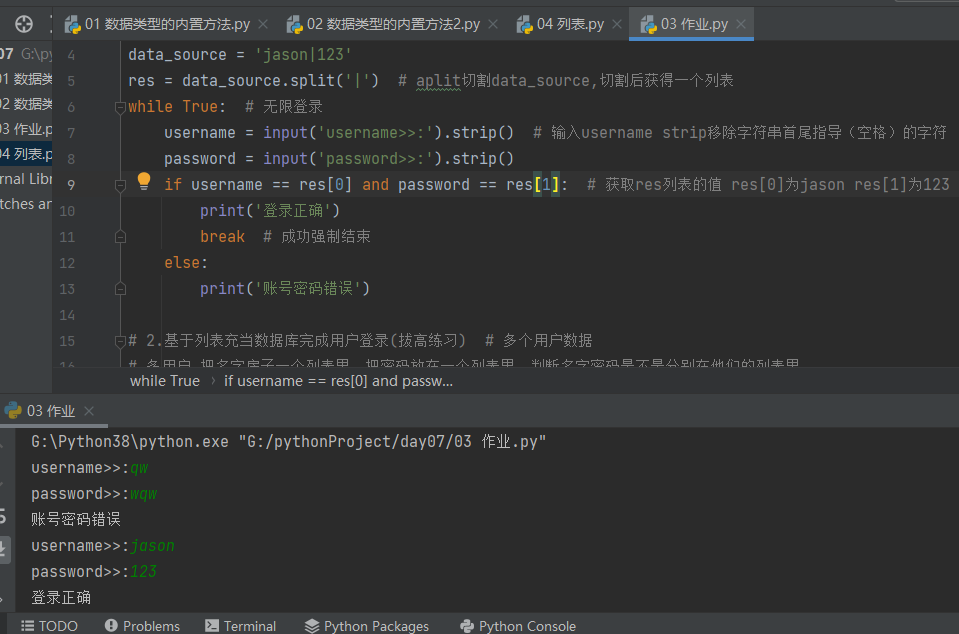
# .基于字符串充当数据库完成用户登录(基础练习) # data_source = 'jason|123' # 一个用户数据 # 获取用户用户名和密码 将上述数据拆分校验用户信息是否正确 data_source = 'jason|123' res = data_source.split('|') # aplit切割data_source,切割后获得一个列表 while True: # 无限登录 username = input('username>>:').strip() # 输入username strip移除字符串首尾指导(空格)的字符 password = input('password>>:').strip() if username == res[0] and password == res[1]: # 获取res列表的值 res[0]为jason res[1]为123 print('登录正确') break # 成功强制结束 else: print('账号密码错误')
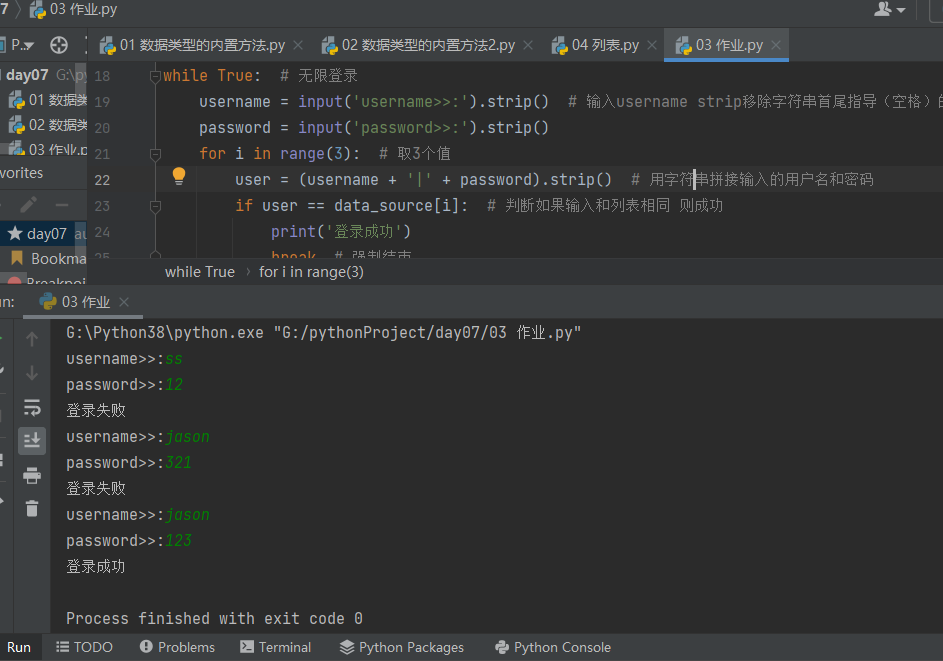
2.基于列表充当数据库完成用户登录(拔高练习) # 多个用户数据
data_source = ['jason|123', 'kevin|321','oscar|222']
# 2.基于列表充当数据库完成用户登录(拔高练习) # 多个用户数据 # 把用户输入的用户名和密码进行拼接,和列表中对比 data_source = ['jason|123', 'kevin|321', 'oscar|222'] while True: # 无限登录 username = input('username>>:').strip() # 输入username strip移除字符串首尾指导(空格)的字符 password = input('password>>:').strip() for i in range(3): # 取3个值 user = (username + '|' + password).strip() # 用字符串拼接输入的用户名和密码 if user == data_source[i]: # 判断如果输入和列表相同 则成功 print('登录成功') break # 强制结束 else: print('登录失败') continue # 失败跳过,继续尝试 break # 结束循环