MySQL事务并发问题和解决方案
提到了事务的并发会带来很多问题。比如脏读、不可重复读、幻读等问题。这么问题怎么修复呢?我们逐个复现一下,然后看下MySQL是怎么修复这些问题的。
事务并发问题的验证
为解决事务并发带来的这些问题,在SQL92标准中提出了四个隔离级别来修复这些问题。各个数据库厂商根据此标准,在各自的数据库产品中做了不同方式的实现,以此来实现数据库中事务的隔离特性。
事务的隔离级别和事务并发出现的各种问题之间有一个对应的表格,如下所示:
| 事务的隔离级别和含义 | 脏读 | 不可重复读 | 幻读 |
| 读未提交(别人改数据的事务尚未提交,我在我的事务中也能读到) | 可能 | 可能 | 可能 |
| 读已提交(别人改数据的事务已经提交,我在我的事务中才能读到) | 不可能 | 可能 | 可能 |
| 可重复读(别人改数据的事务已经提交,我在我的事务中也不去读) | 不可能 | 不可能 | 可能(MySQL中不可能) |
| 串行化(我的事务尚未提交,别人就别想读数据) | 不可能 | 不可能 | 不可能 |
针对如上的表格,我们逐个验证在每一种隔离级别在MySQL中,脏读、不可重复读、幻读是怎么发生的,又是如何修复的。
但是在开始实验之前,我们需要准备如下的表和初始化数据,实验的过程中使用的表和初始化SQL语句如下:
CREATE TABLE `t` ( `id` int(11) NOT NULL AUTO_INCREMENT, `a` int(11) DEFAULT NULL, `b` varchar(32) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; -- 初始化测试数据,如下: insert into t (a, b) values (1,'a'), (2,'b'), (3,'c'), (4, 'd');
读未提交隔离级别
修改MySQL的session级别的隔离级别为读未提交,如下所示:
mysql> set session transaction_isolation='READ-UNCOMMITTED'; Query OK, 0 rows affected (0.01 sec)
我们需要同时开启两个命令窗口,两个窗口的session级的隔离级别都设置读未提交,也就是说两个命令行中都需要执行上面的命令。然后才可以开始我们下面的实验。
在RU级别下,脏读可能发生,不可重复读可能发生、幻读也可能发生,也就是说在读未提交隔离级别下,所有事务并发所带来的问题,都可能发送,该事务隔离级别最低,什么问题都没有解决。但是数据库的并发性能也是最好的。也就是说,我们对数据库隔离级别设置的越高,它的并发性能就越底。
下面我们来演示一下,在该隔离级别下,脏读、不可重复读、幻读都是如何发生的。
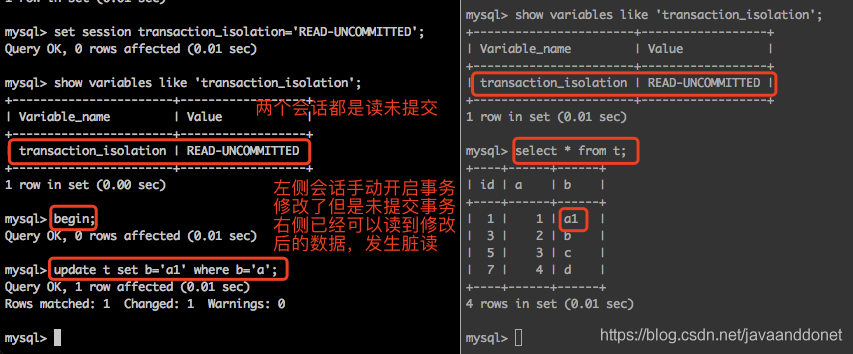
脏读是如何发生的
实验步骤如下:
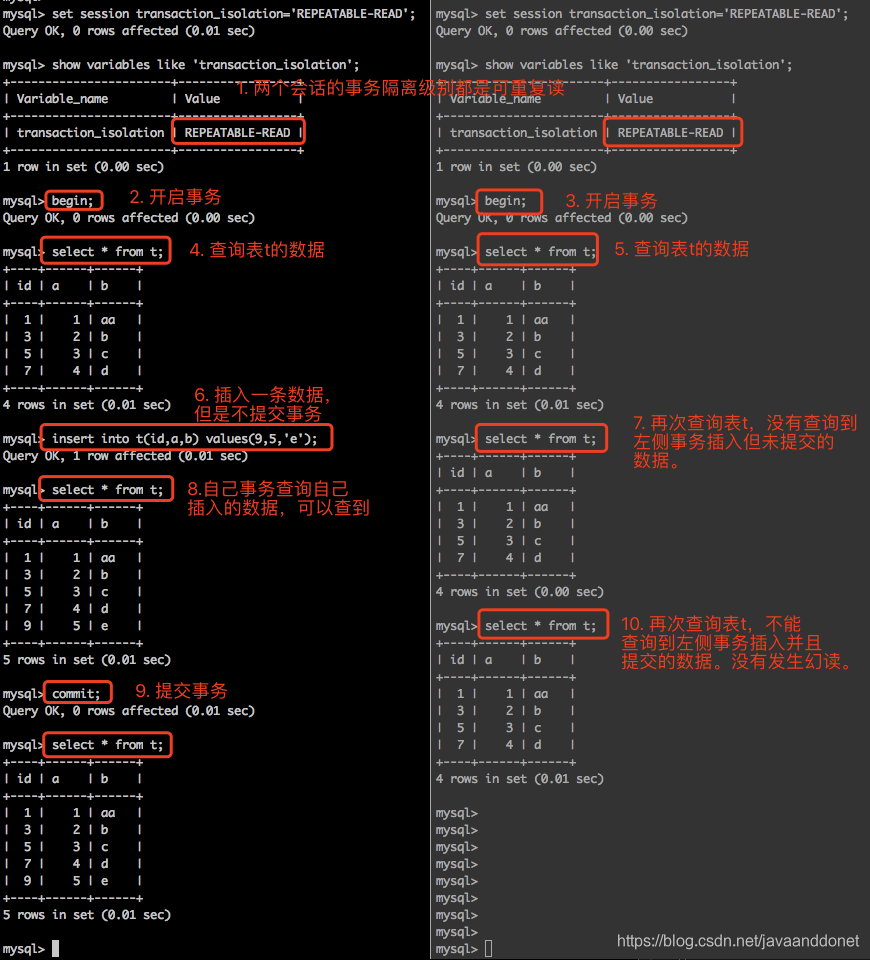
- 开启两个会话,把它们的事务隔离级别都设置为读未提交。
- 在第一个会话中,显示的使用begin语句开启一个事务,然后去修改表t中的一行数据。但是此次修改我们不提交这个事务。
- 在另外一个会话中,去查询一下t表中的数据内容,发现t表中的数据已经包含了第一个会话中的更改操作。
- 第二个会话读取到了第一个会话中修改但是还没有提交的事务,还没有提交的修改我们称之为脏数据,而这个脏数据被其他事务读取到了,这就是脏读。
过程截图如下所示:
不可重复读是如何发生的
实验步骤如下:
- 开启两个会话,把它们的隔离级别都设置读未提交。
- 在两个会话中都使用begin手动开启事务。
- 在两个开启事务的会话中,都查询一下表t的数据内容。
- 在第一个会话中删除表t中的一条数据。
- 在第二个会话中再次去查看数据内容,看到一个会话中删除还未提交的操作影响到了当前事务对表t数据的查询结果。此时就发生了不可重复读。第二个会话中的事务读取到了第一个会话中删除但未提交的数据。
过程截图如下所示: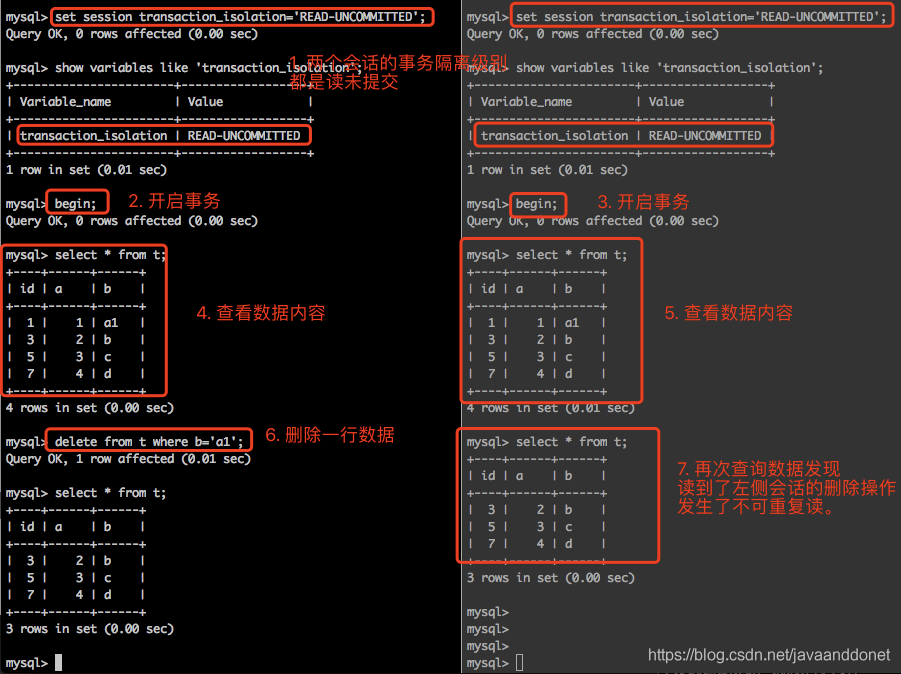
幻读是如何发生的
实验步骤如下:
- 设置两个会话的事务隔离级别都是读未提交。
- 在第一个会话和第二个会话中都使用begin开启一个事务。
- 分别在第一个和第二个事务中,查询一下表t中的数据。
- 在第一个会话中,插入一条数据,但是不提交事务。
- 在第二个会话中,查询表t的数据,发现可以查询到第一个会话中新增但是未提交的数据。此时在第二个事务中就发生了幻读。刚才查询表中的数据的时候还是4条记录,现在确实5条记录,像是产生了幻觉一样。
实验截图如下: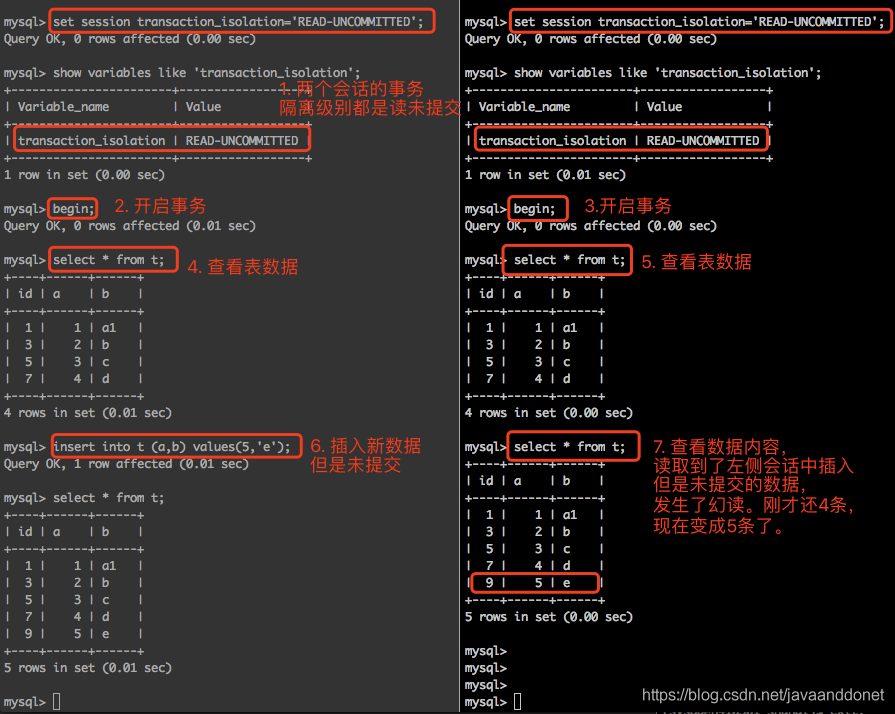
读已提交隔离级别
修改MySQL的session级别的隔离级别为读已提交,如下所示:
mysql> set session transaction_isolation='READ-COMMITTED'; Query OK, 0 rows affected (0.01 sec)
我们需要同时开启两个命令窗口,两个窗口的session级的隔离级别都设置读已提交,也就是说两个命令行中都需要执行上面的命令。然后才可以开始我们下面的实验。
在RC级别下,脏读不可能发生,不可重复读、幻读还是会发生的。
脏读是如何避免的
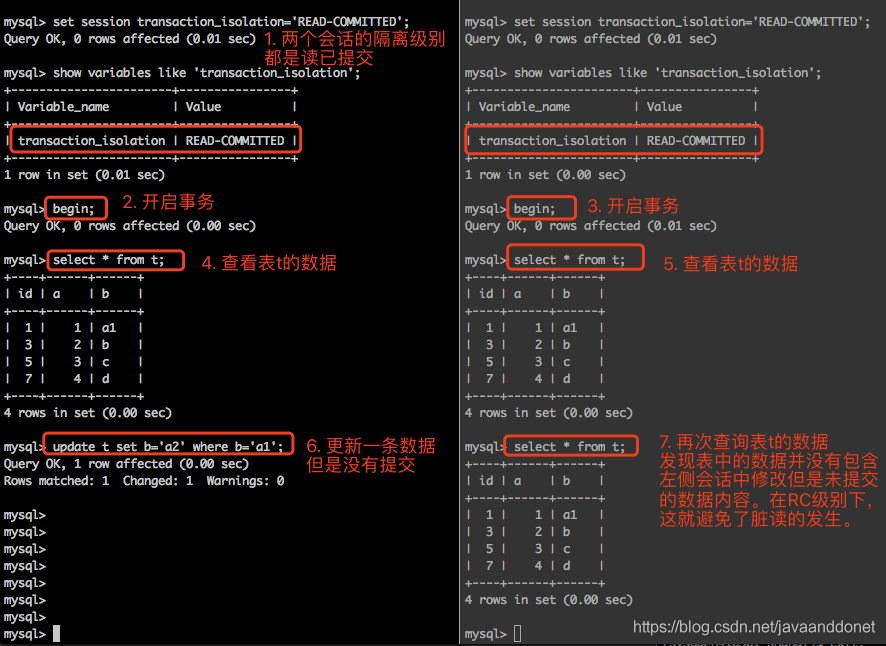
实验步骤如下:
- 开启两个会话,并且把会话的隔离级别设置为读已提交。
- 在两个会话中,分别使用begin开启事务。
- 在来个开启的事务中,分别查询表t中的数据内容。
- 在第一个会话中,修改一条记录,但是不要提交。
- 在第二个会话中,查看表t中的数据内容不包含会话一种修改但是未提交的数据。这说明在读已提交隔离级别下,可以避免读取到其他事务未提交的修改操作,这就是避免了脏读的发生。
实验截图如下:
不可重复读是如何发生的
实验步骤如下:
- 开启两个session会话,把它们的session级的隔离级别都设置读已提交。
- 在两个会话中都使用begin手动开启事务。
- 在第一个会话中去更改数据,但是先不要提交事务。
- 在第二个会话中去查看是否可以看到第一个会话中修改但是还没有提交的数据,发现不能看到。
- 在第一个会话中,提交会话一的事务。
- 在第二个会话中,再次查看是否可以看到第一个会话修改并且已经提交的数据,发现可以看到。
过程截图如下所示: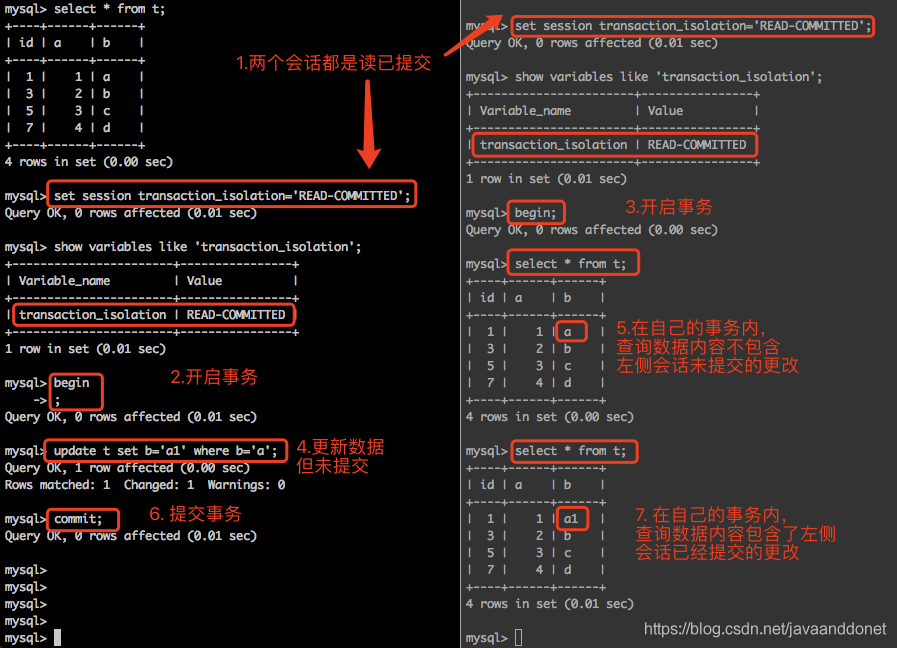
幻读是如何发生的
实验步骤如下:
- 开启两个会话,分别设置会话的隔离级别为读已提交级别。
- 在两个会话中,分别使用begin开启事务,然后分别查询表t中的初始化数据。
- 在第一个会话中,向表t中插入一条数据,但是不要提交。
- 在第二个会话中,查看是否可以查询到第一个会话中插入未提交的数据,发现不可以。
- 在第一个会话中,提交刚才插入数据的事务。
- 在第二个会话中,再次查询是否可以查询到第一个会话中插入的已经提交的数据,发现可以查询到。这就是幻读,一个事务读取到了另外一个事务插入且已经提交的数据。
实验过程的截图如下: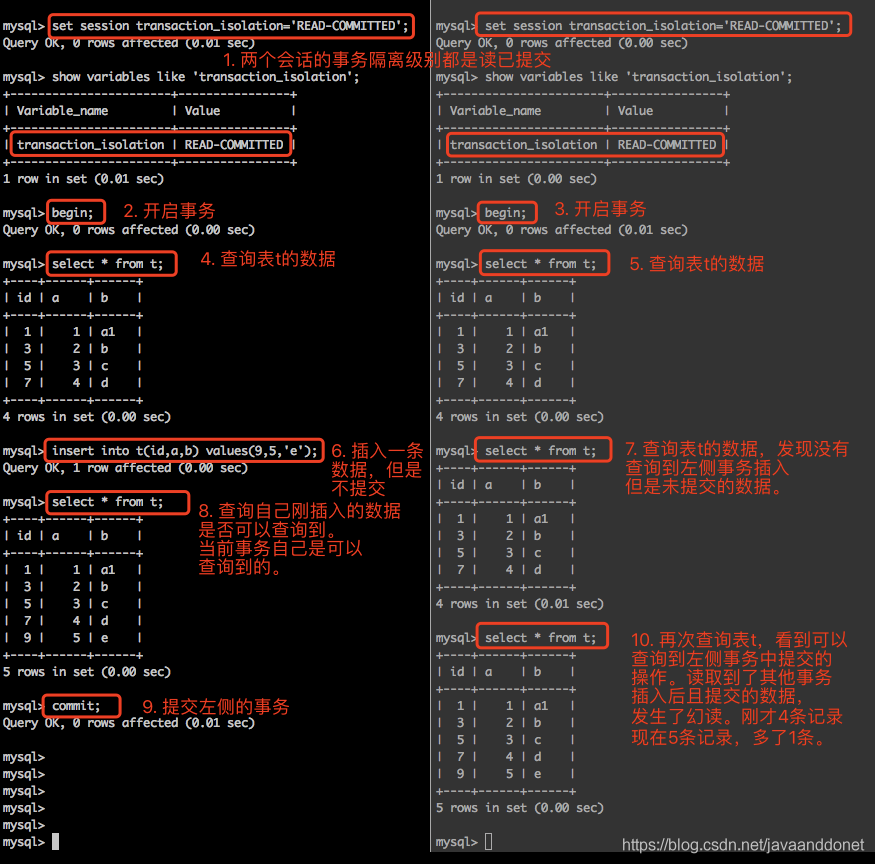
可重复读隔离级别
修改MySQL的session级别的隔离级别为可重复读,如下所示:
mysql> set session transaction_isolation='REPEATABLE-READ'; Query OK, 0 rows affected (0.01 sec)
我们需要同时开启两个命令窗口,两个窗口的session级的隔离级别都设置可重复读,也就是说两个命令行中都需要执行上面的命令。然后才可以开始我们下面的实验。
脏读是如何避免的
实验步骤:
- 开启两个会话窗口,并且设置它们的会话级别都为可重复读。
- 在两个会话窗口中都手动开启事务。并且都查询一下表t的数据内容。
- 在第一个会话中,更新一条记录但是此时先不提交事务。
- 在第二个会话中,查询表t的数据发现没有会话一种修改的数据内容,此时已经说明没有发生脏读。
- 在第一个会话中提交事务。
- 在第二个会话中,再次查询表t中的数据,发现t中的数据仍然没有第一个会话中修改且提交的数据内容。更说明没有发生脏读数据。
实验结果如下: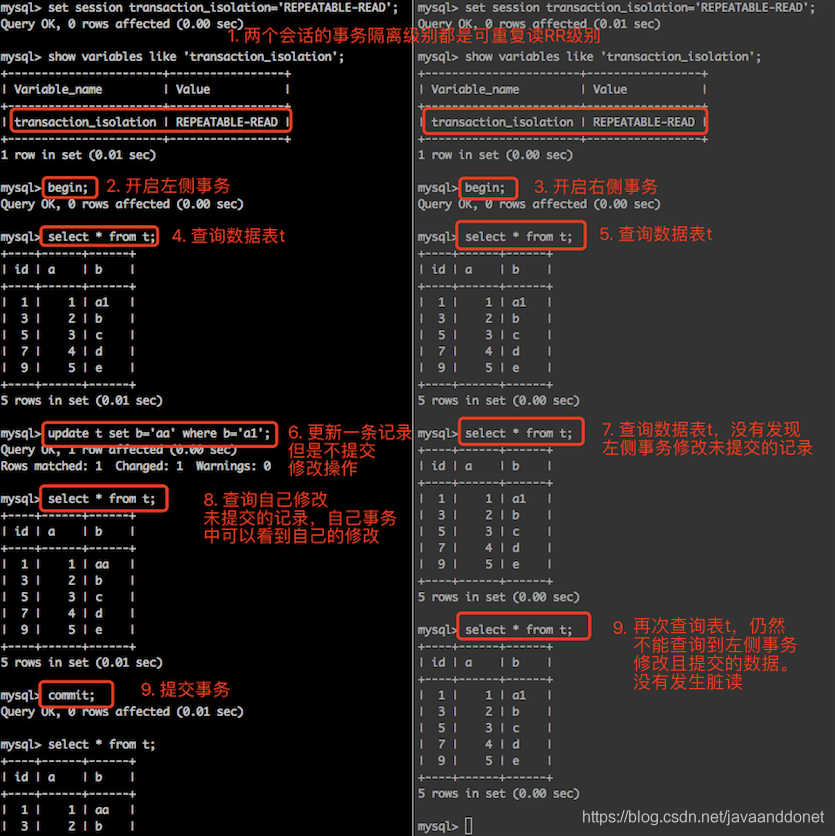
不可重复读是如何避免的
实验步骤如下:
- 开启两个会话窗口,并且设置它们的会话级别都为可重复读。
- 在两个会话窗口中都手动开启事务。并且都查询一下表t的数据内容。
- 在第一个会话中,删除一条记录但是此时先不提交事务。
- 在第二个会话中,查询表t的数据发现没有会话一中修改的数据内容,此时已经说明没有发生脏读。
- 在第一个会话中提交事务。
- 在第二个会话中,再次查询表t中的数据,发现t中的数据仍然没有第一个会话中删除且提交的数据内容。说明没有发生不可重复数据,在第二个事务执行过程中,读取表t的数据内容始终是一样的,是可以重复读取表t中的数据内容的,这就避免了不可重复读的发生。
实验截图如下: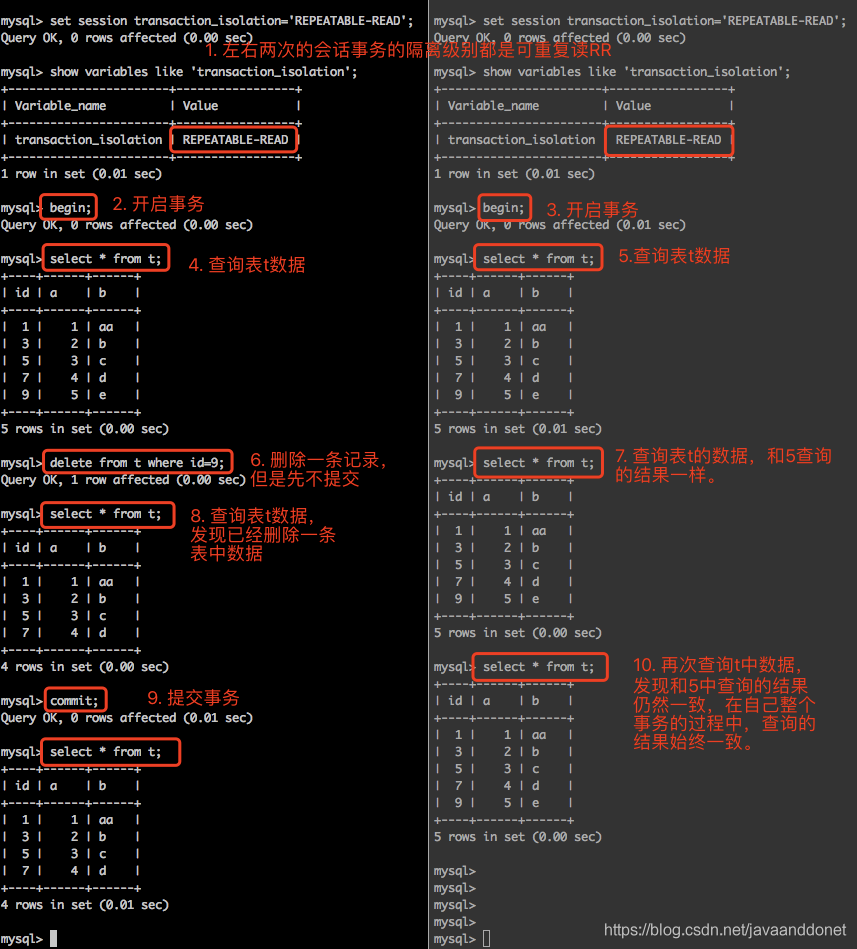
幻读是如何避免的
正常的事务隔离级别下,在可重复的事务给力级别下,是有可能出现幻读的。但是在MySQL中不会发生幻读,MySQL修复了幻读的问题。
为什么MySQL中不能发生幻读呢?因为MySQL通过了MVCC多版本并发控制和间隙锁来避免了可重复读隔离级别下幻读的发生。先看下实现的步骤和效果。
实验步骤:
- 开启两个会话窗口,并且设置它们的会话级别都为可重复读。
- 在两个会话窗口中都手动开启事务。并且都查询一下表t的数据内容。
- 在第一个会话中,插入一条记录但是此时先不提交事务。
- 在第二个会话中,查询表t的数据发现没有会话一中插入的数据,此时已经说明没有发生脏读。
- 在第一个会话中提交事务。
- 在第二个会话中,再次查询表t中的数据,发现t中的数据仍然没有第一个会话中插入且提交的数据内容。说明没有发生幻读。
实现效果如下图所示:
序列化隔离级别
所有的事务都排队,没有获取到锁就等待其他事务提交后自己的事务才可以继续,否则就出现等待状态。如果超过了最大的等待时间,则事务等待超时,会退出当前的事务。而这个最大的等待时间是由参数innodb_lock_wait_timeout来控制的,这个参数的默认值为50,代表最大等待时间为50秒。
这里就不再做演示了。在MySQL中,可重复读隔离级别已经修复了脏读、不可重复读、幻读的问题,在序列化隔离级别下就更没有问题了。但是推荐使用可重复读隔离级别,因为这样的级别会比序列化级别的并发性高。
如何解决事务并发问题
MVCC的认识
MVCC:multi version concurrency control,多版本并发控制。只在读已提交和可重复读两个事务隔离级别下才有MVCC的实现,在读未提交和串行化中不存在MVCC。
下面通过这个图解,我们一起分析一些MySQL是如果做到MVCC的。
MVCC和事务结合的核心思想是:一个事务只需要在启动的时候声明说,“以我启动的时刻为准,如果一个数据版本是在我启动之前生成的,就认;如果是我启动以后才生成的,我就不认,我必须要找到它的上一个版本”。
- MySQL中事务ID是从1开始连续自增的,并且全局唯一,不同的事务他们的ID不同。按照发生的时间先后持续自增。也就是后发生的事务的ID一定比先发生的事务ID的值要大。如上图所示,事务是从1持续增长。
- 每个事务在启动的时候会分配一个唯一的ID,确切的说是在事务执行第一个非select语句的时候,才分配的事务ID。只读事务可以认为不分配事务ID,会给分配一个很大的随机数作为当前只读事务的ID。
- 数据库中的每行数据,在被DML事务语句操作并提交之后,都会用操作它的事务ID作为该行数据最新的版本号。所以我们可以理解为:事务ID=数据的版本号。
- 当某个事务启动的瞬间,MySQL会基于此时数据库中的事务分布情况,构建一个一致性视图(也可以理解为快照),在这个事务运行期间,始终使用这一个视图,来保证这个事务运行的整个过程中,所读取到的数据都是一致的,不管其他事务怎样修改提交数据,这些操作对这个当前的事务而言都是透明的,当前事务所能读到的数据自始至终都是一样的,不受其他事务的影响,以此达到事务的隔离性。这就是MySQL的MVCC技术核心思想和效果。而这个构建一致性视图的基础就是用运行中的事务的ID组成一个运行中的事务ID数组,然后基于每行数据的版本号和这个数组进行比较来判断是否可以读到某一行数据。
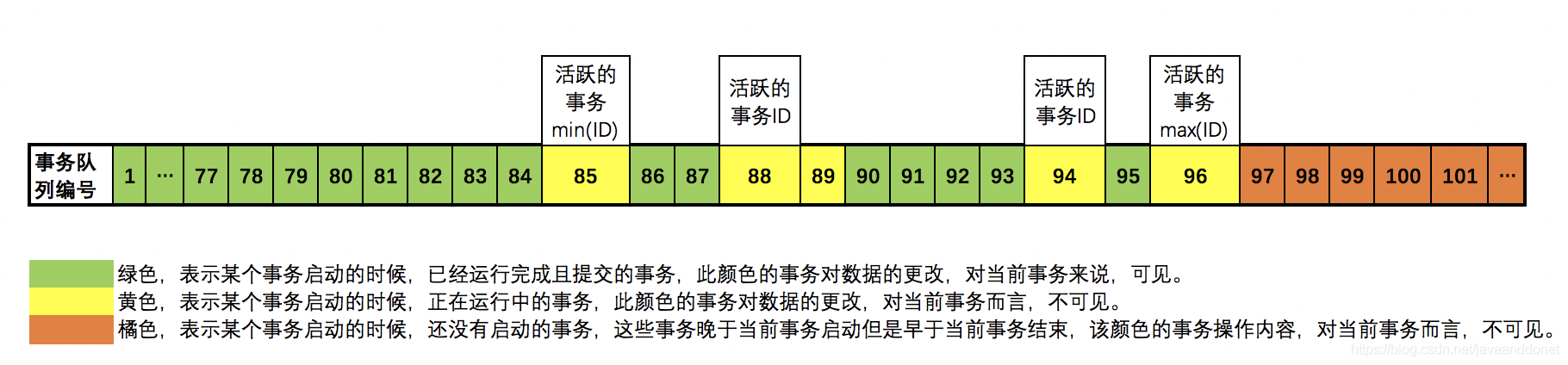
- 假设某个事情启动的瞬间,当前数据库的事务队列情况如上所示。
- 其中正在运行中的事务的ID有85,88,89,94,96共5个事务,MySQL会用这些运行中的事务的ID组成一个运行中的事务ID数组。此时的数据为:[85,88,89,94,96]。
- 其中最小的事务ID为:min(ID)=85,最大的事务ID为:max(ID)=96。
- 绿色表示已经结束的事务。
- 黄色表示运行中的事务。
- 橘色表示未来要启动的并且结束事务,橘色的事务在当前这个将要启动的事务启动之后才启动的。
- 在刚启动当前事务的时候,这些橘色的事务是不存在的。但是在当前事务启动后,并且运行的过程中,MySQL中是可以启动新的事务的,而这些新事务的ID由于是后启动的,所以它们的ID肯定比当前事务的max(ID)要大,所以他们会排在当前活动的最大的事务ID的后面。
- 在当前事务运行过程中去判断某行数据是否可见的时候,是有可能读取到后启动的事务修改并提交的数据的。为了便于我们分析,所以把它们都用橘色的事务给标出来放在最后面了。这样才便于我们理解和判断在后启动的事务所修改的行数据是否对当前事务可见。
- 那么在这个事务运行过程中,判断某行数据是否可见的时候,判断的原则就是拿到某个数据行的版本号,我们暂时把某行数据得到的版本号记作:X,拿x和当前的活动的事务ID数组进行比较。判断原则和结果如下:
- 如果 x < min(ID),例如 x=83 < min(ID),那么表示这个数据行的数据内容是在当前事务启动之前,就已经完成修改且提交的内容,可见,即:当前事务可以读到这样的修改。
- 如果x刚好等于某个正在运行的某个事务的ID,例如 x = 88 这个事务ID,那么表示这行数据是由88这个事务修改的内容。由于当前事务启动的时候,这个88编号的事务正在运行还没有提交,所以对于当前事务而言,不可见,即:不能读取这行数据的修改内容。
- 如果 min(ID) < x < max(ID),并且不等于活跃事务ID数组中的任何一个值。例 x=91 这个事务ID,那么表示这个数据行的数据是在当前事务启动之前,就已经运行结束并且提交的修改。此时对于当前运行的事务而言,可见,即:可以读取这行数据的修改内容。
- 如果 max(id) < x,例如x=99,表示在当前事务启动的时候,修改这行数据的编号为99的事务还没有启动,是在当前事务启动之后才启动的,但是99号事务比当前事务运行的还要快,它已经运行结束并提交了它的修改。此时,对于当前事务来说,不可见,即:是不能读取到这行数据被修改的内容。要知道在当前事务启动之后运行的过程中,是可以有其他事务陆续启动的,所以在当前事务运行的过程中,晚于当前事务启动的那些事务也是有可能早于当前事务结束的,所以才出现了在判断当前事务中数据可见性的时候,读取到了比max(ID)还要大的数据版本号。
- 当我们发现一条数据的当前版本对当前事务不可见的时候,MySQL这个时候是不能把这个最新版本的数据返回给客户端的。那么它会怎么做呢?总不能不返回任何数据吧。
- innodb会通过undo-log,通过数据行的版本号,向上找一个版本。拿到这个版本的ID之后,再次判断这个版本号的数据内容对当前事务是否可见,如果可见则通过undo-log计算出上一个版本的数据内容,然后将数据结果返回。
- 如果上一个版本的数据仍然不满足对当前事务可见的要求,那么继续查找上一个版本的数据内容。直到找到符合要求的、对当前事务可见的数据版本。然后通过undo-log根据版本号的顺序依次计算出应该返回的数据内容,然后再返回给客户端。
一致性视图创建的时间点
针对不同的事务隔离级别,一致性视图创建时间点也是各不相同的。在各个事务隔离级别下,MySQL中MVCC的数据一致性视图创建的时候遵循如下规则
- 读未提交:读未提交隔离级别下直接返回行记录上的最新值,没有视图概念。
- 读已提交:这个一致性视图是在每个 SQL 语句开始执行的时候创建的。也就是说,如果一个事务中包含多条SQL语句,那么在每一个SQL语句执行前都会创建一个一致性视图,所以在这个事务中,会有多个一致性视图存在。如果同样的SQL语句,在同一个事务的不同的时间点执行,那么他们的一致性视图就可能会不一样,这也是导致在读已提交事务隔离级别下出现不可重复读和幻读的原因。
- 可重复读:在开启事务之后就创建了。这个视图是在事务启动时创建的,整个事务存在期间都用这个视图。但是在开启事务的方式不同的情况下,创建一致性视图的时间又有点区别,详细区别如下:
- 序列化:对于“串行化”隔离级别下,直接用加锁的方式来避免并行访问。没有一致性视图的概念。
事务的启动方式和区别
MySQL默认是自己开维护每一个SQL语句事务的开启和提交的。它通过参数autocommit来控制,当参数为1的时候表示自动开启和提交事务;当为0的时候表示需要手动开启和提交事务。
当然了,如果MySQL的控制数据是否自动提交的参数设置为1,也是支持我们自己去开启和提交事务的时候,我们可以使用如下的命令去手动的开启和提交事务。
- begin:开启事务,它和start transaction的功能是等效的。此时其实不会马上创建一致性视图,会在后面第一个操作innodb表的SQL语句执行的时候创建一致性事务视图,而这个操作语句不管是什么类型的操作语句,随便select,insert,update,delete都可以。与此同时事务的ID的分配也是在执行这第一个操作innodb表的SQL语句时分配的,需要注意的是:只读事务的事务ID是一个随机数,非只读事务的ID是一个比较正常数。
- start transaction with consistent snapshot:开启事务,并且马上开始创建一个一致性视图,供当前启动的事务期间使用。此时事务的ID也分配好了。这是该语句和begin/start transaction语句不同的地方。
- autocommit=0:设置数据库自动提交事务的功能关闭,执行这个命令后,此时只要执行任何一个操作innodb表的SQL语句,事务开启了,需要在SQL语句结束后,手动执行commit命令才会提交事务。否则不提交前面的SQL语句。
- commit:提交事务的语句。
- commit work with chain:提交事务,并开启下一个事务。这个命令等效于执行完成commit之后,马上又执行了一个begin命令。所以,它的效果等效于commit+begin
- rollback:回归事务的语句。
长事务
什么是长事务
前面我们提到MySQL在可重复读隔离级别下,一个事务在开启之后一直到这个事务结束之前,它所能看到的数据内容和这个事务启动的时候看到的数据内容是相同的,这个事务不会受到其他事务修改数据的影响。其实这个时候,是有其他事务修改数据并提交操作的。MySQL之所以能够实现可重复读的隔离级别,是通过数据行的版本号来依次判断后才实现的。
那么试想一下,如果一个事务从早上就开启了,但是它一直没有提交,直到晚上还没有提交,此时为了满足这个事务的可重复读的要求,MySQL就需要一直保留着这数据库中的很多数据行的版本信息和undo-log,以便这个事务在晚上某个时刻想要查看某一行数据的时候,可以通过这些版本号和undo-log追溯到这个事务启动时刻的数据版本。如果这一天中,数据库中有很多事务发生。那么此时就会存在很多的版本号和undo-log。这就导致了回滚日志的暴涨,并且增大了MySQL数据库发生锁冲突的可能性。
举例说明长事务:
- 在某个时刻(今天上午9:00)用命令begin,开启了一个事务A(对于可重复读隔离级别,此时一个视图read-view A也创建了),这是一个很长的事务……
- 事务A在今天上午9:20的时候,查询了一个记录R1的一个字段f1的值为1……(注意:在9:00~9:20的这20分钟内,事务其实还没有真正的启动,事务ID也没有分配,一致性视图也没有真正的创建。所以这20分钟是不会有任何锁或回滚空间产生的。事务A在执行了这个查询记录R1操作的时候,才有有事务ID、一致性视图的创建这写动作发生)
- 今天上午9:25的时候,一个事务B(随之而来的read-view B)也被开启了,它更新了R1.f1的值为2(同时也创建了一个由2到1的回滚日志),这是一个短事务,事务随后就被commit了。
- 今天上午9:30的时候,一个事务C(随之而来的read-view C)也被开启了,它更新了R1.f1的值为3(同时也创建了一个由3到2的回滚日志),这是一个短事务,事务随后就被commit了。
- ……这里有很多其他事务的操作了记录R1…但是都是短事务。
- 到了下午3:00了,长事务A还没有commit,为了保证事务在执行期间看到的数据在前后必须是一致的,那些老的事务视图、回滚日志就必须存在了,这就占用了大量的存储空间。
这就是我们应该尽量不要使用长事务的原因,与此同时,在此期间事务A锁操作的表,很容易会发生锁等待或者死锁。
我们上面说的这样的事务就是一个长事务。在 MySQL 5.5 及以前的版本,回滚日志是跟数据字典一起放在 ibdata 文件里的,即使长事务最终提交,回滚段被清理,文件也不会变小。 这个“清理”的意思是 “逻辑上这些文件位置可以复用”,但是并没有删除文件,也没有把文件变小。
所以我要避免使用长事务。那么我们该如何避免使用长事务呢?
如何避免长事务
从应用开发端方面
- 确认是否使用了 set autocommit=0。这个确认工作可以在测试环境中开展,把 MySQL 的 general_log 开起来,然后随便跑一个业务逻辑,通过 general_log 的日志来确认。
- 确认是否有不必要的只读事务。有些框架会习惯不管什么语句先用 begin/commit 框起来。有些是业务并没有这个需要,但是也把好几个 select 语句放到了事务中。这种只读事务可以去掉。
- 业务连接数据库的时候,根据业务本身的预估,通过 SET MAX_EXECUTION_TIME 命令,来控制每个语句执行的最长时间,避免单个语句意外执行太长时间。
从数据库端方面
- 监控 information_schema.Innodb_trx 表,设置长事务阈值,超过就报警 / 或者 kill,Percona 的 pt-kill 这个工具不错,推荐使用。
- 在业务功能测试阶段要求输出所有的 general_log,分析日志行为提前发现问题。
- 如果使用的是 MySQL 5.6 或者更新版本,把 innodb_undo_tablespaces 设置成 2(或更大的值)。如果真的出现大事务导致回滚段过大,这样设置后清理起来更方便。
转载:https://blog.csdn.net/javaanddonet/article/details/110289124


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧