Python 基础 -2.2 文件操作
文件操作:
os.mknod("test.txt") 创建空文件
fp = open("test.txt",w) 直接打开一个文件,如果文件不存在则创建文件
fp = open(file='xxx.txt',mode='r',encoding='utf-8') #以只读模式打开一个xxx.txt文件 data = fp.read() #读文件内容 fp.close() #关闭文件
关于open 模式:
w 以写方式打开, (其实是w是创建文件。没有就创建文件,要是之前有文件,就清空文件,然后在写,所以注意使用) a 以追加模式打开 (从 EOF 开始, 必要时创建新文件) r+ 以读写模式打开,以文本方式,读出。(存入硬盘的数据是二进制),读出的二进制文件转换成文本也就是字符串 w+ 以读写模式打开 (参见 w ) a+ 以读写模式打开 (参见 a ) rb 以二进制读模式打开 就是硬盘怎么存的,取出来不转换。也就数取出来的也是二进制。不是给人看的,用于网络传输,打开图片,视频
等
。 wb 以二进制写模式打开 (参见 w ) ab 以二进制追加模式打开 (参见 a ) rb+ 以二进制读写模式打开 (参见 r+ ) wb+ 以二进制读写模式打开 (参见 w+ ) ab+ 以二进制读写模式打开 (参见 a+ )
fp.read([size]) #size为读取的长度,以byte为单位 fp.readline([size]) #读一行,如果定义了size,有可能返回的只是一行的一部分 fp.readlines([size]) #把文件每一行作为一个list的一个成员,并返回这个list。其实它的内部是通过循环调用readline()来实现的。如果提供size参数,size是表示读取内容的总长,也就是说可能只读到文件的一部分。 fp.write(str) #把str写到文件中,write()并不会在str后加上一个换行符 fp.writelines(seq) #把seq的内容全部写到文件中(多行一次性写入)。这个函数也只是忠实地写入,不会在每行后面加上任何东西。 fp.close() #关闭文件。python会在一个文件不用后自动关闭文件,不过这一功能没有保证,最好还是养成自己关闭的习惯。 如果一个文件在关闭后还对其进行操作会产生ValueError fp.flush() #把缓冲区的内容写入硬盘 fp.fileno() #返回一个长整型的”文件标签“ fp.isatty() #文件是否是一个终端设备文件(unix系统中的) fp.tell() #返回文件操作标记的当前位置,以文件的开头为原点 fp.next() #返回下一行,并将文件操作标记位移到下一行。把一个file用于for … in file这样的语句时,就是调用next()函数来实现遍历的。 fp.seek(offset[,whence]) #将文件打操作标记移到offset的位置。这个offset一般是相对于文件的开头来计算的,一般为正数。但如果提供了whence参数就不一定了,whence可以为0表示从头开始计算,1表示以当前位置为原点计算。2表示以文件末尾为原点进行计算。需要注意,如果文件以a或a+的模式打开,每次进行写操作时,文件操作标记会自动返回到文件末尾。 fp.truncate([size]) #把文件裁成规定的大小,默认的是裁到当前文件操作标记的位置。如果size比文件的大小还要大,依据系统的不同可能是不改变文件,也可能是用0把文件补到相应的大小,也可能是以一些随机的内容加上去。
关于默认:
编码格式要是不写,python3默认的就是utf-8,而python2是ASCII,所以你存的时候以什么编码方式存的,读出的时候也要指定以什么方式读,否则容易出现乱码。
之前先记住,不管是何种编码方式,最后存入在硬盘的数据都是二进制。
接下来我已经GBK方式存下一些数据。
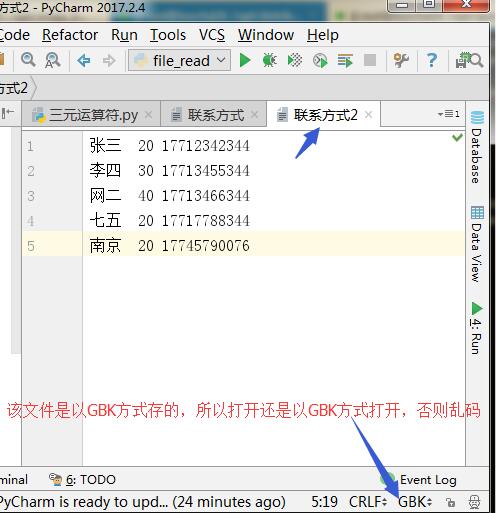
此时代码中encode='GBK'的含义就是将数据从硬盘上读出来(二进制)以GBK方式转换成,我们能看出的汉字。
python3以读出以GBK显示。此时正常显示
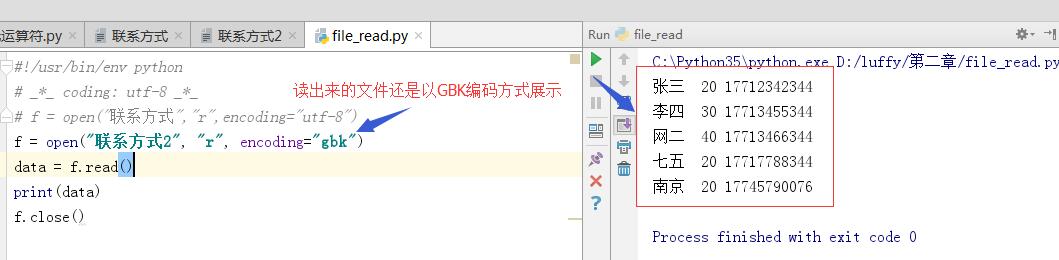
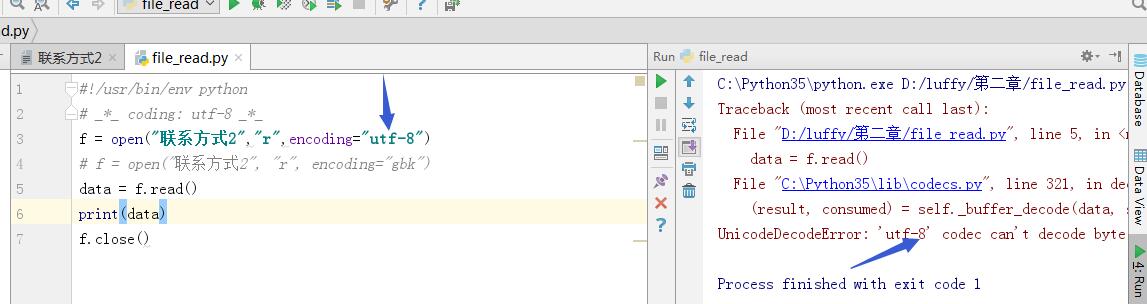
要是以UTF-8就报乱码
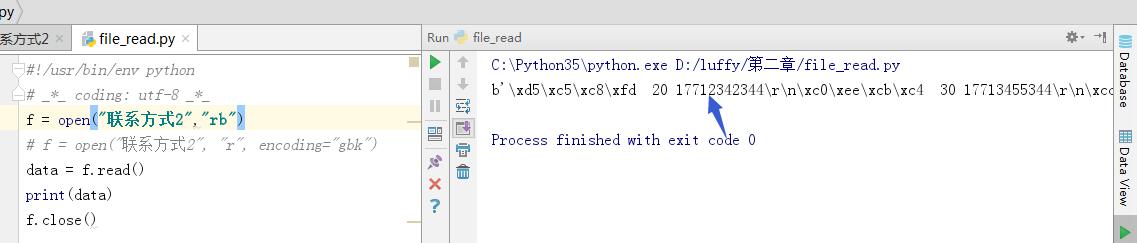
1. 二进制方式打开文件rb
因为硬盘上存放的数据都是二进制,所以读出来的数据也就二进制,且不转换,这样做的目的主要有网络传输,打开图片,视频等方式
2. 文件处理 - 智能检测编码的工具
文件不知道的编码的情况下,我想打开,使用第三方库,自动检测去打开
先安装第三方库。其实规矩去检查有可能是什么

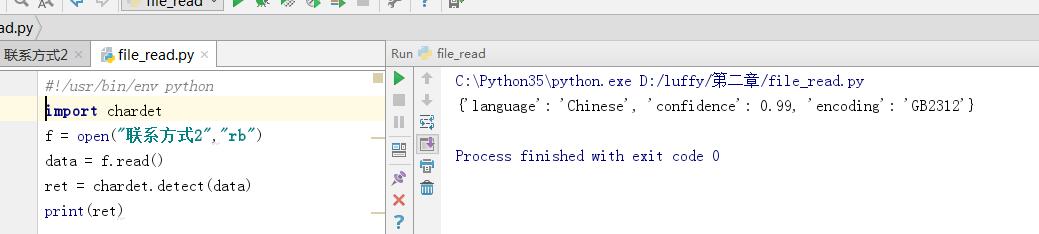
#!/usr/bin/env python import chardet f = open("联系方式2","rb") data = f.read() ret = chardet.detect(data) print(ret)
输出
{'language': 'Chinese', 'confidence': 0.99, 'encoding': 'GB2312'}
confidence也就是相似度99%,类似机器学习。根据各种规则,视图去猜测最像的。
所以在代码中改为decoding='GBK',再去读取。
3. 文件处理 - 读模式
f = open("联系方式2", "r", encoding="gbk") for line in f: print(line) f.close()
输出。每行有空行,是因为print后面多加一个空行
张三 20 17712342344 李四 30 17713455344 网二 40 17713466344 七五 20 17717788344 南京 20 17745790076 Process finished with exit code 0
也可以抑制换行
f = open("联系方式2", "r", encoding="gbk") for line in f: print(line,end="") f.close()
输出
张三 20 17712342344 李四 30 17713455344 网二 40 17713466344 七五 20 17717788344 南京 20 17745790076
4. 文件处理 - 写模式
f = open("联系方式2", "w", encoding="utf-8") f.write("caimengzhi 南京 188772738") f.close() # w表示只写模式 # encoding="utf-8" 表示将要写入的unicode字符串编码成utf-8格式
但是之前的都没了,因为w的方式就得情况之前的内容。
二进制写文件

因为你是字符串,所以不能写入。可以将字符串编码成utf-8,gbk等

5.文件处理 - 追加模式
之前联系方式中内容是
张三 20 17712342344 李四 30 17713455344 网二 40 17713466344 七五 20 17717788344 南京 20 17745790076
f = open("联系方式", "ab") f.write("\ncaimengzhi 南京 188772738".encode("utf-8")) # 以utf-8的方式编码写入文件 f.close()
# \n是回车,防止写的的数据接在之前后面
运行输出
张三 20 17712342344 李四 30 17713455344 网二 40 17713466344 七五 20 17717788344 南京 20 17745790076 caimengzhi 南京 188772738 # 新添加的数据
6. 文件处理 - 混合操作(读写模式)
f = open("测试", "r+", encoding="gbk") data = f.read() print(data) f.write("\n哈哈") f.write("\n哈哈2") print(f.read()) f.close()
输出
123
345
但是查看文件
123
345
哈哈
哈哈2
实现了读写模式。但是输出第二个没有输出,是因为第一次读完了。
7.文件处理 - 写读模式(基本没有什么卵用,基本用不到)
f = open("测试", "w+") data = f.read() print(data) f.write("\n哈哈1") f.write("\n哈哈2") f.write("\n哈哈3") print(f.read()) f.close()
之前文件
1234
345
哈哈
哈哈2
运行后,没有输出,但是去看文件内容有东西,只是w还是之前说的,该文件没有就创建文件,有就清空文件。
哈哈
哈哈2
所以读写(会清空文件)模式和写读(会追加)模式不一样。
8.文件处理 - 文件处理其他模式

1. 光标操作文件
文件内容
root@leco:/home/leco# cat 2.txt 11111111111111111 22222222222222222 3333333333333333 44444444444 55555555555
开始操作文件
In [1]: f = open("2.txt",'r') # 打开文件 In [2]: f.readline() # 一行一行开始读,读第一行 Out[2]: '11111111111111111\n' In [3]: f.readline() # 读第二行, Out[3]: '22222222222222222\n' In [4]: f.readline() # 读第三行 Out[4]: '3333333333333333\n' In [5]: f.readline() # 读第四行 Out[5]: '44444444444\n' In [6]: f.readline() # 读第五行 Out[6]: '55555555555\n' In [7]: f.readline() # 读第六行,因为没有所以为空 Out[7]: '' In [8]: f.tell() # 获取光标位置 Out[8]: 77 In [9]: f.seek(0) # 设置光标位置点,本次设置为开头,从头再来 Out[9]: 0 In [10]: f.tell() # 获取光标位置 Out[10]: 0 In [11]: f.readline() # 读取第一行 Out[11]: '11111111111111111\n' In [12]: f.readline() Out[12]: '22222222222222222\n'
其中tell还是seek都是找的字节。read找的是字符。
9.文件处理 - 文件修改
文件修改之前
张三 20 17712342344 李四 30 17713455344 网二 40 17713466344 七五 20 17717788344 南京 20 17745790076
操作文件
f = open("测试", "r+", encoding="utf-8") # data = f.read() f.seek(10) # 跳到第十个字节处 f.write("[南京南京 nanjing]") f.close()
执行结果,文件修改后
张三 20[南京南京 nanjing]30 17713455344 网二 40 17713466344 七五 20 17717788344 南京 20 17745790076
解释:

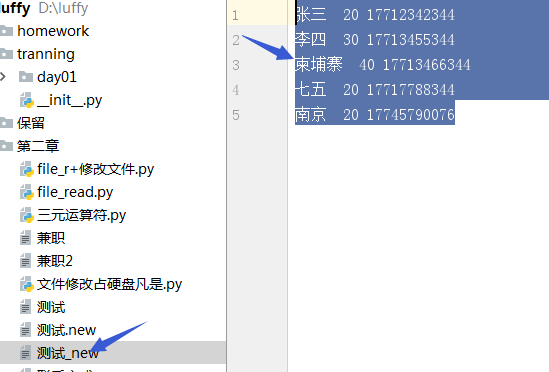
修改文件,测试文件中的“网二’”改为“柬埔寨”
1. 把文件全部读出来,读到内容,然后修改,然后在写入源文件
2. 按照行读源文件,然后判断是否修改,然后写入其他文件
我们使用第二个方法:
文件修改之前
张三 20 17712342344 李四 30 17713455344 网二 40 17713466344 七五 20 17717788344 南京 20 17745790076
代码
f_name = "测试" f_new_name = "%s.new" % f_name old_str = "网二" new_str = "柬埔寨" f = open(f_name,"r",encoding="utf-8") f_new = open(f_new_name,"w",encoding="utf-8") for line in f: if old_str in line: line = line.replace(old_str,new_str) f_new.write(line) f.close() f_new.closed
文件修改之后