爬取Boss直聘招聘信息(保存Excel\生成词云)
爬取Boss直聘招聘信息(保存Excel\生成词云)
一、目的:
- 获取java相关岗位的招聘信息
- 导出招聘信息到excel表
- 将招聘信息的技术要求生成词云
二、步骤
1. 新建maven项目
2. 导入相关依赖
<!-- 处理html相关 -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.3</version>
</dependency>
<!-- excel相关 -->
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-excel</artifactId>
<version>1.0.0</version>
</dependency>
3. 相关类创建
-
WorkInfo类,招聘信息类
@Data @ToString @ExcelSheet public class WorkInfo { @ExcelField String jobName;//职位名称 @ExcelField String jobArea;//工作地区 @ExcelField String jobPubTime;//发布时间 @ExcelField String education;//学历 @ExcelField String jobLimit;//限制(工作n年经验、在校/应届) @ExcelField List<String> tags;//标签 @ExcelField String detailUrl;//职位详细详细url @ExcelField WorkDetail workDetail;//岗位要求详细信息 @ExcelField Company company;//公司信息 } -
Company 类 ,公司信息类
@Data @ToString public class Company { String companyName; String companyType; String staffNumber; String benefits; } -
主类:
public class GetWorkInfo { private static List<WorkInfo> all = new LinkedList<>(); public static void main(String[] args) { // 注意几个请求参数 String workName="java";//职业名称 for (int i = 1; i < 5; i++) {//当前页码i String url = "https://www.zhipin.com/c101280100/?query="+workName+"&page="+i+"&ka=page-"+i; String html = getHtml(url); cleanHtml(html); } System.out.println("一共获取到"+all.size()+"条与["+workName+"相关]的招聘信息"); for (WorkInfo workInfo : all) { System.out.println(workInfo); } //保存所有workinfo tag 到文本 FileWriter writer; try { writer = new FileWriter("E:/tags.txt"); for (WorkInfo workInfo : all) { for (String tag : workInfo.getTags()) { writer.write(tag+" "); } } writer.flush(); writer.close(); } catch (IOException e) { e.printStackTrace(); } //保存数据到excel ExcelExportUtil.exportToFile( all,"E:\\re.xls"); } /** * 模拟浏览器请求,获取网页内容 * @param url * @return */ public static String getHtml(String url) { CloseableHttpClient httpClient = null; CloseableHttpResponse response = null; String result = ""; // 通过址默认配置创建一个httpClient实例 httpClient = HttpClients.createDefault(); // 创建httpGet远程连接实例 HttpGet httpGet = new HttpGet(url); // 设置请求头信息,鉴权 httpGet.setHeader("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36 Edg/89.0.774.54"); //cookie需要手动到网站获取 httpGet.setHeader("Cookie", "cookie-value"); // 设置配置请求参数 RequestConfig requestConfig = RequestConfig.custom().setConnectTimeout(35000)// 连接主机服务超时时间 .setConnectionRequestTimeout(35000)// 请求超时时间 .setSocketTimeout(60000)// 数据读取超时时间 .build(); // 为httpGet实例设置配置 httpGet.setConfig(requestConfig); // 执行get请求得到返回对象 try { response = httpClient.execute(httpGet); // 通过返回对象获取返回数据 result = EntityUtils.toString(response.getEntity()); } catch (IOException e) { e.printStackTrace(); } return result; } public static Object cleanHtml(String html){ org.jsoup.nodes.Document document = (org.jsoup.nodes.Document) Jsoup.parseBodyFragment(html); //获取body Element body = document.body(); Elements jobPrimaries = body.getElementById("main").getElementsByClass("job-primary"); //遍历所有的招聘信息 for (int i = 0; i < jobPrimaries.size(); i++) { //第i条招聘信息 Element job = jobPrimaries.get(i); //招聘概要信息 WorkInfo workInfo = new WorkInfo(); String jobName = job.getElementsByClass("job-name").get(0).text(); String jobArea = job.getElementsByClass("job-area-wrapper").get(0).text(); String jobPubTime = job.getElementsByClass("job-pub-time").get(0).text(); String educationWork = job.getElementsByClass("job-limit").get(0).getElementsByTag("p").get(0).outerHtml(); String education = educationWork.substring(educationWork.lastIndexOf("</em>")+5,educationWork.indexOf("</p>")); String jobLimit = job.getElementsByClass("job-limit").get(0).getElementsByTag("p").get(0).text().replace(education,""); String url = "https://www.zhipin.com"+job.getElementsByClass("primary-box").get(0).attr("href"); List<String> tagList = new LinkedList<>(); Elements tags = job.getElementsByClass("tag-item"); for (Element tag : tags) { tagList.add(tag.text()); } //公司信息 Company company = new Company(); String companyName = job.getElementsByClass("company-text").get(0).getElementsByTag("h3").text(); String companyType = job.getElementsByClass("company-text").get(0).getElementsByTag("p").get(0).getElementsByTag("a").text(); String benefits = job.getElementsByClass("info-desc").get(0).text(); company.setCompanyName(companyName); company.setCompanyType(companyType); company.setBenefits(benefits); workInfo.setJobName(jobName); workInfo.setJobArea(jobArea); workInfo.setJobPubTime(jobPubTime); workInfo.setEducation(education); workInfo.setJobLimit(jobLimit); workInfo.setTags(tagList); workInfo.setDetailUrl(url); workInfo.setCompany(company); all.add(workInfo); } return null; } }
4. 运行结果
-
控制台输出
)
-
re.xls文件内容
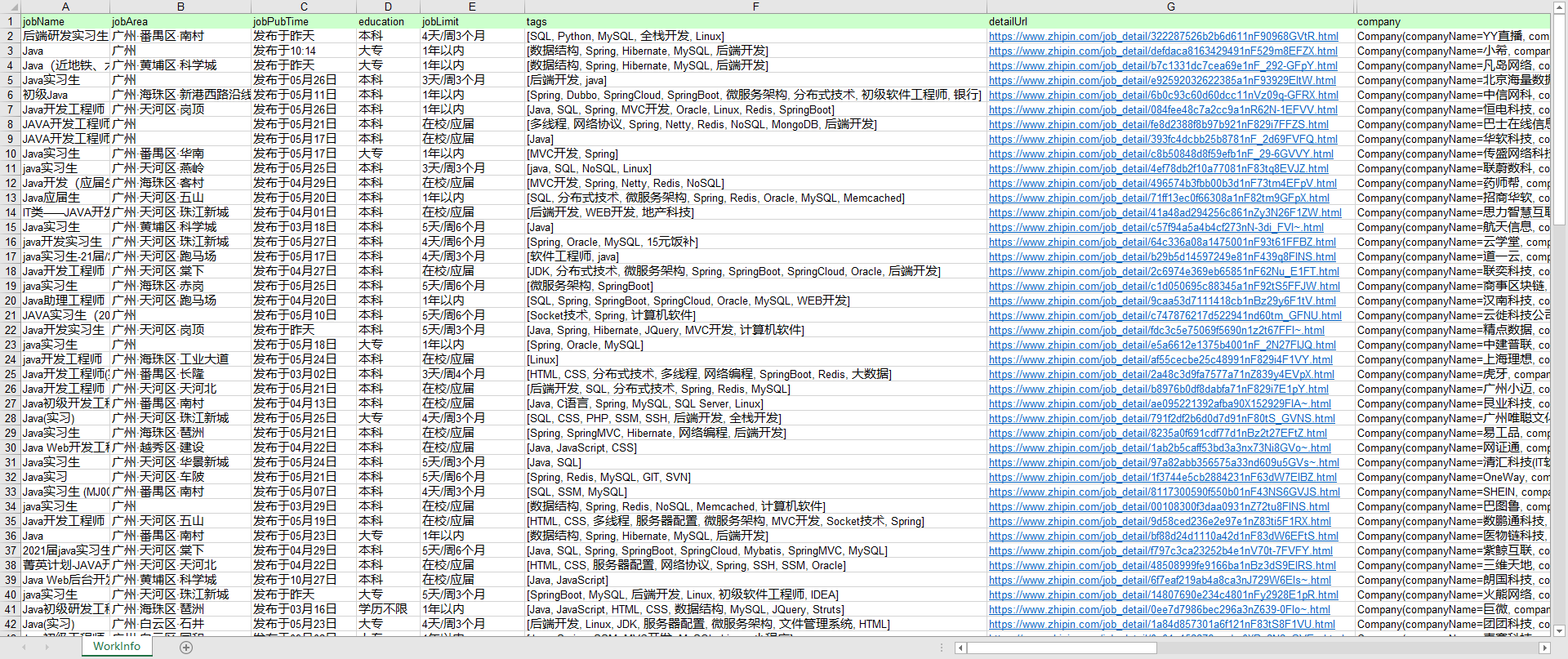
-
tag.txt文件内容
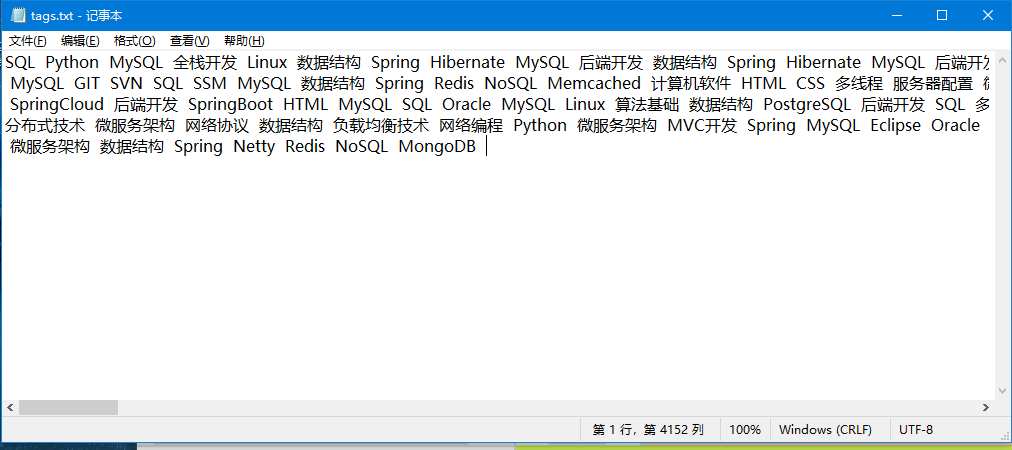
5. 生成技术云图
- 源码:
import wordcloud
import matplotlib.pyplot as plt
#读取文件
f = open("tag.txt", "r", encoding="utf-8")
t = f.read()
f.close()
#使用wordcloud 生成云图
w = wordcloud.WordCloud( \
width = 1000, height = 700,\
background_color = "white",
font_path = "msyh.ttc" ,
mask = plt.imread('背景模板.jpg'),
)
w.generate(t)
w.to_file("grwordcloud9.png")
-
结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号