
IntelliJ搭建Scala及Spark工程
1 软件准备
注意:以下是针对Windows 7 64bit的开发环境搭建
|
软件名称 |
描述 |
下载地址 |
版本 |
软件安装包 |
|
JDK |
JAVA 开发工具包 |
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html |
Java SE Development Kit 8u171 Windows x64 |
jdk-8u171-windows-x64.exe |
|
Scala SDK |
Scala开发工具包 |
2.11.12 Windows (msi installer) |
scala-2.11.12.msi |
|
|
IntelliJ IDEA |
集成开发工具 |
2018.1.2 Community |
ideaIC-2018.1.2.exe |
|
|
Scala Plugin |
IntelliJ IDEA的Scala插件 |
2018.1.9 |
scala-intellij-bin-2018.1.9.zip |
|
|
Spark |
Spark组件 |
2.1.1 (May 02 2017) Pre-build for Apache Hadoop 2.7 and later |
spark-2.3.0-bin-hadoop2.7.tgz |
|
|
Winutils |
为Hadoop在Windows运行提供基本命名行的工具 |
https://github.com/steveloughran/winutils/blob/master/hadoop-2.7.1/bin/winutils.exe |
For hadoop-2.7.1 |
winutils.exe |
2 软件安装和环境配置
2.1 JDK 安装
Step 1: 双击jdk-8u171-windows-x64.exe,一直点击“下一步”直到安装完成
2.2 Scala SDK 安装
Step 1: 双击scala-2.11.12.msi,一直点击“下一步”直到安装完成
2.3 IntelliJ IDEA 安装
Step 1: 双击ideaIC-2018.1.2.exe,一直点击“下一步”直到安装完成
Step 2: 点击“开始>>所有程序>> JetBrains>>IntelliJ IDEA Community Edition 2018.1.2”,进入Welcome to IntelliJ IDEA界面。

2.3.1 Scala Plugin安装
Step 1: 在Welcome to IntelliJ IDEA界面选择“Configure>>Plugins”,打开Plugins界面

Step 2: 点击“Install plugin from disk…”按钮,选择scala-intellij-bin-2018.1.9.zip文件所在路径后,点击“OK”
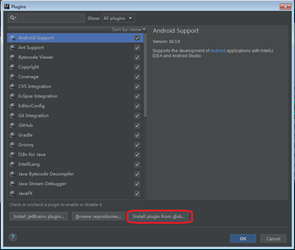
Step 3: Scala Plugin安装后,激活需要重启IntelliJ IDEA。
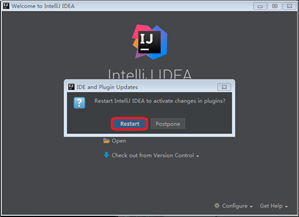
3 创建Scala工程
Step 1: 在Welcome to IntelliJ IDEA界面,点击“Create New Project”,进入New Project界面。

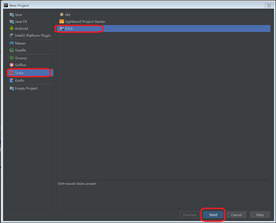
Step 2: New Project界面选择“Scala>>IDEA”,点击“Next”按钮
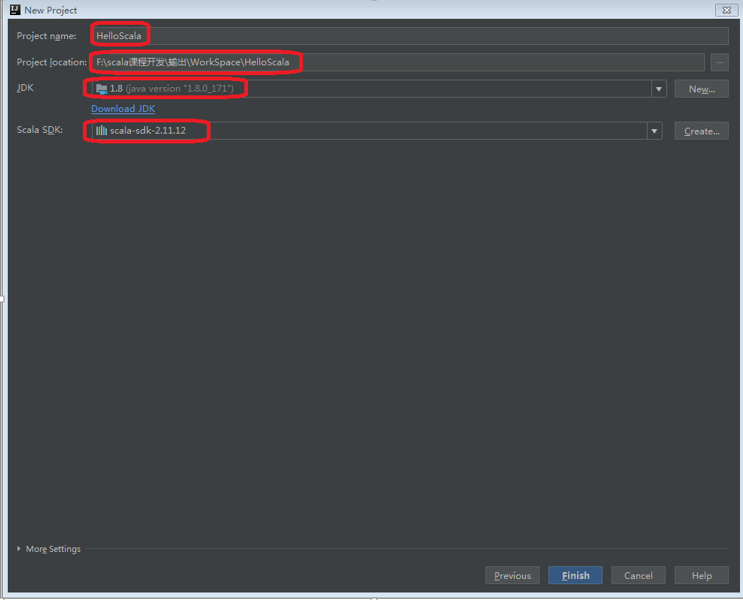
Step 3: 输入工程名称,工程路径,选择JDK安装路径(默认为“C:\Program Files\Java\jre1.8.0_171”),选择Scala SDK安装路径(默认为“C:\Program Files (x86)\scala”),点击“Finish”按钮,进入该工程的编辑界面
4 添加Spark库
Step 1: 解压spark-2.1.1-bin-hadoop2.7.tgz文件
Step 2: 将winutils.exe拷贝到Step 1解压后的spark-2.1.1-bin-hadoop2.7\bin目录中
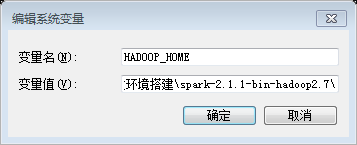
Step 3: 设置Windows的环境变量HADOOP_HOME为解压后的目录,设置完成后重启IntelliJ IDEA
Step 4: 在IntelliJ IDEA中点击菜单“File>>Project Structure”,进入“Project Structure”界面

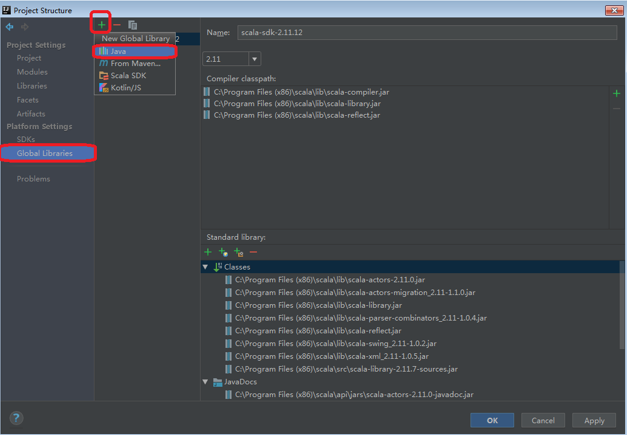
Step 5: 在“Project Structure”界面,选择“Global Libraries>> +>>Java”,选择添加Spark相关所有jar包(默认在spark-2.1.1-bin-hadoop2.7\jars目录下,可按“Shift”键进行多选)。
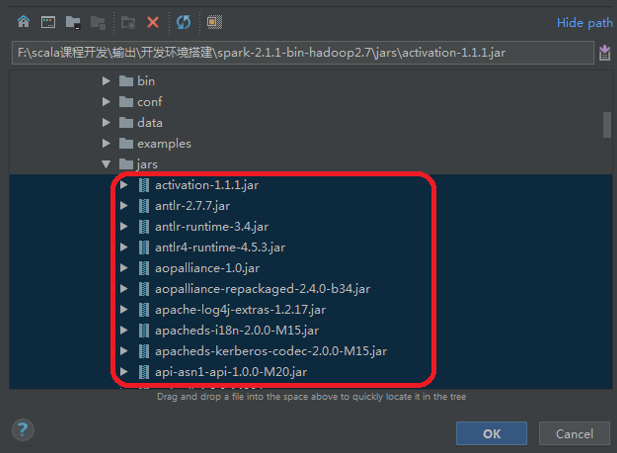
Step 6: 选择完成后进入“Choose Modules”界面,点击“OK”。
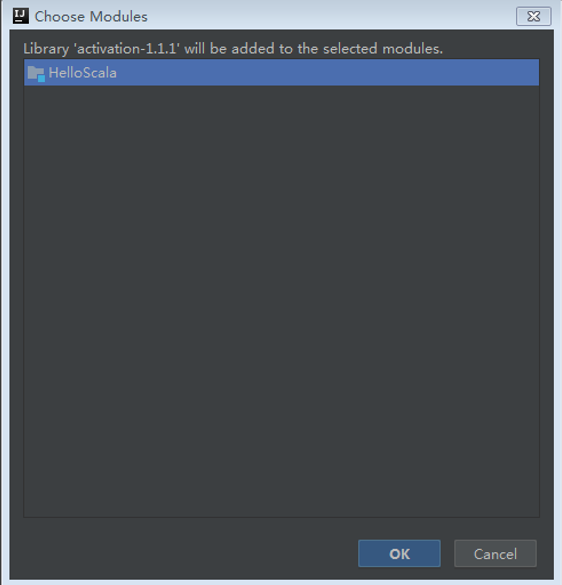
Step 7: 在“Project Structure”界面,更改库名为spark-lib,再点击“OK”

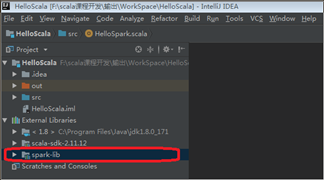
Step 8: 在Project树的“External Libraries”节点下出现 “spark-lib”节点,表示添加Spark成功。
5 验证Spark环境搭建
将以下文件拷贝到src目录下,然后右键运行
WordCount.scala
import org.apache.spark.{SparkConf, SparkContext} object WordCount { def main(args: Array[String]) { val conf = new SparkConf().setAppName("WordCount").setMaster("local") val sc = new SparkContext(conf) val textFile = sc.textFile("src/WordCount.scala") val counts = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)) .reduceByKey(_ + _) counts.foreach(println) sc.stop() } }
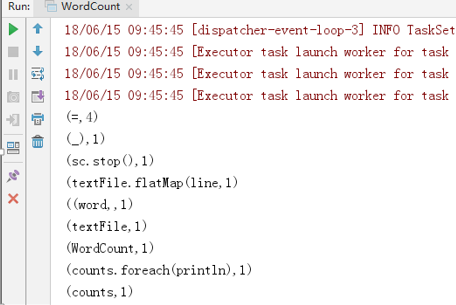
输出以下信息表示环境搭建成功
6 FAQ
6.1 java.lang.IllegalArgumentException: System memory 259522560 must be at least 4.718592E8. Please use a larger heap size.


解决办法
方法1:在创建SparkConf的语句后添加一行语句,
sparkConf.set("spark.testing.memory", "1073741824");
方法2:在如上个问题提到的VM Arguments中添加一行
-Dspark.testing.memory=1073741824
方法3:在VM Arguments中添加一行-Xmx1g
注意,上述方法中涉及的数字,是指Spark运行需要操作系统提供的内存大小(相当于提前预留好,实际中大多数可能没用上)。在默认情况下,Spark需要的内存为4G,如果机器能提供的内存小于4G,就会出现以上错误。所以在设置时,一定要保证设置的内存大小小于机器能提供的大小。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号