
第一次个人编程作业
作业要求
| 这个作业属于哪个课程 | 软件工程 |
|---|---|
| 这个作业要求在哪里 | 个人项目 |
| 这个作业的目标 | 设计论文查重算法,编写PSP表格,学习Github使用规范,编写单元测试 |
GitHub地址
https://github.com/CaiKunTai/CaiKunTai/tree/main/3121005073
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 600 | 720 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 100 |
| · Design Spec | · 生成设计文档 | 60 | 40 |
| · Design Review | · 设计复审 | 60 | 40 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 120 | 30 |
| · Coding | · 具体编码 | 120 | 210 |
| · Code Review | · 代码复审 | 30 | 90 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 60 |
| Reporting | 报告 | 150 | 180 |
| · Test Repor | · 测试报告 | 60 | 60 |
| · Size Measurement | · 计算工作量 | 60 | 90 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| · 合计 | 780 | 930 |
计算模块接口的设计与实现过程
1. 类与函数的定义
- read_file函数将文件路径作为输入,尝试打开文件并读取其内容。如果找不到该文件或发生任何其他异常,它将打印错误消息并退出程序。
- clean_text函数删除标点符号并将文本转换为小写,以确保对相似性计算进行一致的文本处理。
- calculate_silarity函数获取两个文本字符串,使用clean_text对其进行清理,然后使用使用difflib库的SequenceMatcher计算两个清理后的文本字符串之间的相似度。
- main函数中,脚本检查是否收到了正确数量的命令行参数(3个参数:原始文件路径、抄袭版论文的文件路径和答案文件路径)。如果没有,它将打印使用提示并退出。
2. 流程图

3.算法的关键以及独到之处 - 使用了 Python 的标准库中的 difflib 模块中的 SequenceMatcher 类来执行相似性比较,而不是手动实现相似性算法。
- 模块的代码结构非常简洁,易于理解和维护,适用于小规模的文本相似性比较任务。
- 命令行参数错误处理部分做了异常处理,使得模块具备一定的鲁棒性。
计算模块接口部分的性能改进
性能分析图
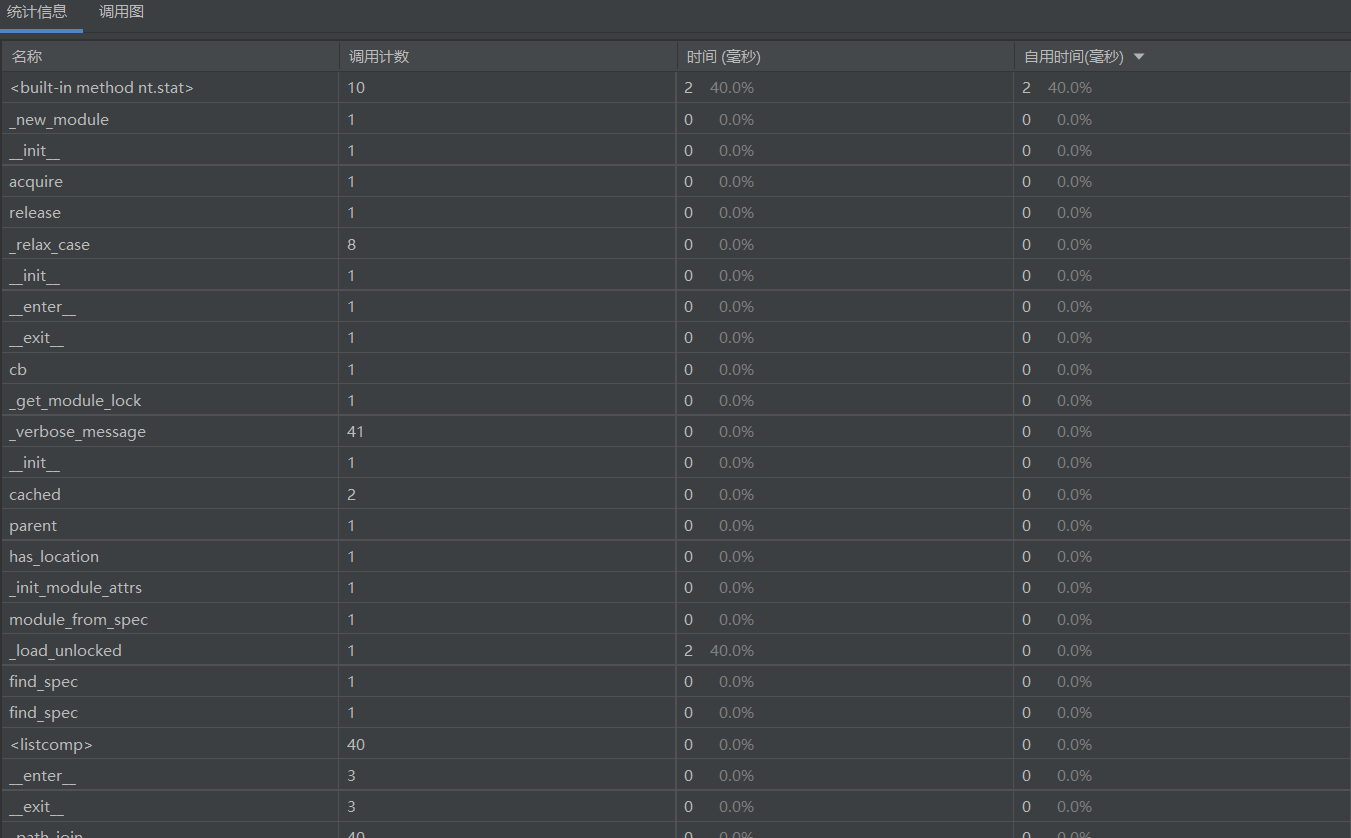
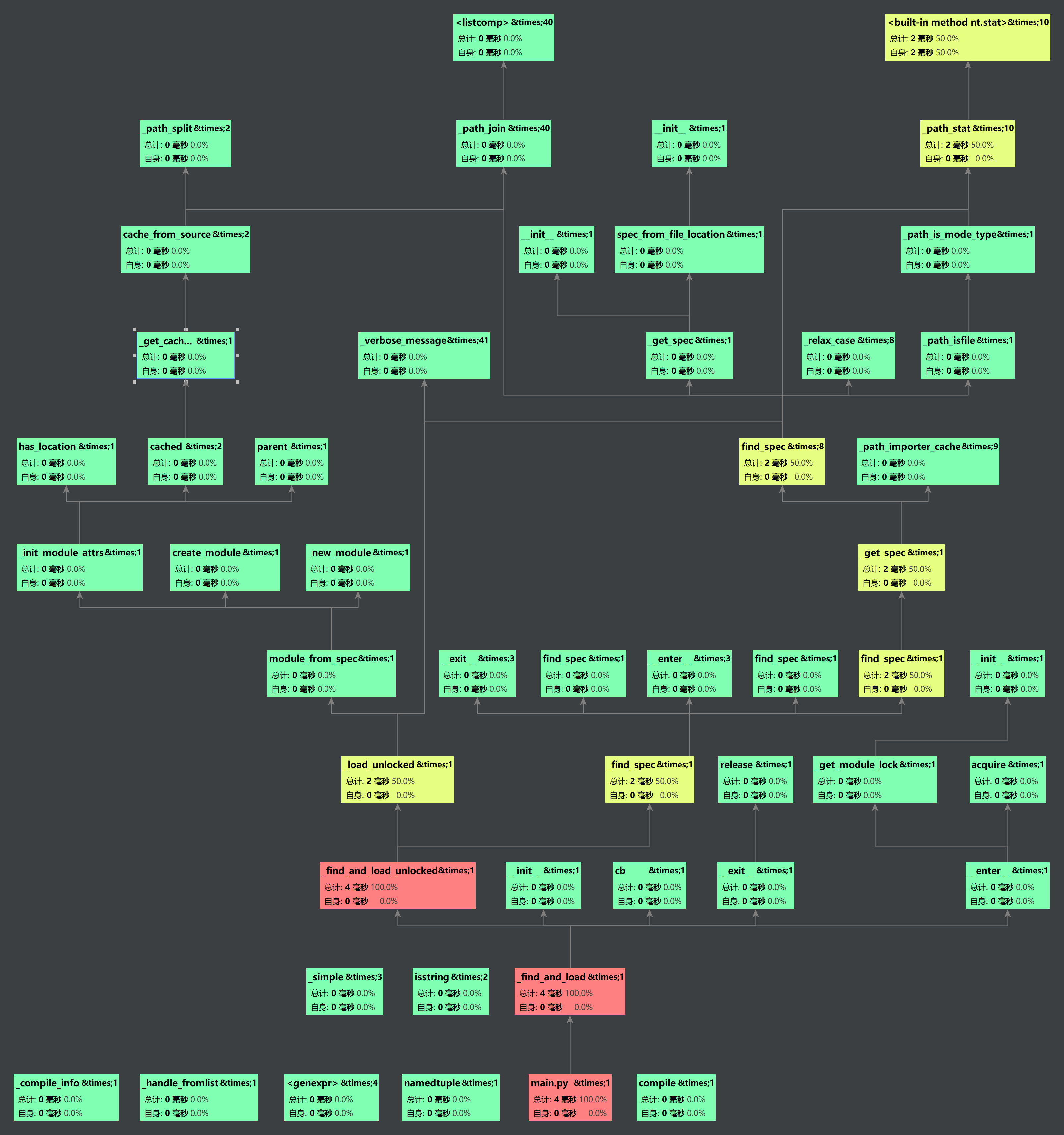
由性能分析图可以看出,消耗最大的函数是read_file函数,难以进行优化。
计算模块部分单元测试展示
1. 项目部分单元测试代码
- def setUp(self):在每个测试函数执行前创建一个临时测试文件
def setUp(self):
# 在每个测试函数执行前创建一个临时测试文件
self.temp_dir = tempfile.TemporaryDirectory()
self.original_file_path = os.path.join(self.temp_dir.name, 'original.txt')
self.copied_file_path = os.path.join(self.temp_dir.name, 'copied.txt')
with open(self.original_file_path, 'w', encoding='utf-8') as original_file:
original_file.write('This is a test file.')
with open(self.copied_file_path, 'w', encoding='utf-8') as copied_file:
copied_file.write('This is a test file.')
- test_read_file(self):测试文件读取功能
def test_read_file(self):
# 测试文件读取功能
# 测试正常情况
result = read_file(self.original_file_path)
self.assertEqual(result, 'This is a test file.')
# 测试文件不存在的情况
with self.assertRaises(SystemExit):
read_file('non_existent_file.txt')
# 测试文件内容为空的情况
empty_file_path = os.path.join(self.temp_dir.name, 'empty.txt')
with open(empty_file_path, 'w', encoding='utf-8') as empty_file:
pass
result = read_file(empty_file_path)
self.assertEqual(result, '')
- test_clean_text(self):测试文本清理功能
def test_clean_text(self):
# 测试文本清理功能
text = 'This is a test, with some punctuation and spaces!'
cleaned_text = clean_text(text)
self.assertEqual(cleaned_text, 'this is a test with some punctuation and spaces')
# 测试空文本的情况
empty_text = ''
cleaned_empty_text = clean_text(empty_text)
self.assertEqual(cleaned_empty_text, '')
- test_calculate_similarity(self):测试相似性计算功能
def test_calculate_similarity(self):
# 测试相似性计算功能
original_text = 'This is a test.'
copied_text = 'This is a test.'
similarity = calculate_similarity(original_text, copied_text)
self.assertEqual(similarity, 1.0) # 两个完全相同的文本,相似度应为1.0
original_text = 'This is a test.'
copied_text = 'This Is A Test.'
similarity = calculate_similarity(original_text, copied_text)
self.assertEqual(similarity, 1.0) # 两个仅大小写不同的文本,相似度应为1.0
original_text = 'This is a test.'
copied_text = 'This, is a test.'
similarity = calculate_similarity(original_text, copied_text)
self.assertEqual(similarity, 1.0) # 两个仅标点符号不同的文本,相似度应为1.0
original_text = 'This is a test.'
copied_text = 'This is not a test.'
similarity = calculate_similarity(original_text, copied_text)
self.assertLess(similarity, 1.0) # 两个不同的文本,相似度应小于1.0
# 测试空文本的情况
empty_text = ''
similarity = calculate_similarity(empty_text, empty_text)
self.assertEqual(similarity, 1.0) # 两个空文本,相似度应为1.0
# 测试一个文本为空的情况
original_text = 'This is a test.'
copied_empty_text = ''
similarity = calculate_similarity(original_text, copied_empty_text)
self.assertEqual(similarity, 0.0) # 一个文本为空,相似度应为0.0
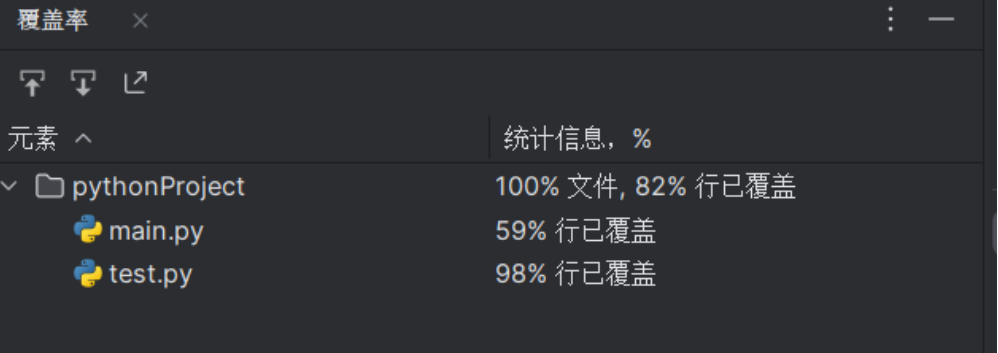
2. 测试覆盖率截图
计算模块部分异常处理说明
1.文件路径异常以及文件读取异常
def read_file(file_path):
try:
with open(file_path, 'r', encoding='utf-8') as file:
text = file.read()
return text
except FileNotFoundError:
print(f"文件 '{file_path}' 未找到。")
sys.exit(1)
except Exception as e:
print(f"读取文件 '{file_path}' 时发生错误: {str(e)}")
sys.exit(1)
2.输入参数数量异常
if len(sys.argv) != 4:
print("Usage: python plagiarism_checker.py <original_file_path> <copied_file_path> <output_file_path>")
sys.exit(1)

