

Pandas详解
Pandas是一个强大的分析结构化数据的工具集;它的使用基础是Numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能。
1、安装包
pip install pandas
2、数据结构
Pandas有三大数据结构,Series、DataFrame以及Panel。
- Series(一维数据)
- 它是一种类似于一维数组的对象,是由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据也可产生简单的Series对象。
- DataFrame(二维数据)
- DataFrame是Pandas中的一个表格型的数据结构,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame即有行索引也有列索引,可以被看做是由Series组成的字典。
- Panel(三维结构数据/面板数据)
2.1 DataFrame介绍
(1)DataFrame对象既有行索引,又有列索引
- 行索引,表明不同行,横向索引,叫index,0轴,axis=0
- 列索引,表名不同列,纵向索引,叫columns,1轴,axis=1
import numpy as np import pandas as pd stock_day_rise = np.random.normal(0,1,(20,25)) print(stock_day_rise) # 使用Pandas中的数据结构 # DataFrame(二维数据) stock = pd.DataFrame(stock_day_rise) print(stock)
增加列索引
# #构造列索引索引序列 data_columns=['one','two','three','four','five'] # # 添加列索引 data_column = pd.DataFrame(data, columns=data_columns) print(data_column)
增加行索引
使用pd.date_range():用于生成一组连续的时间序列
date_range(start=None,end=None, periods=None, freq='B') start:开始时间 end:结束时间 periods:时间天数 freq:递进单位,默认1天,'B'默认略过周末
# 增加行索引 # 生成一个行序列,略过周末 data_indexs = pd.date_range('2020-01-01', periods=data.shape[0], freq='B') # index代表行索引,columns代表列索引 datas= pd.DataFrame(data, index=data_indexs, columns=data_columns) print(datas)
(2)DatatFrame索引的设置
# 1、修改行列索引值 ## 修改行列索引值 datas.index[2] = "www" # 无法修改 # 通过整体修改,不能单个赋值 datas.index = [i for i in range(10)] # 重置索引 datas.reset_index(drop=True)
# 2、以某列值设置为新的索引 ## df.set_index(['one'])# 设置新的索引值,但是返回一个新的dataframe df = datas.set_index(['one']) print(df) # #设置多重索引 MultiIndex的结构 df = datas.set_index(['two', df.index]) print(df) ## 打印df的索引 print(df.index)
(3)DatatFrame的属性
-
shape
-
dtypes 查看数据类型
- ndim
- index
- columns
- values
- T
import numpy as np import pandas as pd data = np.random.rand(10,5) # index代表行索引,columns代表列索引 datas= pd.DataFrame(data, index=data_indexs, columns=data_columns) print(datas) print(datas.shape) #(10, 5) print(datas.dtypes) # 获取数据类型 # one float64 # two float64 # three float64 # four float64 # five float64 print(datas.ndim) # 2 print(datas.index) # 获取行索引值 print(datas.columns) # 获取列索引值 print(datas.values) # 获取Dataframe值 print(datas.T) # 行列翻转 print(datas.head(2)) # 获取前两行 print(datas.tail(2)) # 获取后两行
2.2 Series介绍
series结构只有行索引
(1)Series
# 指定内容,默认索引 ser = pd.Series(np.arange(10)) print(ser) # 指定索引 ser = pd.Series([6,7,5,3], index=["one","two","three","four"]) print(ser) # 通过字典数据创建 ser = pd.Series({'red':100, 'blue':200, 'green': 500, 'yellow':1000}) print(ser) # series获取属性和值 print(ser.index) print(ser.values) print(ser.shape)
3、基本数据操作
3.1索引操作
pandas的DataFrame的获取有三种形式
- 直接使用行列索引(先列后行)
- 结合loc或者iloc使用索引
- 使用ix组合索引
import numpy as np import pandas as pd data = np.random.rand(10, 5) # #构造列索引索引序列 data_columns = ['one', 'two', 'three', 'four', 'five'] # 生成一个行序列,略过周末 data_indexs = pd.date_range('2020-01-01', periods=data.shape[0], freq='B') datas = pd.DataFrame(data, index=data_indexs, columns=data_columns) print(datas) # 通过行列索引 print(datas['one']['2020-01-01']) # # 使用loc # loc:只能指定行列索引的名字(行,列) print(datas.loc['2020-01-01':"2020-01-03",'one']) # # # 使用iloc # # 使用iloc可以通过索引的下标去获取 print(datas.iloc[0:3, 0:2].head()) # # # 使用ix进行下表和名称组合做引 print(datas.ix[0:3, ['two', 'three']]) # 0不能省略 # # 相当于 print(datas[['one', 'two', 'three']][2:3])
3.2对于内容的操作
# 直接修改原来的值 datas['one'] = 1 datas['one']['2020-01-01'] = 100 # 或者 datas.one = 1 print(datas)
3.3排序
排序有两种形式,一种对于索引进行排序,一种对于内容进行排序
- 使用df.sort_values(默认是从小到大)
- 单个键进行排序
- 多个键进行排序
使用df.sort_index给索引进行排序
import numpy as np import pandas as pd data = np.random.rand(10, 5) # #构造列索引索引序列 data_columns = ['one', 'two', 'three', 'four', 'five'] # 生成一个行序列,略过周末 data_indexs = pd.date_range('2020-01-01', periods=data.shape[0], freq='B') datas = pd.DataFrame(data, index=data_indexs, columns=data_columns) # 按照one列进行排序 , 使用ascending指定按照大小排序 data = datas.sort_values(by='one', ascending=False) # print(data) # # # 按照过个键进行排序 data = datas.sort_values(by=['one', 'two']) print(data) # 对索引进行排序 datas.sort_index() print(datas)
4、 统计分析
count | Number of non-NA observations |
|---|---|
sum |
Sum of values |
mean |
Mean of values |
mad |
Mean absolute deviation |
median |
Arithmetic median of values |
min |
Minimum |
max |
Maximum |
mode |
Mode |
abs |
Absolute Value |
prod |
Product of values |
std |
Bessel-corrected sample standard deviation |
var |
Unbiased variance |
idxmax |
compute the index labels with the maximum |
idxmin |
compute the index labels with the minimum |
import numpy as np import pandas as pd data = np.random.rand(10, 5) # #构造列索引索引序列 data_columns = ['one', 'two', 'three', 'four', 'five'] # 生成一个行序列,略过周末 data_indexs = pd.date_range('2020-01-01', periods=data.shape[0], freq='B') datas = pd.DataFrame(data, index=data_indexs, columns=data_columns) print(datas) # describe 完成综合统计 # max 完成最大值计算 # min 完成最小值计算 # mean 完成平均值计算 # std 完成标准差计算 # idxmin 最小值的索引 # idxmax 最大值的索引 # cumsum 实现累计分析 # 计算平均值、标准差、最大值、最小值、分位数 print(datas.describe()) # 单独计算 print(datas['one'].max()) # 对所有的列进行计算 print(datas.max(0)) # 对所有的行进行计算 print(datas.max(1)) # 求出最大值的位置 print(datas.idxmax(axis=0)) # 求出最小值的位置 print(datas.idxmin(axis=1))
| 函数 | 作用 |
|---|---|
cumsum |
计算前1/2/3/…/n个数的和 |
cummax |
计算前1/2/3/…/n个数的最大值 |
cummin |
计算前1/2/3/…/n个数的最小值 |
cumprod |
计算前1/2/3/…/n个数的积 |
import numpy as np import pandas as pd data = np.random.rand(10, 5) # #构造列索引索引序列 data_columns = ['one', 'two', 'three', 'four', 'five'] # 生成一个行序列,略过周末 data_indexs = pd.date_range('2020-01-01', periods=data.shape[0], freq='B') datas = pd.DataFrame(data, index=data_indexs, columns=data_columns) print(datas) # 计算累计函数 print(datas.cumsum()) #计算累计函数 data = datas['one'] print(data.cumsum()) # plot方法集成了直方图、条形图、饼图、折线图 import matplotlib.pyplot as plt stock_rise.cumsum().plot() plt.show()
5、逻辑与算数运算
import numpy as np
import pandas as pd
data = np.random.rand(10, 5)
# #构造列索引索引序列
data_columns = ['one', 'two', 'three', 'four', 'five']
# 生成一个行序列,略过周末
data_indexs = pd.date_range('2020-01-01', periods=data.shape[0], freq='B')
datas = pd.DataFrame(data, index=data_indexs, columns=data_columns)
print(datas)
# 1、使用逻辑运算符号<、>等进行筛选
# 用true false进行标记,逻辑判断的结果可以作为筛选的依据
print(datas[datas['one'] > 0.5])
# 2、使用|、&完成复合的逻辑
# 完成一个符合逻辑判断, one > 0.5, two > 0.8
print(datas[(datas['one'] > 0.5) & (datas['two'] > 0.8)])
# 3、isin()
# 可以指定值0.622259进行一个判断,从而进行筛选操作
print(datas[datas['one'].isin([0.622259])])
print(datas.head(2))
# 4、数学运算
# 进行数学运算 加上具体的一个数字
data = datas['one'].add(1)
print(data)
# 自己求出每天 close- open价格差
# 筛选两列数据
one = datas['one']
two = datas['two']
# 默认按照索引对齐
datas['one-two'] = one.sub(two)
print(datas)
# 5、自定义运算函数
# 进行apply函数运算,DataFrame.apply() 函数则会遍历每一个元素,对元素运行指定的 function
data = datas[['one', 'two']].apply(lambda x: x.max() - x.min(), axis=0)
data2 = datas[['one', 'two']].apply(lambda x: x.max() - x.min(), axis=1)
print(data)
print(data2)
6、文件读取与存储
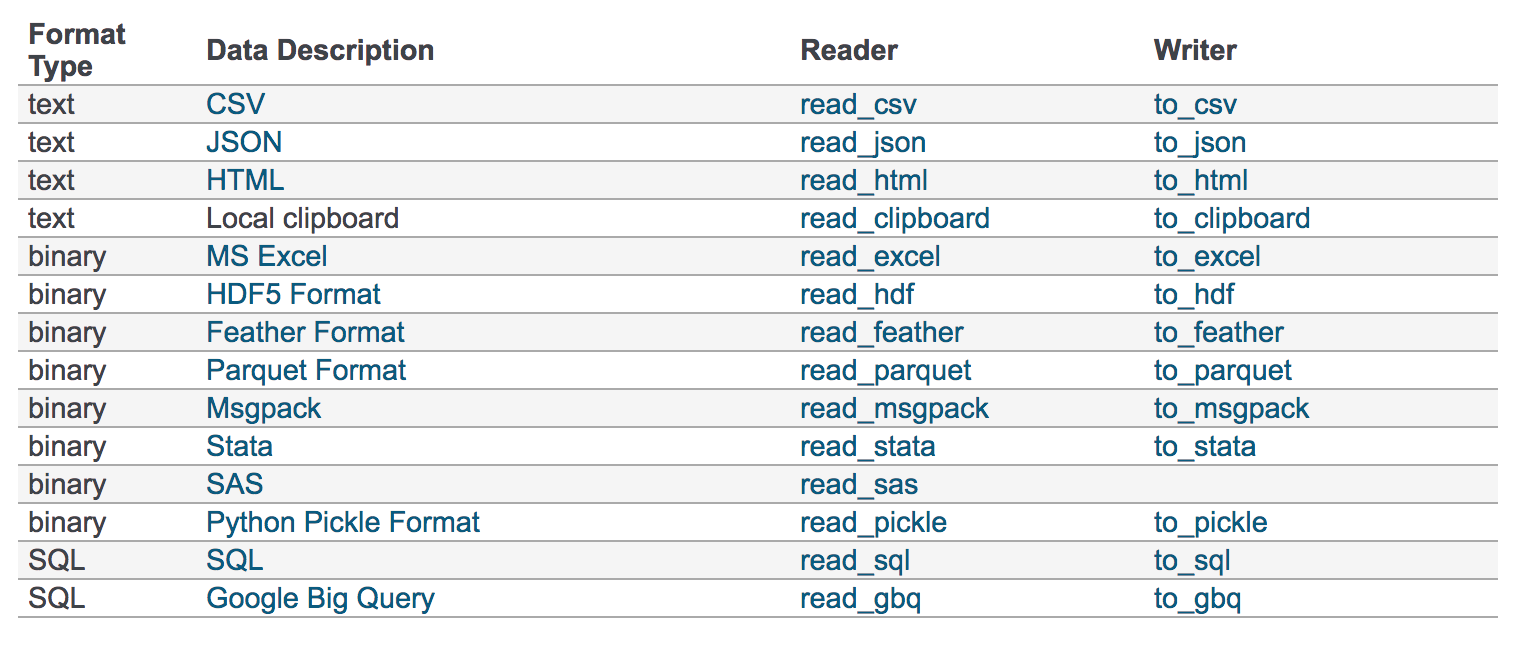
import pandas as pd # read_csv与to_csv # pandas.read_csv(filepath_or_buffer, sep =',' , delimiter = None) # filepath_or_buffer:文件路径 # usecols:指定读取的列名,列表形式 # 读取文件 data = pd.read_csv("./test/test.csv", usecols=['one', 'two']) # DataFrame.to_csv(path_or_buf=None, sep=', ’, columns=None, header=True, index=True, index_label=None, mode='w', encoding=None) # path_or_buf :string or file handle, default None # sep :character, default ‘,’ # columns :sequence, optional # mode:'w':重写, 'a' 追加 # index:是否写进行索引 # header :boolean or list of string, default True,是否写进列索引值 # 写文件 data[:10].to_csv("./test.csv", columns=['open'], index=True, mode='a', header=False)
困了,明天再写

