

【模板】后缀自动机 SAM、后缀树、广义后缀自动机
posted on 2022-08-07 20:50:14 | under 模板 | source
updated on 20230727:增补更多细节,合并广义 SAM 相关。
点击查看闲话
广义后缀自动机,建议看这篇理解会更深(口语化警告) <- 已经加入后缀自动机豪华套餐
保存:基本子串结构 https://www.cnblogs.com/crashed/p/17382894.html 2023 xtq
炫酷后缀树魔术 https://www.luogu.com.cn/blog/EternalAlexander/xuan-ku-hou-zhui-shu-mo-shu
众所周知,后缀自动机有 但是明天模拟赛要考,所以要学习一下。
感谢 @sshwy 的课件。/bx
UPD:考了,不会。
后缀自动机
后缀自动机(Suffix Automaton,SAM)是一种有限状态自动机,接受字符串
概念
在后缀自动机中,每一个状态对应着
- Endpos 集合:
- 等价类:一个等价类中的所有子串都有着完全一致的
- 包含类:若两个等价类
- Link 指针 / 后缀链接:所有状态都有 Link 指针(根状态没有),它们构成一棵 Link 树,在 Link 树上状态
- 转移指针
构造(理解一)
现在开始构造后缀自动机,我们使用增量构造法,现在我们有了
首先新建状态节点
- 哪些状态会转移到
令
重新看一遍
那么怎么更新
- 更新
- 若
上面的我看不懂,照抄了黄队课件,Orz
构造(理解二)
现在开始增量构造。假如我们有一个
对于一个出现位置,有颜色的部分,是可能的子串左端点。显然
广义 SAM 相关
这里不对什么东西进行证明,只说正确的。广义 SAM 其实就是插入新的字符串时令
code
注意双倍空间!
SAM
template<int N,int M=26> struct suffixam{
int tot,ch[N*2+10][M],link[N*2+10],len[N*2+10],siz[N*2+10],last;
suffixam():tot(1),last(1){memset(ch,0,sizeof ch),memset(siz,0,sizeof siz),len[1]=link[1]=0;}
void expand(int r){
int u=++tot,p=last;last=u;
len[u]=len[p]+1,siz[u]=1;
while(p&&!ch[p][r]) ch[p][r]=u,p=link[p];
if(!p) return void(link[u]=1);
int q=ch[p][r];
if(len[q]==len[p]+1) return void(link[u]=q);
int cq=++tot;memcpy(ch[cq],ch[q],sizeof ch[cq]);
len[cq]=len[p]+1,link[cq]=link[q];
link[u]=link[q]=cq;
while(p&&ch[p][r]==q) ch[p][r]=cq,p=link[p];//不要写错!
}
};
广义 SAM
template <int N, int M>
struct suffixam {
int ch[N << 1][M], tot, link[N << 1], len[N << 1];
suffixam() : tot(1) {
len[1] = link[1] = 0;
memset(ch[1], 0, sizeof ch[0]);
}
int split(int p, int q, int r) {
if (len[q] == len[p] + 1) return q;
int u = ++tot;
len[u] = len[p] + 1;
memcpy(ch[u], ch[q], sizeof ch[0]);
link[u] = link[q];
link[q] = u;
for (; p && ch[p][r] == q; p = link[p]) ch[p][r] = u;
return u;
}
int expand(int p, int r) {
if (ch[p][r]) return split(p, ch[p][r], r);
int u = ++tot;
len[u] = len[p] + 1;
memset(ch[u], 0, sizeof ch[0]);
for (; p; p = link[p]) {
if (ch[p][r]) {
link[u] = split(p, ch[p][r], r);
return u;
} else {
ch[p][r] = u;
}
}
link[u] = 1;
return u;
}
};
广义 SAM 使用 `unordered_map` 存转移边(这个代码很慢,除非字符集大小不可接受否则不应选用,若字符串总长过大考虑换用 map)
template <int N>
struct suffixam {
unordered_map<int, int> ch[N << 1];
int tot, link[N << 1], len[N << 1];
suffixam() : tot(1) {
ch[1].clear();
len[1] = link[1] = 0;
}
int split(int p, int q, int r) {
if (len[q] == len[p] + 1) return q;
int u = ++tot;
len[u] = len[p] + 1;
ch[u] = ch[q];
link[u] = link[q];
link[q] = u;
for (; p && ch[p][r] == q; p = link[p]) ch[p][r] = u;
return u;
}
int expand(int p, int r) {
if (ch[p][r]) return split(p, ch[p][r], r);
int u = ++tot;
len[u] = len[p] + 1;
ch[u].clear();
for (; p; p = link[p]) {
if (ch[p][r]) {
link[u] = split(p, ch[p][r], r);
return u;
} else {
ch[p][r] = u;
}
}
link[u] = 1;
return u;
}
template <bool rev>
vector<int> bucketsort() {
vector<int> per(tot), buc(tot + 1);
for (int i = 1; i <= tot; i++) buc[len[i]] += 1;
for (int i = 1; i <= tot; i++) buc[i] += buc[i - 1];
for (int i = 1; i <= tot; i++) per[--buc[len[i]]] = i;
if (rev) reverse(per.begin(), per.end());
return per;
}
};
更多代码参见 https://www.cnblogs.com/caijianhong/p/18153828/solution-UOJ577
最后可能需要用到得到
点击查看代码
//method 1:暴力建图 dfs
LL dfs(int u,int fa=0){
LL ans=0;
for(int i=g.head[u];i;i=g.nxt[i]){
int v=g[i].v; if(v==fa) continue;
ans=max(ans,dfs(v,u)),t.siz[u]+=t.siz[v];
}
if(t.siz[u]>1) ans=max(ans,1ll*t.siz[u]*t.len[u]);
return ans;
}
for(int i=2;i<=t.tot;i++) g.add(t.link[i],i);
//method 2:拓扑排序
int q[N*2+10],inn[N*2+10];
LL toposort(){
int L=1,R=0;LL ans=0;
for(int i=1;i<=tot;i++) inn[link[i]]++;
for(int i=1;i<=tot;i++) if(!inn[i]) q[++R]=i;
while(L<=R){
int u=q[L++];
siz[link[u]]+=siz[u];
if(siz[u]>1) ans=max(ans,1ll*siz[u]*len[u]);
if(--inn[link[u]]==0) q[++R]=link[u];
}
return ans;
}
//method 3:桶排序求拓扑序
int per[N*2+10],buc[N*2+10];
LL toposort(){
memset(buc,0,sizeof buc);
for(int i=1;i<=tot;i++) buc[len[i]]++;
for(int i=1;i<=tot;i++) buc[i]+=buc[i-1];
for(int i=tot;i>=1;i--) per[buc[len[i]]--]=i;
LL ans=0;
for(int i=tot;i>=1;i--){
int u=per[i];
if(siz[u]>1) ans=max(ans,1ll*siz[u]*len[u]);
siz[link[u]]+=siz[u];
}
return ans;
}
要求得
后缀树
我们考虑一个无脑的东西:后缀树。它把
SAM 与后缀树的联系
我们有定理:
反串 SAM 的 Link 树是其正串的后缀树。
简单推论:反串 SAM 向下跳
那么所有概念都清晰了:
- 等价类:后缀树上一个关键点和上方的非关键点。(不建虚树)
- 包含类:后缀树上的祖先。
- 增量构造:例如原串
bbaba,插入字符b,实际上就是反串前面插入这个字符,即在后缀树上插入bababb。
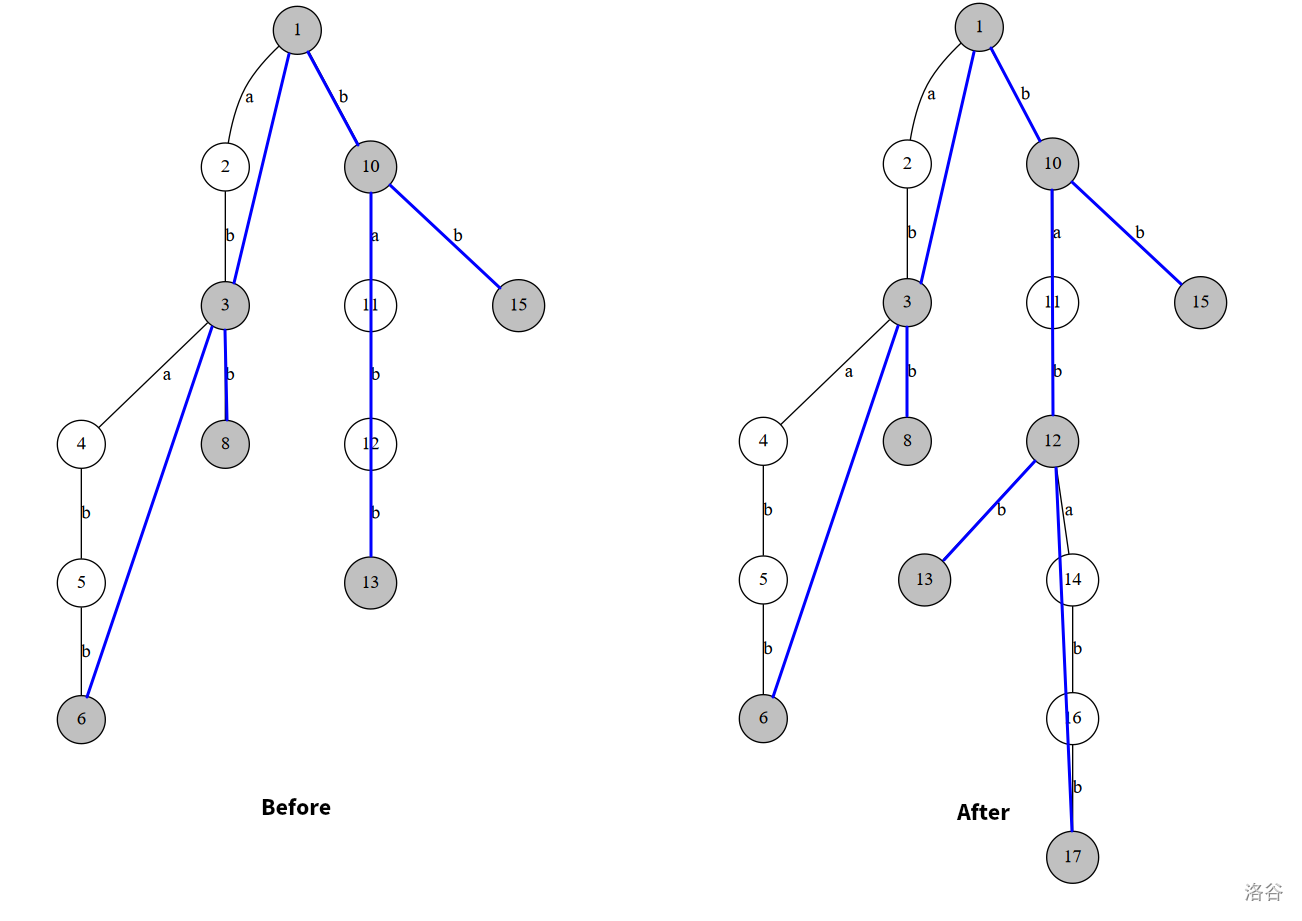
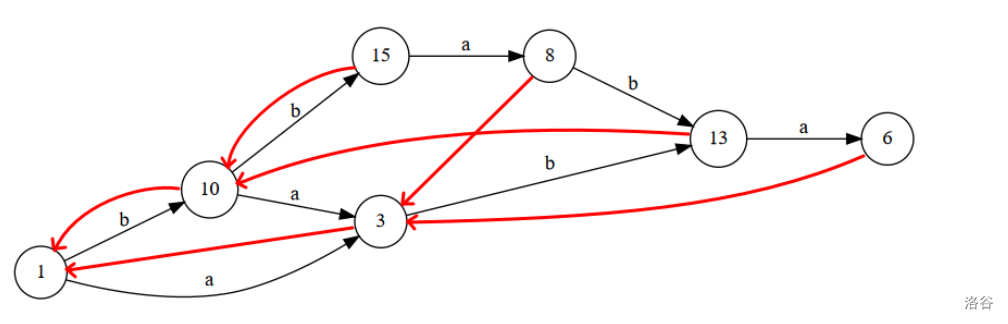
一模一样。
那么它们有什么区别?其实没有(如果不涉及什么匹配),正串 SAM 是在 Link 树上搞事情,反串 SAM 是在 Trie 树上搞事情。
SAM 建立后缀树
在 SAM 的代码中,我们用到了几个数组,它们有对应的后缀树的含义:
| 数组 | SAM | 后缀树 |
|---|---|---|
| 原后缀树上 |
||
(注:
如果想求得后缀树上
- 建反串 SAM,记录
- 连边:
SAM 与后缀树的互换
其实可以这样说:正串 SAM 维护的是
各种自动机的比较
除了子序列自动机,我们现在见过的自动机有 ACAM(字符串匹配)、SAM(后缀自动机)、PAM(回文自动机)。它们的相同点是:状态转移集都形成一个 DAG。
| 自动机 | 状态集合 | Link 树(若 |
|---|---|---|
| SAM | 原串的所有子串 | 则等价类 |
| ACAM | 所有字符串的前缀 | 则前缀 |
| PAM | 所有回文串 | 则回文子串 |
简单应用
全都离不开 DAG 和 Link 树,二选一进行 DP 或匹配,甚至两个一起。基本子串结构将这些东西有机联合,见 https://www.cnblogs.com/crashed/p/17382894.html 对它的基本介绍。(据说原文是 2023 年许庭强论文)
两个后缀的 LCP
反串 SAM:后缀树上这两个后缀的 LCA 的深度。停停,怎么找这两个后缀?
for(int i=n;i>=1;i--) ap[i]=s.expand(a[i]-'a',ap[i+1]);
这样
同理我们可以找到前缀的最长公共后缀:正着做一遍就是了。
求
正串 SAM 上等价类的
具体说一下这个等价类怎么找:
如果是反串 SAM 呢?反过来就行了。
int locate(int l,int r){
int len=r-l+1,u=pos[r];
for(int j=20;j>=0;j--) if(s.len[fa[j][u]]>=len) u=fa[j][u];
return u;
}
本质不同的子串个数
这里注意到这个串是正串还是反串答案都不变。
- SAM,
- 反串 SAM,原后缀树的每一个点对应一个子串,那么两个关键点之间的所有点加起来就是子串个数。
- 正串 SAM,每个等价类中最长长度为
- SAM,DAG 上 DP,倒推,
最小表示法
倍长并使用正串 SAM,即寻找 SAM 中字典序最小的长为
- 反串 SAM,建出
求 dfn 序,求相邻两个不同字符串的后缀的 LCP。就是找一个点,使得它的子树中既有来自 - 考虑建出
- 考虑对
第二种方法就是字符串匹配,由此我们可以使用广义 SAM 薄纱 ACAM(虽然要乘个字符集是个大问题)
另外说一下怎么删字符,非常简单,
本质不同第
输出字符串
正串 SAM。我们将子串看作 DAG 上的一条路径,那么第
输出区间
对着 DAG 做链剖分,比较阴间,展开说说。考虑向重链剖分一样,对于每个点选出重儿子
有一个例题 ABC280H 是没有本质相同的,有另外一种后缀数组做法,这里说的 SAM 做法也能过。(如果用下一节说的后缀排序还原后缀树那么可以线性遍历树,和后缀数组一样了)
点击查看代码
https://atcoder.jp/contests/abc280/submissions/43972309
void print(int u,int len){printf("%d %d %d\n",ep[u].first,ep[u].second-len+1,ep[u].second);}
void solve(int u,LL x,int len){
for(int j=18;j>=0;j--) if(x>g[j][u]){
if(x-g[j][u]<=f[to[j][u]]) x-=g[j][u],u=to[j][u],len+=1<<j;
}
if(x<=siz[u]) return print(u,len);
x-=siz[u];
for(int i=0;i<26;i++){
int v=s.ch[u][i];
if(x<=f[v]) return solve(v,x,len+1);
else x-=f[v];
}
}
void init(){
m=s.tot;
iota(p+1,p+m+1,1);
sort(p+1,p+m+1,[&](int i,int j){return s.len[i]<s.len[j];});
for(int j=m;j>=1;j--){
int u=p[j]; int*ch=s.ch[u],son=0;
siz[s.link[u]]+=siz[u],ep[s.link[u]]=ep[u],f[u]=siz[u];
for(int i=0;i<26;i++) if(ch[i]) f[u]+=f[ch[i]];
for(int i=0;i<26;i++) if(f[ch[son]]<f[ch[i]]) son=i;
g[0][u]=siz[u],to[0][u]=ch[son];
for(int i=0;i<son;i++) g[0][u]+=f[ch[i]];
}
for(int j=1;j<=18;j++){
for(int i=1;i<=m;i++) to[j][i]=to[j-1][to[j-1][i]];
for(int i=1;i<=m;i++) g[j][i]=g[j-1][i]+g[j-1][to[j-1][i]];
}
}
询问的时候记得加 siz[1] 哦
后缀排序
那这位更是重量级,学会了可以薄纱后缀数组。方法就是还原后缀树。
- 建反串 SAM,记录
- 连边:
- dfs 树,按照边的字典序,先访问到的
- 和 SA 一样求出
点击查看代码
https://uoj.ac/submission/646959
//split pos[u]=pos[q];
//expand pos[u]=now
void dfs(int u){
if(key[u]) sa[rnk[pos[u]]=++cnt]=pos[u];
for(int i=0;i<26;i++) if(to[u][i]) dfs(to[u][i]);
}
void gethei(){
for(int i=1,k=0;i<=n;i++){
if(rnk[i]==1) continue;
int j=sa[rnk[i]-1]; k=max(k-1,0);
while(max(i,j)+k<=n&&a[i+k]==a[j+k]) k++;
hei[rnk[i]]=k;
}
}
int main(){
scanf("%s",a+1),n=strlen(a+1);
for(int i=n,last=1;i>=1;i--) key[last=s.expand(a[i]-'a',last,i)]=1;
for(int i=2;i<=s.tot;i++) to[s.link[i]][a[pos[i]+s.len[s.link[i]]]-'a']=i;
dfs(1),gethei();
for(int i=1;i<=n;i++) printf("%d%c",sa[i]," \n"[i==n]);
for(int i=2;i<=n;i++) printf("%d%c",hei[i]," \n"[i==n]);
return 0;
}
基本子串结构
https://www.cnblogs.com/caijianhong/p/18153828/solution-UOJ577
本文来自博客园,作者:caijianhong,转载请注明原文链接:https://www.cnblogs.com/caijianhong/p/template-suffixam.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现