
UE4内存分配器介绍与ptmalloc对比
UE4内存分配器介绍与ptmalloc对比
内存体系结构
-
我们都知道原生的libc提供了malloc、alloc、realloc、free等内存分配相关的函数。
-
在UE4自己也封装了一套相关的内存分配器的实现,并且提供了多个不同的内存分配器,这些内存分配器的基类是FMalloc类,其中提供了几个基本的内存分配函数与Free释放函数。
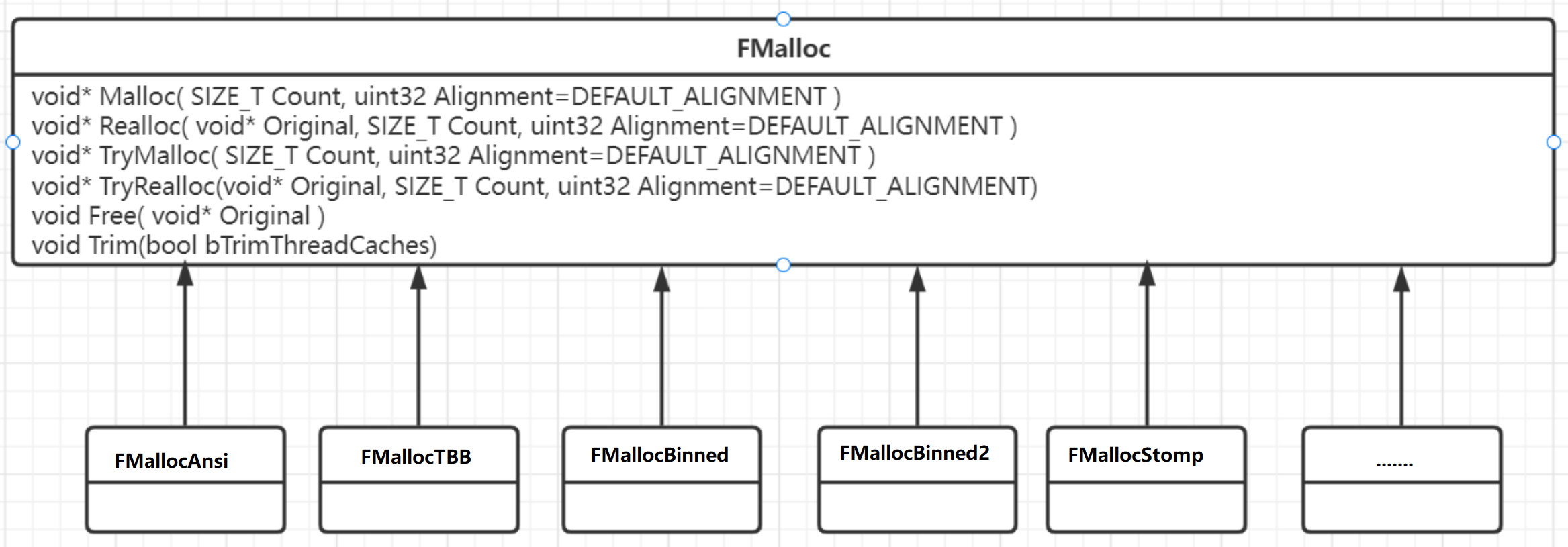

-
如下图是UE4的内存分配体系架构,可以看出来UE4的内存管理都是基于这些内存分配器实现的,而这些内存分配器是基于最基本的系统调用VirtualAlloc、mmap实现的。
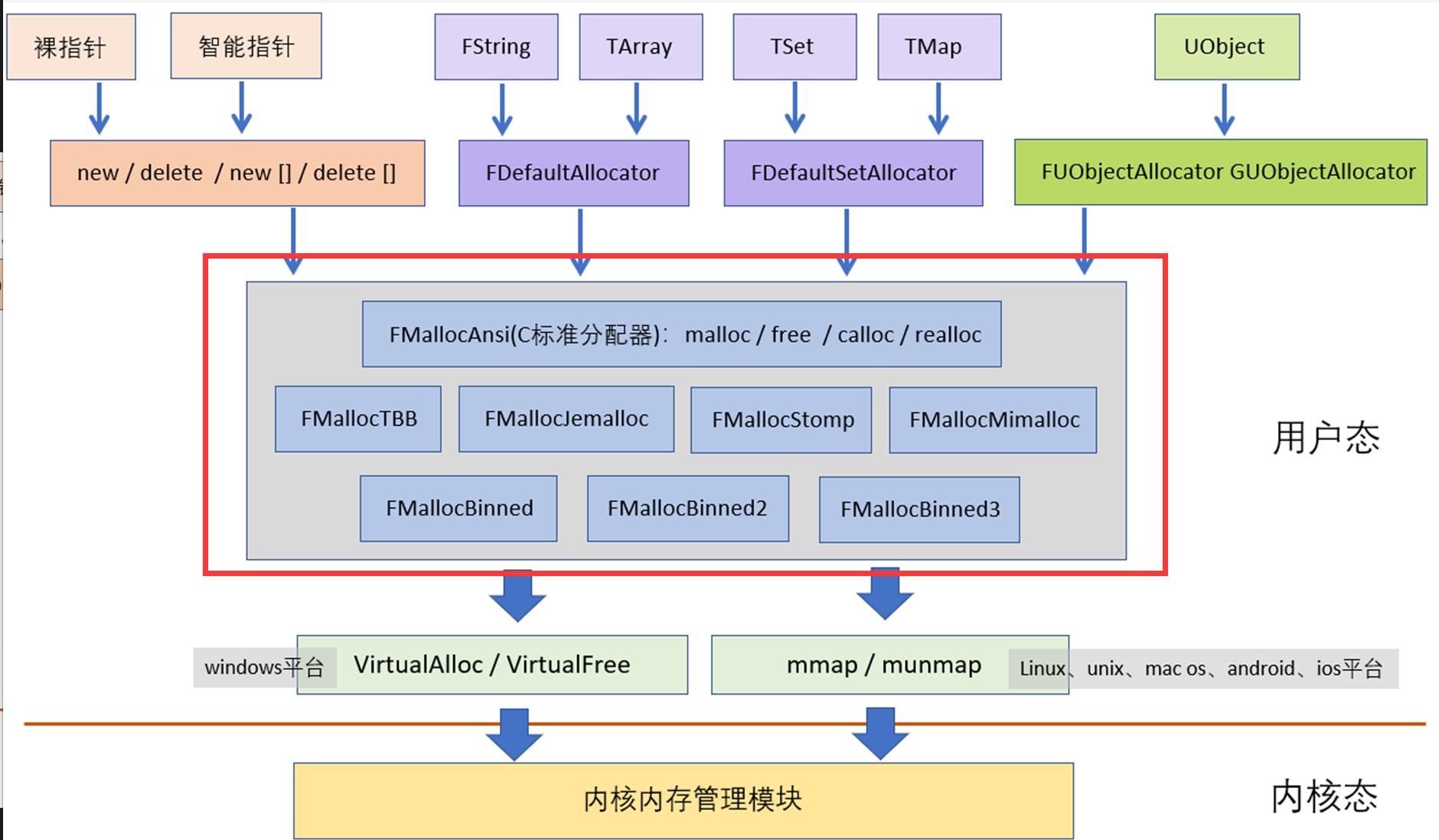
-
每个平台都有适用于自己的内存管理器
| Ansi | TBB | jemalloc | Binned | Binned2 | Binned3 | Mimalloc | Stomp | |
|---|---|---|---|---|---|---|---|---|
| Android | 支持 | 支持 | 默认 | 支持(64) | ||||
| IOS | 支持 | 默认 | 支持 | 支持 | ||||
| Windows | 支持 | 默认 | 支持 | 默认 | 支持(64) | 支持 | ||
| Linux | 支持 | 支持 | 支持 | 默认 | 支持 | |||
| Mac | 支持 | 默认 | 支持 | 支持 | 支持 | |||
| HoloLens | 支持 | 默认 |
-
不同内存管理器的特点
Ansi内存分配器(标准C):直接调用malloc、free、realloc函数TBB(Thread Building Blocks)内存分配器:Intel 提供的第三方库的一个可伸缩内存分配器(Scalable Memory Allocator)
Jemalloc内存分配器(Linux / FreeBSD):适合多线程下的内存分配管理 http://www.canonware.com/jemalloc/
Stomp:用于查非法内存操作(如:内存越界,野指针)的管理方式,目前只支持windows、mac、unix等pc平台。带命令行参数-stompmalloc来启用该分配器
内存管理对象的初始化
UE4内存管理通过创建一个全局的管理器: GMalloc。在引擎初始化,第一次内存分配时,会调用以下FMemory_GCreateMalloc_ThreadUnsafe函数对GMalloc进行初始化。
static int FMemory_GCreateMalloc_ThreadUnsafe(){
...
GMalloc = FPlatformMemory::BaseAllocator();
...
}
可以看到,GMalloc的初始化调用到了FPlatformMemory这个类的BaseAllocator函数。FPlatformMemory是一个定义,在不同平台下有不同的定义,例如在Windows下:
//WindowsPlatformMemory.h
...
struct CORE_API FWindowsPlatformMemory
: public FGenericPlatformMemory
{
...
}
typedef FWindowsPlatformMemory FPlatformMemory;
类似的,在安卓下FPlatformMemory是FAndroidPlatformMemory的别名……
这些内存管理类都继承FGenericPlatformMemory类,其实这个内存管理类不仅提供了初始化内存分配器的接口,还为内存分配器提供了BinnedAllocFromOS、BinnedFreeToOS等接口。

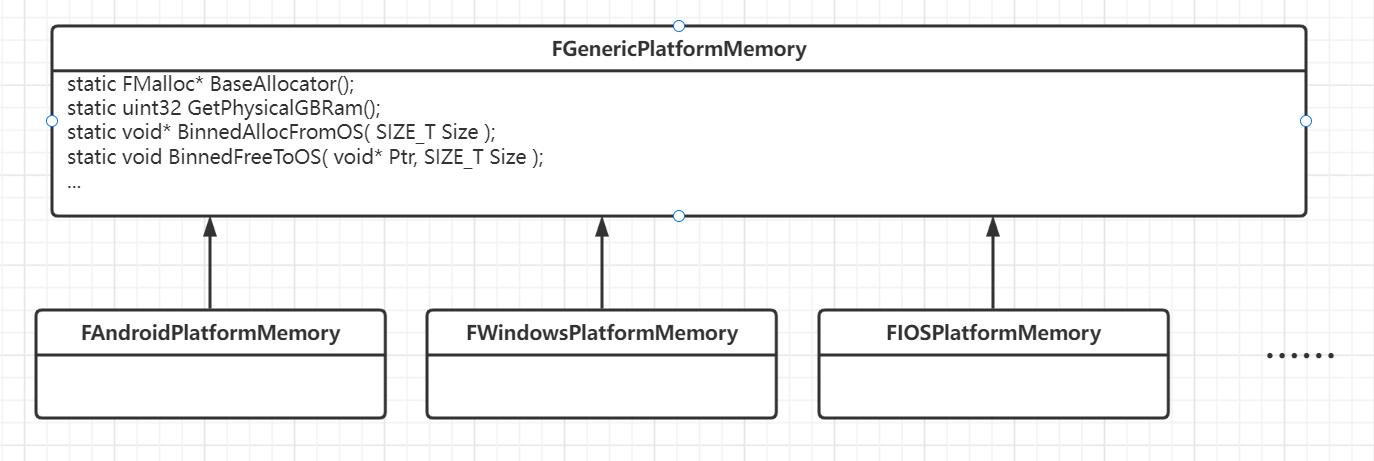
Binned内存分配器讲解
Binned内存分配器对小内存进行管理,大的内存直接调用操作系统的接口进行申请和释放。UE4提供了40多种不同大小的内存池进行管理,(Size大小不在表里的,向上取最近值)。
static const uint32 BlockSizes[POOL_COUNT] =
{
16, 32, 48, 64, 80, 96, 112, 128, //单位都是byte
160, 192, 224, 256, 288, 320, 384, 448,
512, 576, 640, 704, 768, 896, 1024, 1168,
1360, 1632, 2048, 2336, 2720, 3264, 4096, 4672,
5456, 6544, 8192, 9360, 10912, 13104, 16384, 21840, 32768
};
Binned内存分配器数据结构
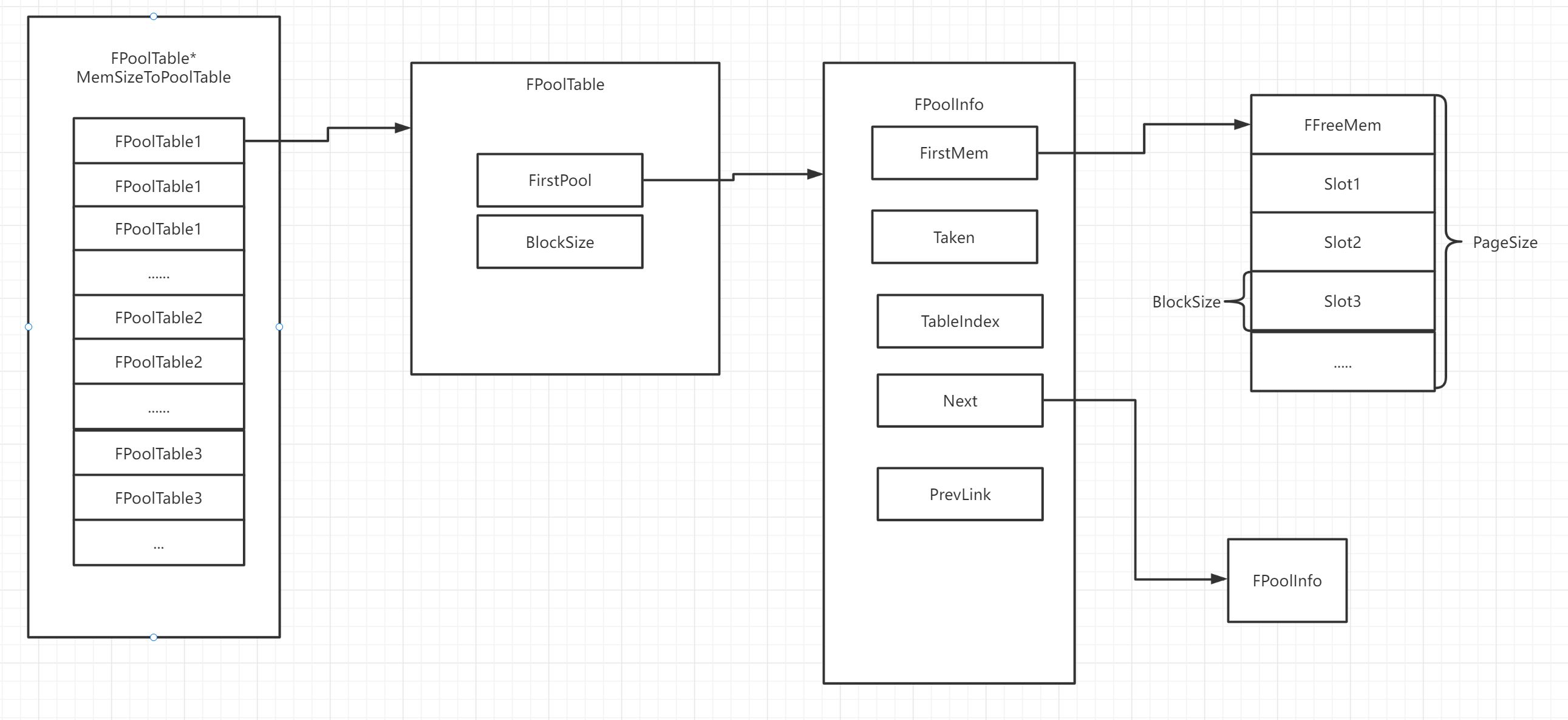
要想理解Binned内存分配器,就要理解其中内存块的数据结构,总结如图所示:

-
MemSizeToPoolTable:是一个FPoolTable数组,将不同大小Size映射到对应的FPoolTable。MallocBinned的初始化主要就是对所有PoolTable的初始化和MemSizeToPoolTable的初始化。
-
FPoolTable:管理一类大小槽位的Pool
- FPoolInfo* FirstPool:指向可用的Pool。
- FPoolInfo* ExhaustedPool:指向已满的Pool。
- uint32 BlockSize 该内存池管理的内存块大小
-
FPoolInfo:用来管理一个Pool,同一个PoolTable中的PoolInfo使用双向链表链接起来。(PoolInfo实例使用HashBuckets管理)
- uint16 Taken: Pool中已分配的元素数量,减为0时可释放pool中的FFreeMem内存,Pool会从FPoolTable里面踢除,但是不会立即释放,会缓存起来。
- FFreeMem* FirstMem:指向Pool中可用槽位的起始地址,如果PoolInfo描述操作系统直接分配的大内存块,这个值存储分配的大小。
- FPoolInfo* Next:指向下一个PoolInfo
- FPoolInfo* PrevLink:指向前一个PoolInfo
- uint16 TableIndex:首次用该Pool存储数据时,槽位内分配的内存大小(并不是Index)
-
FFreeMem:描述了一块可分配内存,虽然位于Pool的内存块头部,但是不占分配内存。FFreeMem在被分配之后会完全归属调用者,不占用内存。(只有未被分配的内存块才会存储FFreeMem的数据,被分配后的块会全部被应用程序管理)
- FFreeMem* Next:下一个可用槽位
- uint32 NumFreeBlocks:连续空闲槽位的数量。
- 这个数据结构在初始的时候可以看做是一个简单的数组,随着程序释放运行的过程会退化成链表的结构,一些设计细节这里并不多讲。
- FFreeMem是几个连续的内存块组成,其所有内存块之和为操作系统的一个页。由于是直接通过系统调用申请的,所以地址页对齐,起始地址的最后16位都是0。
-
HashBuckets:
- 一个哈希表,把FFreeMem的起始地址与FPoolInfo对应。
- 主要功能是可以在释放指针的时候可以直接通过内存地址来寻找其对应的PoolInfo便于释放。
- 刚才提到FFreeMem的起始地址以0x0000结尾,所以每个指针被释放的时候可以通过地址位运算来直接找到到起始FFreeMem,进而找到FPoolInfo。
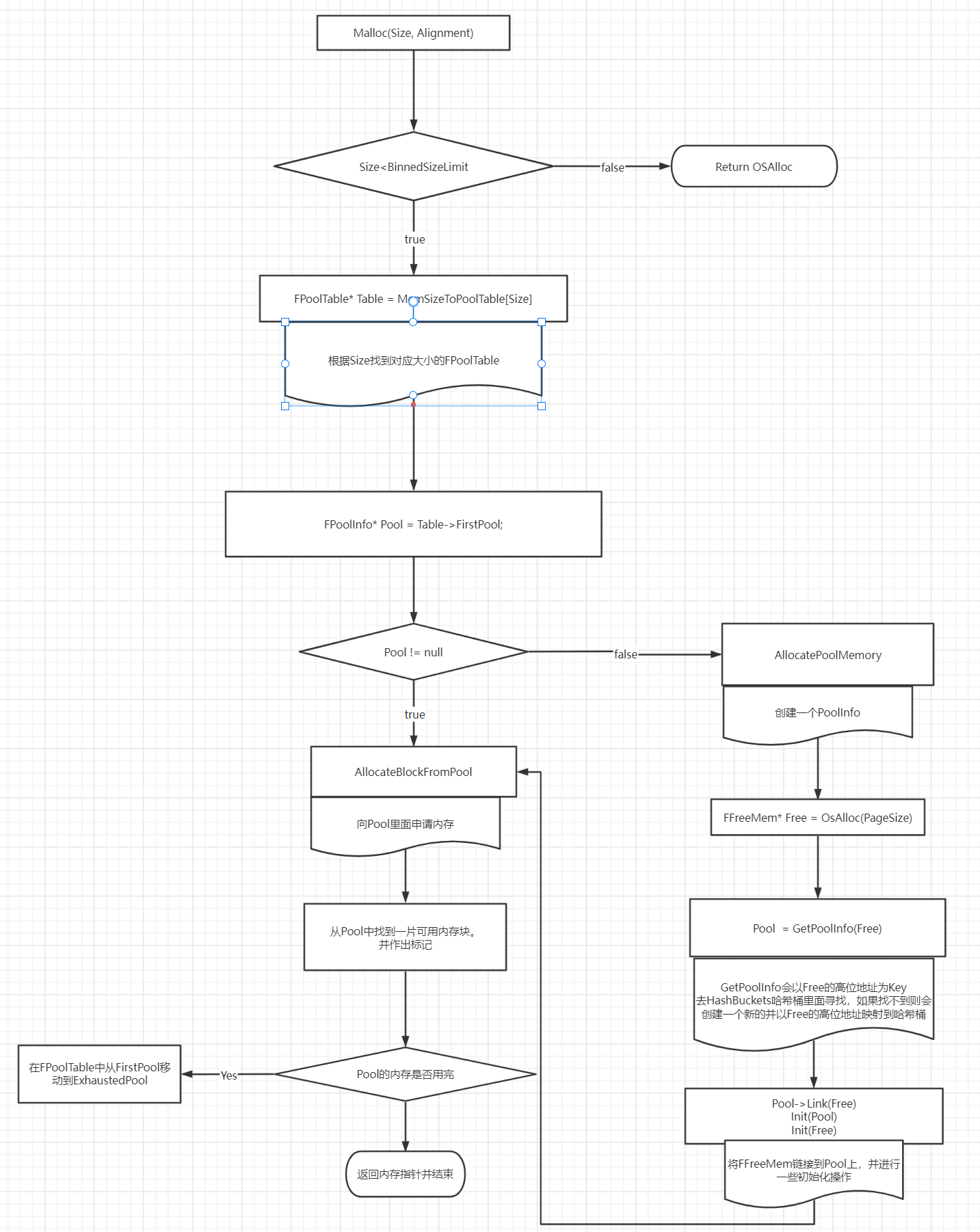
Malloc申请内存主要流程
理解完内存分配器的结构模型之后,对申请内存的流程便会很轻松理解:
注:本图和Malloc的实际流程有一些偏差,其中忽略了一些细节与优化的部分,仅仅表达了主要流程。
申请内存主要先在Size对应的PoolTable里面寻找到可用的Pool,如果没有就创建一个。每个Pool里面存了1页大小的内存,每次从中间申请对应大小的内存块。
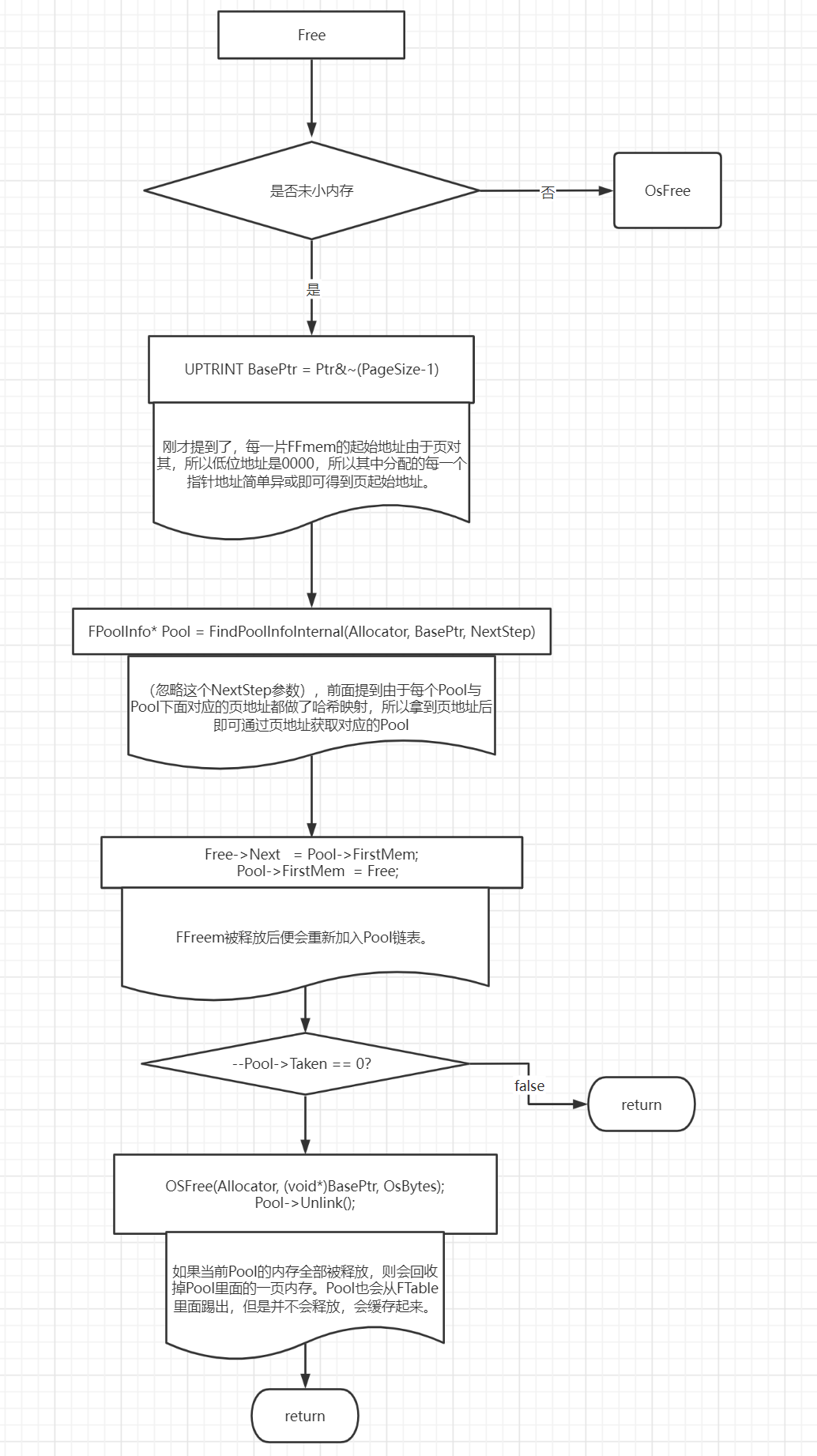
Free释放流程
内存释放流程整体相对简单,主要理解一点:被释放的指针要先通过位运算找到页起始地址,然后在通过页起始地址找到对应的Pool。
MallocBinned的优缺点简单分析
注:该一下分析只是通过算法特性来进行简单的分析,其中主要以个人观点为主,还没有进行测试试验。
优点:
-
MallocBinned在分配大量Size相近的内存块时表现良好。
- 从数据结构中看出Binned分配器会尽量的把内存大小相似的内存块放在同一页上,由于操作系统的缓存机制经常访问同一页的内存效率会更高一些。
- 由于内存相似度比较高的内存片公用一个内存池,所以在此情况下Binned的内存利用率会更高一些。
-
申请速度比较快,在大部分分配内存的情况下,每一次内存分配,Binned只是简单的从固定内存池里面找到一块可用的内存,没有做过多的操作;及时偶尔内存池不够用了,重新申请一篇内存池也并没有太高的消费。整体下来每一次操作都是稳定O(1)的。
-
无外部内存碎片,binnned内存分配器不会出现无法利用到的零散的内存碎片。(如果外部碎片过多,内存就会变得难以管理)。
缺点:
- 与优点相对,Binned在申请内存分布及其不均匀的情况下表现不太良好,极端情况下可能每个指针都要占领1页的内存,这样不仅内存利用率极其低下,内存访问效率也不是很友好。
- 内部碎片较多。在申请513、1025大小的内存时候,由于并没有恰好合适的内存池,只能从大一点的内存池中分配内存,导致一些内存浪费。
glibc内存分配器讲解
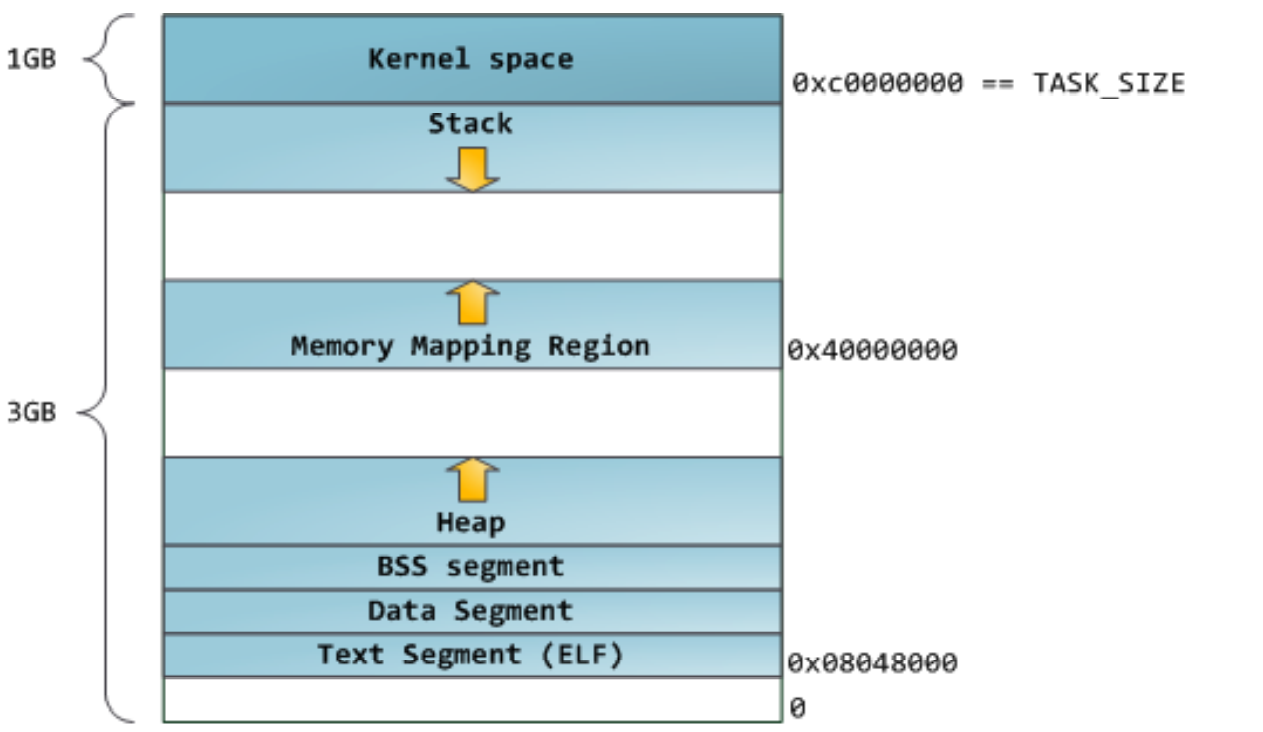
X86 平台 Linux 进程内存布
由于glibc是linux下的c语言库,所以想要了解glibc的内存分配器就要了解Linux中进程的内存布局。
如图所示是一个 X86平台Linux32位下进程默认内存布局,64位会更大一些,但是差不多。
Kernel space:储存操作系统相关的一些数据
Stack:栈区,C语言运行过程中局部变量的存储位置,即用即回收。
MMemory Mapping Region:使用mmap分配此片内存,可以用于文件映射,也可以直接分配操作系统物理页直接使用(在glibc中用于大内存的分配)。
Heap:堆区,在glibc中用于管理动态申请的小片内存。
bss段(bss segment):通常用来存放程序中未初始化的全局变量的一块内存区域。
data段:数据段(data segment)通常是指用来存放程序中已初始化的全局变量的一块内存区域。数据段属于静态内存分配。
text段:代码段(code segment/text segment)通常是指用来存放程序执行代码的一块内存区域。这部分区域的大小在程序运行前就已经确定,并且内存区域通常属于只读(某些架构也允许代码段为可写,即允许修改程序)。在代码段中,也有可能包含一些只读的常数变量,例如字符串常量等。

brk、sbrk和mmap、munmap
brk和sbrk的功能差不多,都是改变heap顶部的位置,可以指定向上增长,也可以指定向下减少。移动的目的是将程序虚拟地址映射到内存,但是移动brk只是简单的映射并没有实际申请物理页,只有真正访问该片内存时候才会实际分配物理页。
mmap和munmap在linux中有文件映射的功能,但是在内存管理器中我们可以简单的理解他只是简单的从memory maping region中申请和释放一片内存。(申请大小会页对齐)。
基本的数据结构
和ue4的内存分配器类似,glibc的内存分配器也只是对小内存指定,大内存走的是另一套系统(mmap)。而小内存使用brk和sbrk来管理。
-
chunk:用户申请分配的内存都以一个chunk来表示:
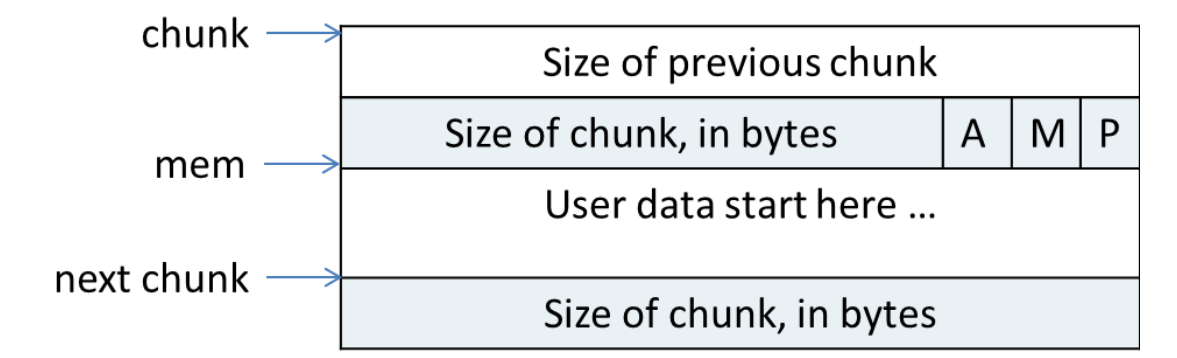
-
Bin:被用户free掉的内存不会立刻还给操作系统,而是会存在来放到链表中,每个链表称为一个bin。其中小于512k的叫做small bins,大于512k的叫做large bins。二者的区别在于申请不足的内存块是largebins会将内存块分割后返回(如果程序要申请600b的内存,但是bin里面只提供了640大小的内存,这时候会分割成600+40两块内存,并将600的返回给程序,40的放到unsorted bin里面)。:

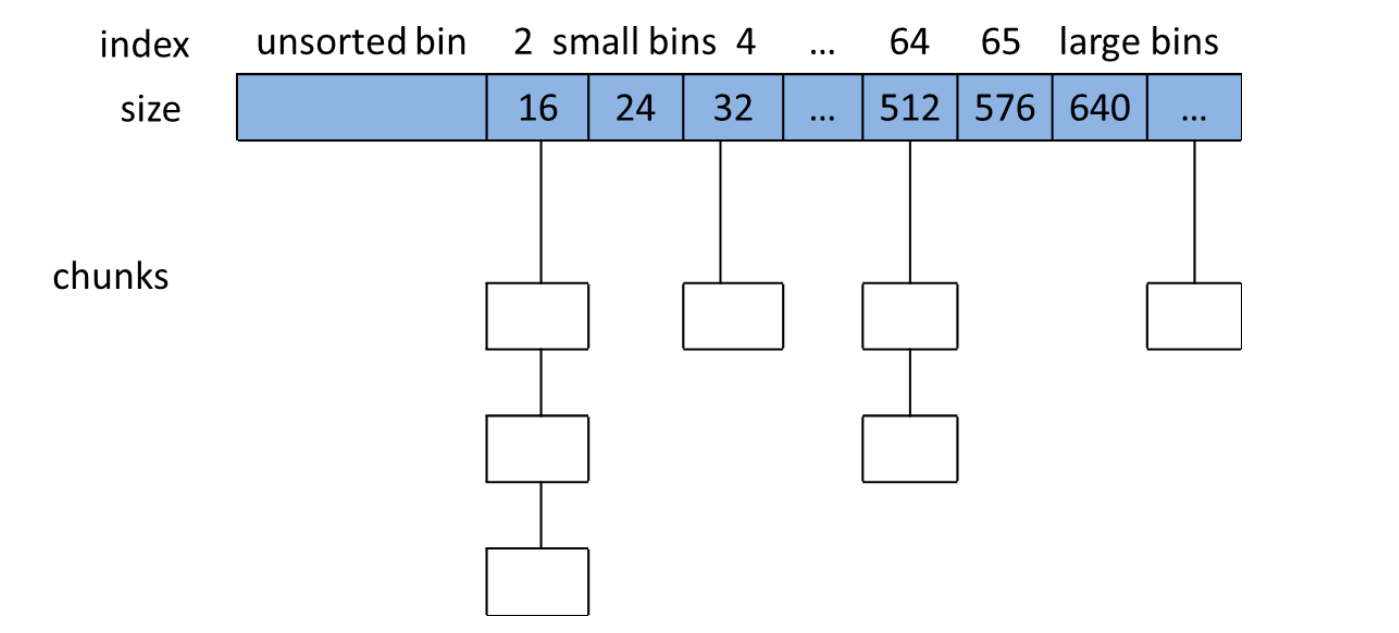
ptmalloc
-
UnsortedBin
Bin数组的第一个,存储了不同大小的内存块。可以看做是Bin的一个缓存区。 -
Top chunk
永远在堆顶的一个空闲chunk块,如果释放的内存和top chunk相邻,则会合并到topchunk,如果topchunk超过一定大小,则会释放这片内存并栈顶指针下移。
ptmalloc申请、释放内存流程
这里没有看源码,只是通过一些资料了解了简单的流程并绘制此图。
ptmalloc申请内存流程如图所示
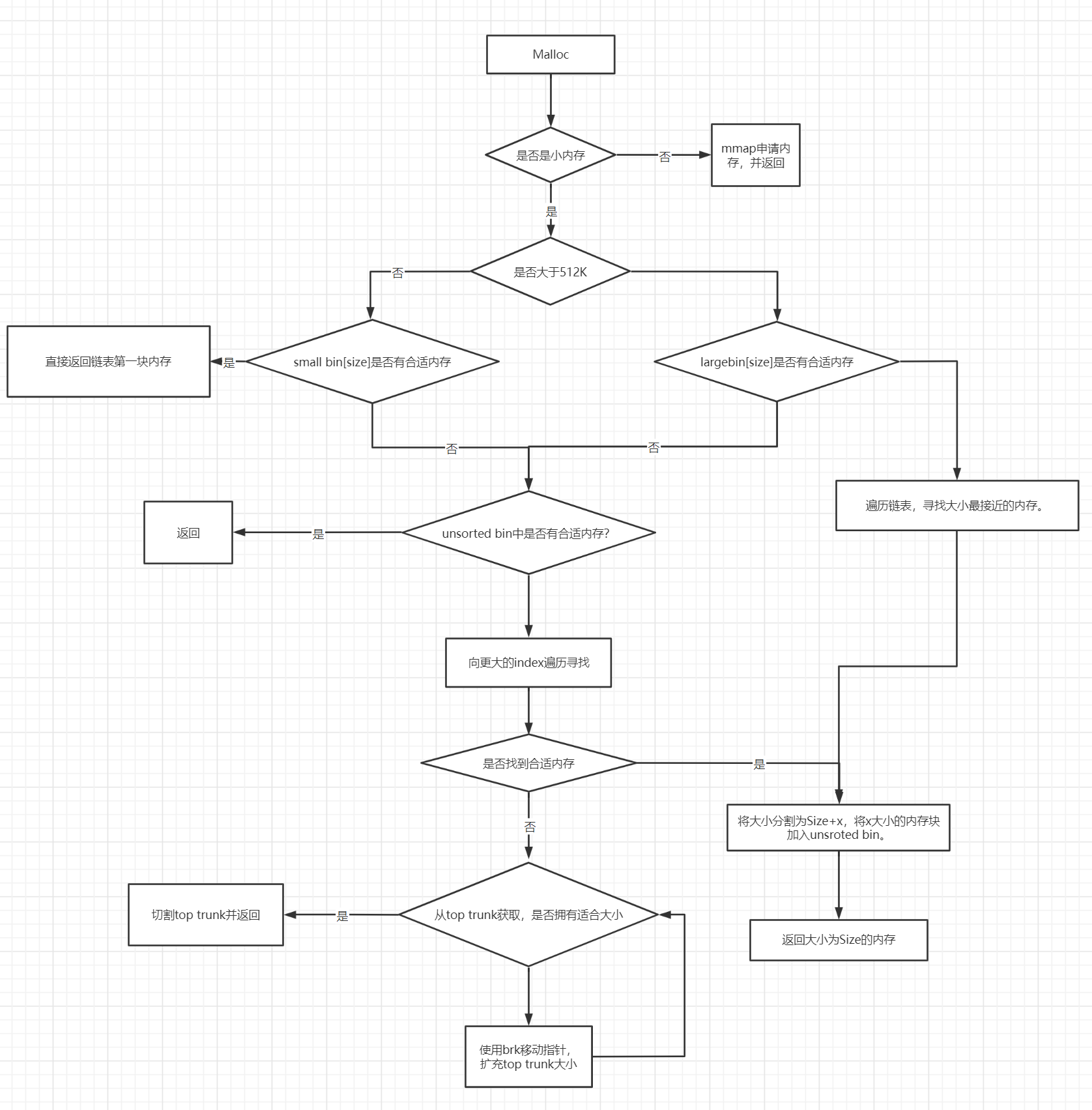

相对于申请内存来说,释放内存的过程比较简单
- chunk和top chunk相邻,则和top chunk合并。如果此时top chunk足够大,则调用brk移动堆顶指针,减少堆内存占用。
- chunk和top chunk不相邻,则直接插入到unsorted_list中
ptmalloc优缺点分析
优点:
- 作为基础的库,ptmalloc相对来说通用性更强一些,对各种大小内存分配都比较适配。
- 由于回收内存的操作比较少,所以回收内存的效率也比较高。
缺点:
- 虽然开始的时候ptmalloc分配的内存是从堆中一个个取得,但是随着程序得内存申请和释放,返回得内存地址就会变得非常不连续,局部缓存性也会比较差。
- 在管理长周期对象时,如果对象地址恰好在堆顶会很容易产生内存空洞,中间很大一部分内存即使被程序释放了也无法返还给操作系统。
- 在分配内存时,由于流程过于复杂,极端情况下要遍历很多链表,导致ptmalloc申请内存的时候也非常不友好。
总结与反思
MallocBinned和pt_malloc对比
这些对比只是看简单的算法实现下的猜测,并没有实际的数据验证,所以仅供参考。
参考《glibc内存管理ptmalloc源代码分析》中对内存管理器的设计目标,对内存管理器的评价需要考虑以下内容:
- 最大化兼容性:这个不作对比。
- 最大化可移植性:不作对比
- (内存管理器本身)浪费最小的空间:虽然mallocbinned中数据结构参数众多,并没有对单个内存块单独做数据结构进行维护。所以这点我觉得应该是mallocbinned更优一些。
- (内存分配、释放)最快的速度:由于UE4在申请内存时候的流程并没有涉及太多的遍历操作,每个步骤都是稳定O(1)的,所以Mallocbinned更优。
- 最大化局部性:由于UE4会尽量把相同大小的内存块放到同一页上,glibc分配的内存块相对散乱,所以UE4更优一些。
- 最大化调试功能:不做比较
- 最大化适应性(通用性):前面提到了,由于glibc身为基础的内存分配器,通用性相对更好一些。
问题解答
Q1:为什么有这么多的内存分配器,我们直接调用操作系统的接口来分配内存不好吗?
A:主要原因有两点:
- 首先当前流行的操作系统大部分都是段页式管理,操作系统底层接口都是以页来分配的,所以需要有一个东西把这些内存管理起来。
- 操作系统提供的内存分配接口都是系统调用,总所周知系统调用的耗费是比较大的,malloc作为一个高频率调用的函数自然不能频繁的进行系统调用,所以自然要用池机制缓存起来。
Q2:UE4为什么要自己造轮子?
A:这个问题的解释有很多,这里选择几点进行说明。
- 虽然现在很多基础的C语言函数库都提供了很优秀的内存管理器,但是因为UE4要考虑到各种设备,所以自己也提供了一套内存管理器。
- 因为很多基础C语言库中的内存分配器都很优秀,但是大部分因为需要考虑到通用性这个点折损了太多东西。相对来说UE4可以不用考虑太多的通用性。
- 除了效率之外,UE4自己提供内存分配器更是方便了自己做内存跟踪、内存检查等功能。
- 另外UE4不仅提供了自己的内存分配器,而且提供了相关的参数以便选择,可以为用户结合自己的项目提供更多的选择。
反思
了解了Binned这么多东西,有没有哪些知识可以对项目带来什么帮助呢?
这个问题需要不断的思考与试验,目前有一个想法是,binned目前提供的四十多个大小的内存池中,每个blocksize都是UE4自定的。关于这个点我觉得我们可以根据项目中每个内存块的大小来计算一下我们选择哪些blockSize比较合适,比如我们项目中如果大量申请336b大小的内存,那我们是否可以单独加一个336b大小的blocksize。但是这些想法还需要不断验证。
参考资料
-
《glibc内存管理ptmalloc源代码分析》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号