JMeter压测
如果未来要迈向高级工程师,压测就是必备的技能之一,只有测试阶段进行了反复的压测及优化,最终投入生产环境才会更安全可靠,这样的团队才会更被客户单位所认可。
JMeter用法#
安装其实挺简单,为了方便演示,我直接Windows上安装了,后面生产环境用法会讲Linux下安装,官网相关地址如下。
1)、官网:jmeter.apache.org/
2)、下载:jmeter.apache.org/download_jm…
3)、用户手册:jmeter.apache.org/usermanual/…
1、安装
1)、下载
2)、解压
解压后在bin目录双击jmeter.bat打开,界面如下。
2、使用
1)、添加线程组
测试计划右键-添加-Threads(Users)-线程组
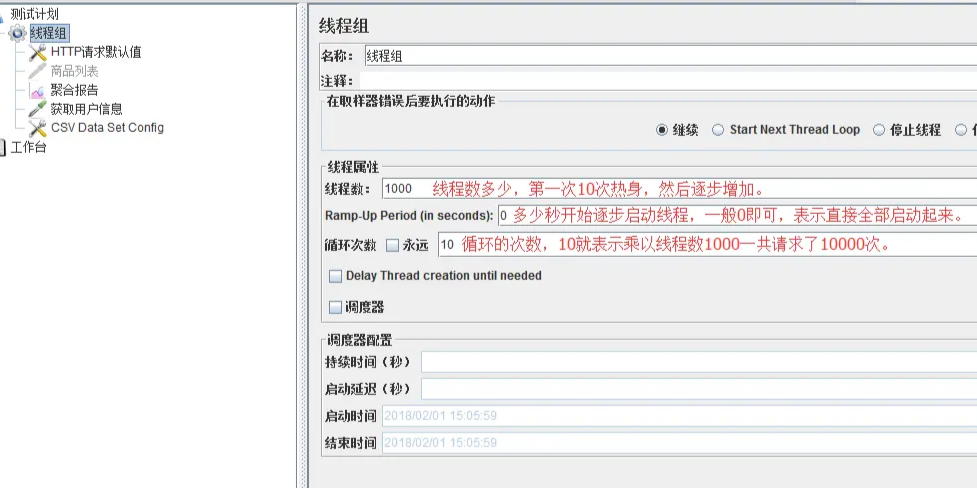
线程组配置看图片中红字说明
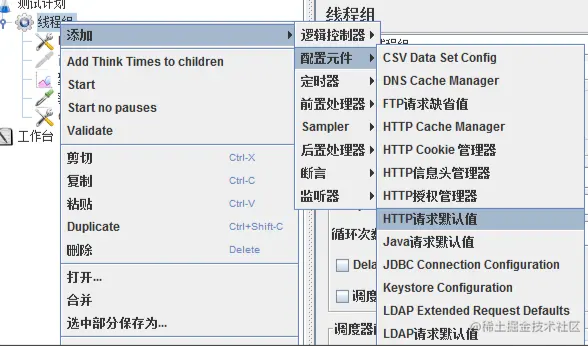
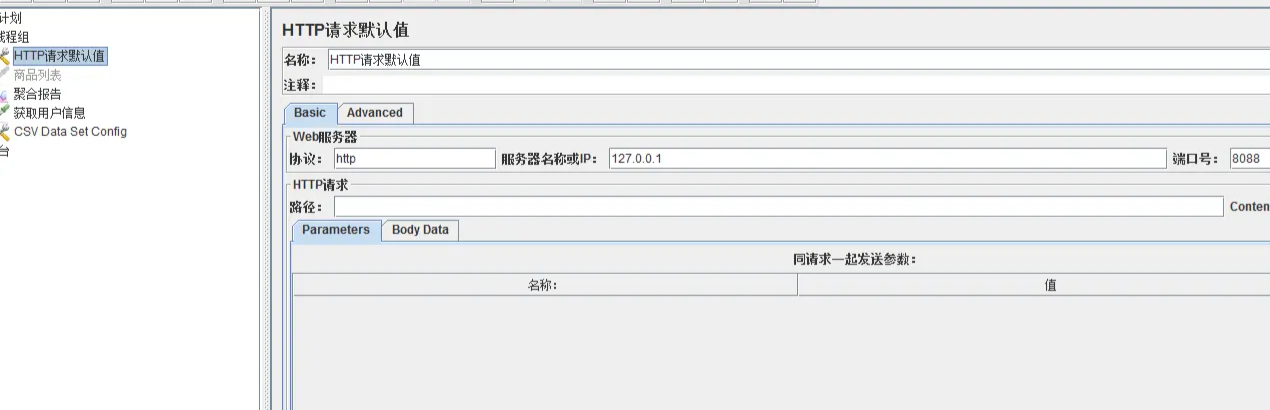
2)、HTTP请求默认值
线程组右键-添加-配置元件-HTTP请求默认值,设定一个默认的路径,之后就不用每个地方都重写一遍了。
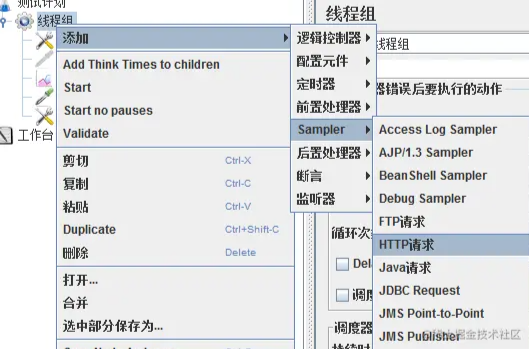
3)、添加HTTP请求
线程组右键-添加-Sampler-HTTP请求,新建一个拿来压测的请求URL及参数。
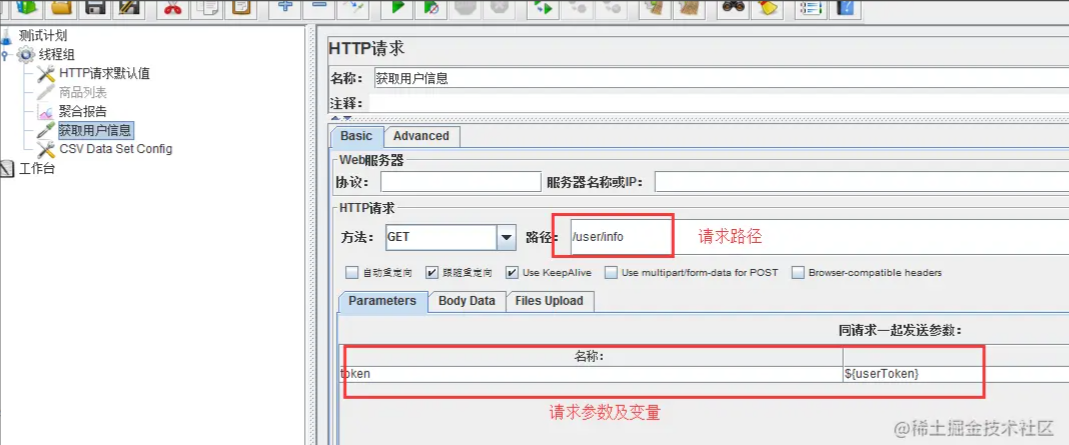
这里参数给的是变量,变量名对应后面的配置文件,用${XXX}这样的形式写入。
目的是,模拟多个用户发出这个请求,即有多个user和多个token写入cookie,如:
userId1,userToken1
userId2,userToken2
userId3,userToken3
设置请求路径及变量如图所示
4)、模拟多用户请求
这里需要用到变量,线程组右键-添加-配置元件-CSV Data Set Config。
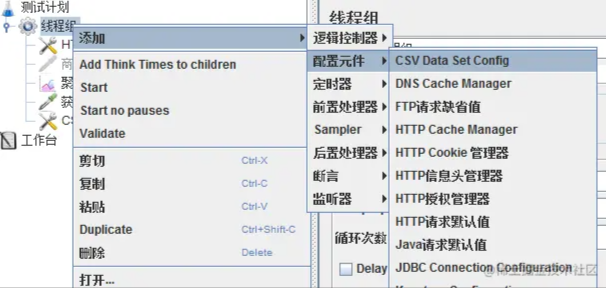
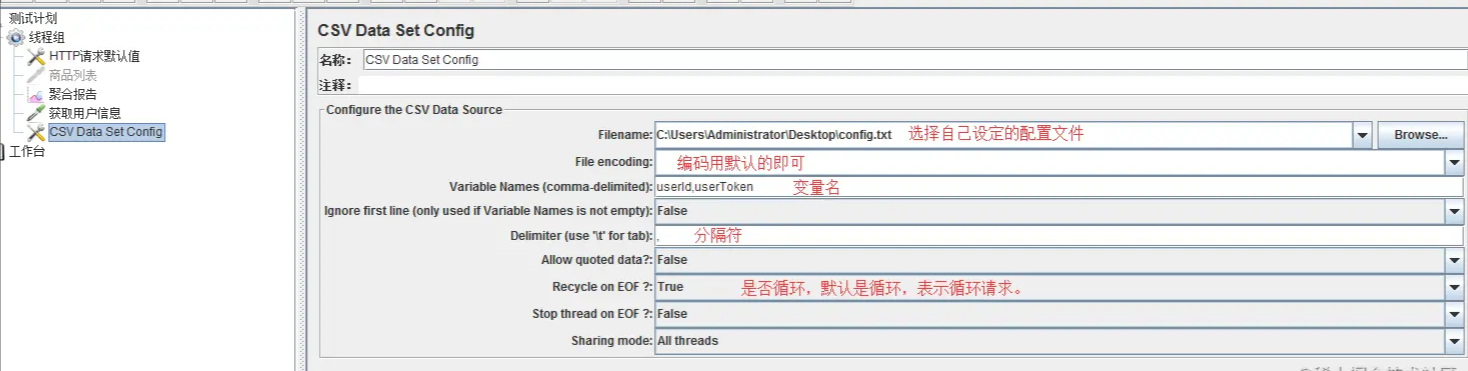
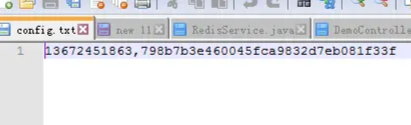
配置文件如下,自己设定一个id和token,在浏览器上F12查找一个拿来用。 或者使用程序生成几百几千个用户id,token,来模拟多用户访问。
5)、查看压测结果
执行压测后需要查看相关结果,线程组右键-添加-监听器-聚合报告,这里有很多包括表格、图表等等,一般就看聚合报告。
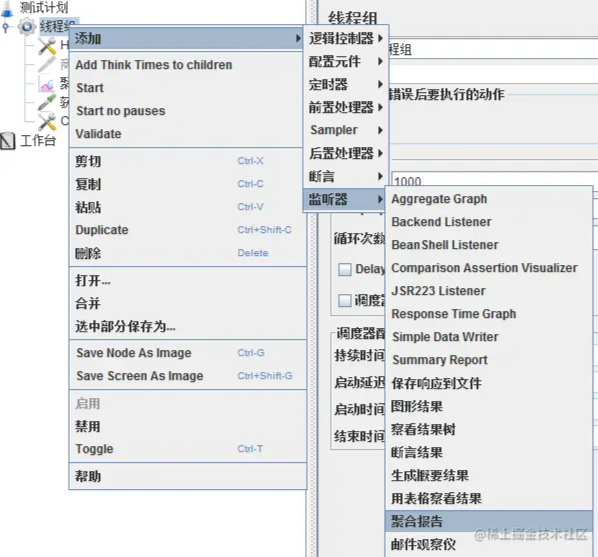
聚合报告如图所示,这里的Throughput属性就是指吞吐量,前面的Samples就是请求量。
含义:10000个请求的吞吐量是300-400之间,可以通俗理解为仅支持几百个并发(方便理解专业点一般不这么讲),很低,需要性能优化。

生产环境用法#
1、安装
1)、将apache-jmeter-3.3.zip上传到Linux服务器上;
2)、unzip xx.zip进行解压;
3)、如果报了找不到unzip命令,就执行yum install -y unzip zip安装上就可以了。
2、新建压测文件
1)、新建一个压测文件:如user_list.jmx,设定线程组中线程数为5000,循环次数为10,表示执行50000次;
2)、将这个文件上传到Linux服务器上;
3)、具体新建压测文件jmx的方法参照前面的讲解。
3、执行压测
1)、同级目录下,执行命令: ./apache-jmeter-3.3/bin/jmeter.sh -n -t user_list.jmx -l result.jtl
2)、启动jmeter进行压测,压测后的结果输出为result.jtl文件。
4、观测现象
在执行过程中,可以另开启一个窗口,执行top命令查看服务器承受的负载。(主要看红框这个,以及下面进程中的java相关的,会发现负载变得很大,CPU占用率也很高。)
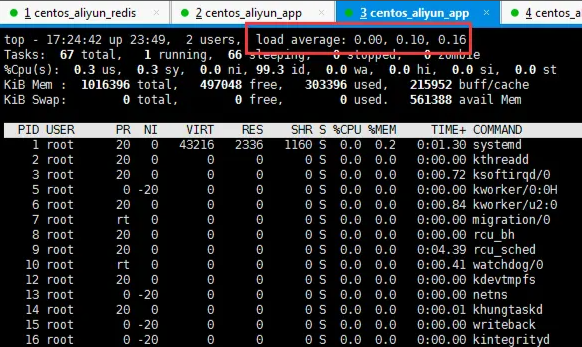
5、导出结果
1)、将result.jtl下载到本地环境,然后在jmeter中的聚合报告那里,浏览打开,看结果;
2)、可以发现吞吐量很不理想,Linux服务器配置较低时,error很高,说明应用程序难以承受直接挂掉了。

6、压测建议
1)、压测不能依靠一次评判,一般第一次只是热身,以第二次第三次压测为准;
2)、不要在工作时间或运行高峰期时间进行压测,这是很危险的行为,最佳时期一定是测试阶段,少部分特殊情况只能在生产环境压测也一定要选择安全时段如凌晨;
3)、根据压测结果,进行性能优化后,可以再次像上述一样进行压测,然后导出聚合报告进行对比,直到达到理想结果。
总结#
其实压测本身不难,压测的工具和方式也很多,比如redis有自己的压测工具redis-benchmark,还有Apache Benchmark简称ab,是Apache自带压测工具,这些用法都很简单。
压测是迈向高级工程师必会的技能之一,尤其是对核心业务接口的压测十分常用,正规的项目在测试阶段都需要压测。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)
2021-01-06 dcat-admin
2021-01-06 在Laravel外独立使用Eloquent