探索 PHP 如何生成全局唯一的 id
探索开始#
1.基于时间 + 随机码生成 id#
php 提供了一个生成唯一值生成函数 uniqid ($prefix,$more_entropy), 这是一个基于毫秒级时间生成 id 的函数,不带参数执行输出 13 位字符随机码,$prefix 返回随机码的前缀,$more_entropy 设为 true 时为加熵,返回字符会变为 23 位(不包括 $prefix)。编辑代码如下:
-
单进程版代码
$start_time = microtime(true); $container = []; $all_count = 1000000; //生成id总数量(一百万个) for ($i = 0; $i < $all_count; $i++) { //生成随机id $random = uniqid(); //长这样子:5e1401c70b7db $container[$random] = $i; //去掉重复id } $waste_time = bcsub(microtime(true), $start_time, 4);//计算时间 $conclusion = '耗时:' . $waste_time . 's,共生成id个数:' . $all_count . ',重复id个数:' . ($all_count - count($container)); dump($conclusion);
执行代码,返回

多次重复执行,发现重复 id 都是 0,耗时都在 60 秒以上,平均每秒可以生成一两万个 id,感觉 uniqid () 不加参数也不错嘛,但是这是幻觉而已,坏得很,经不起考验的。
- 多进程版代码
$start_time = microtime(true);
$process_count = 50; //进程数量
$all_count = 1000000; //生成id总数量(一百万个)
$per_process_count = floor($all_count / $process_count); //每个进程生成id总数量
for ($i = 0; $i < $process_count; $i++) {
//开多进程模拟真实场景
MultiProcessHelper::instance($process_count)->multiProcessTask(function () use ($per_process_count, $i) {
//生成随机id
$container = [];
for ($j = 0; $j < $per_process_count; $j++) {
$random = uniqid(); //长这样子:5e1401c70b7db
$container[] = $random;
}
//把生成的id放到缓存里面
Cache::set($i, $container);
});
}
MultiProcessHelper::recycleProcess();//回收子进程
//以下是整理多个并发进程生成id的重复情况
$container = [];
for ($i = 0; $i < $process_count; $i++) {
$res = Cache::get($i);
foreach ($res as $v) {
$container[$v] = 0; //去掉重复id
}
}
$waste_time = bcsub(microtime(true), $start_time, 4);//计算时间
$conclusion = '耗时:' . $waste_time . 's,共生成id个数:' . $all_count . ',重复id个数:' . ($all_count - count($container));
dump($conclusion);
执行代码,返回

结果发现时间变短了,平均每秒生成的 id 数量达到了 10 万个。但是别忘了,异步执行任务的进程是 50 个,榨干了 cpu 了。再看,重复个数不再为 0,而是有 10 万个之多,大概 1/10 都重复了,所以不加熵使用 uniqid 不能保证生成唯一 id。
如果设置 $prefix 为 mt_rand (),mt_rand () 会生成 0 到最大随机数数(21 亿左右)的随机整数,$more_entropy=true,那样将返回更加随机的 id,利用这一点设计随机码生成规则。编辑代码如下:
$random = uniqid(mt_rand(), true); //长这样子:21083019475e14021cdceb11.02999582
- 单进程版执行结果

这个超强了,每秒可以生成百万级别的 id(加熵之后,使用的算法不一样了,总之加熵时 uniqid 更快了),重复率为 0
- 多进程版执行结果

重复率为 0,可以断定一该方式生成唯一 id 可行,性能和重复概率表现很好,唯一不足就是 id 无序
2. 使用 session_create_id ()#
该函数是 php7.1 之后提供的,是 php 用来生成 session_id 使用的,php 使用它来生成每个请求会话,应该唯一是相当好的,不然呢!测试一波:
$random = session_create_id(); //长这样子:6khfg75a13khre330nqu1t84ab
-
单进程版执行结果

-
多进程版执行结果

由上可见,session_create_id 性能和重复率都表现不错,值得信赖
3. 使用 uuid#
uuid 已经形成的国际规范,目前出来的版本有四五个,最常用的是由时间戳 + 顺序号 + 机器标识 + 进程标识规则生成的 id,与此相关的 composer 包很多了,不造重车轮是最大的生产力,直接选用 https://packagist.org/packages/ramsey/uuid 包,测验一下:
$random = Uuid::uuid1()->toString(); //长这样子:480dac52-3102-11ea-89e3-525400cae48b
-
单进程版执行结果

-
多进程版执行结果

结果令人意外,uuid 生成速度还行,但是多进程异步生成时,并不能保证高标准的唯一性,出现了 8 个重复的,虽然很少,但是很意外,说好的全球唯一呢,有点虚,哈哈!总的来说还是不错的,重复率已经做到相当低了。
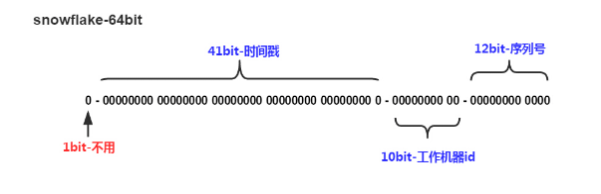
4. 使用雪花算法#
以上三种都是只会生成无序的随机字符,但是我们有些时候需要依靠唯一 id 对数据库进行排序的,比如我们要生成全库唯一 id 时,我们就需要 id 满足顺序性、整数类型(提高索引效率),而由雪花算法生成的 id 可以满足这一点(雪花 id 有时间顺序)。雪花算法原理图如下:
$snowflake=new Snowflake();
//可以添加机器码,可设置1024个,以增强随机性,但1024太小治标不治本,当集群进程数超于这个时,加上多机器时间戳的不靠谱了,还是会出现问题,这里只做简单使用
$random = $snowflake->id(); //长这样子:55141599398592512
-
单进程版执行结果

-
多进程版执行结果

分析结果,单进程使用雪花算法生成 id,可以保持十几万个每秒的生成速度,且重复率保持为 0,但是去到并发生成时,问题出现了,重复了很多,重复率 1/2,恐怖,可断,雪花算法如上面那样简单使用的话,是难以适合高并发场景的!
5.id 计算器生成 id#
id 计算器生成 id 就是的首要工作就是要设置一个公共变量,该变量增量为 1,每次进程从这里申请一次 id,id 的值都会加一,这样一直累加下去,就保证了全局唯一性,且都是整数。这方面,Redis 很能胜任,一是性能很好,二是跨机器,另外 Redis 提供的原子性函数 incr,简直天造地设了。来,操作一波:
$random = Cache::inc('id'); //长这样子:1,2,3,4,5,...
-
单进程版执行结果

-
多进程版执行结果

这种方式生成的 id, 能够保持很好的 id 递增性,即保证的顺序性,由于 incr 是原子操作,重复率几乎为 0,产生速率,有赖于 Redis 的软件性能、网络等等因素,也算是了比较好方案了。
总结#
以上各种id生成方式,各有各的优缺点,不能一概而论。要哪一种更好,还是要看具体需求,适合就是最好的。但总的来说,唯一性、性能是绝对高尚的。
除了上述几种方式之外,还有很多生成唯一id的方案,也可以奇技淫巧一下(猥琐发育),在上面几种方式为基础打造新的更加高效和可靠的生成方式
上面提到的雪花算法生成唯一 ID 的 Package,已内置了 Redis 的支持,即使在多线程环境下,也不会生成重复的 ID:
// 在 Laravel 中,你可以这样使用
$snowflake = (new Snowflake())->setSequenceResolver(
new LaravelSequenceResolver($this->app->get('cache')->store())
);
$snowflake->id();
底层是基于 redis psetex 实现的并发锁,保证同一时间、同一机器中心 ID、同一 workID 下生成的 ID 不重复。
$lua = "return redis.call('exists',KEYS[1])<1 and redis.call('psetex',KEYS[1],ARGV[2],ARGV[1])";
if ($store->connection()->eval($lua, 1, $key = $currentTime, 1, 1000)) {
return 0;
}
return $store->connection()->incrby($key, 1);




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?