八、python开发之字符集
一、字符集的历史:
1、ASCII码,占据一字节,主要显示英文,0~256种编码格式英文占据了0~127种
2、GB2312,由于计算机传入到中国,发现中文的种类太多,剩下的128字节并不能将所有的中文编码显示,所以衍生出GB2312,其中包含了7000多个汉字
3、GBK,由于后来发现更多的汉字,所以将GB2312扩展成GBK,新增加了20000多的汉字
4、GB18030,由于后来少数民族也用上了电脑,所以继续扩展GBK的内容,又加了几千个少数民族的文字
5、UNICODE,由于各个国家都有一套自己的编码格式,所以各个国家的系统都不兼容别国的系统,此时一个叫ISO(国际标准化组织)解决了这个问题,生成了一个“UNICODE”编码,简称万国码,由两个字节表示一个字符,可收录65535中字符
6、UTF-8,由于UNICODE中英文和中文都占据两个字节,ASCII表示使用UNICODE并不高效,所以在此基础上衍生出了UTF-8,在UTF-8 中英文字符占据一个字节,而中文字符占据三个字节。
二、python中字符集的转换:
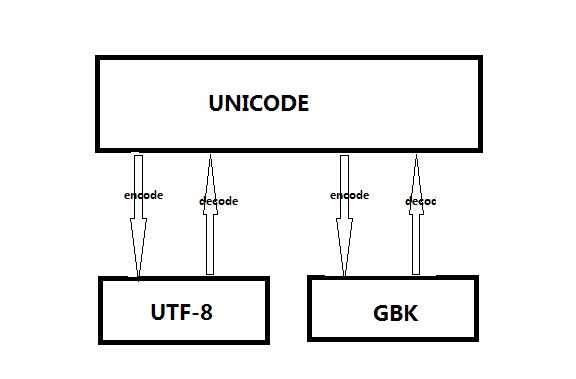
三、python中字符编码之间的转换:
1、定义一个变量(在python2.x中字符集默认为ascii,python3.x中默认为unicode)
Char = "my name is 蔡"
print(Char)
2、将unicode编码格式为utf-8(encode需要指定unicode转换成什么字符集)
Char1 =(Char.encode('utf-8'))
print(Char1)
3、 将utf-8格式转换成unicode(decode需要指定什么字符集转换成unicode)
Char2 =(Char1.decode('utf-8'))
print(Char2)
4、将unicode转换成gbk
Char3 =(Char2.encode('gbk')
print(Char3)
5、将utf-8转换成gbk
Char4 =(Char1.decode('utf-8').encode('gbk'))
print(Char4)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号