

基于 opencv 的图像处理入门教程
前言
虽然计算机视觉领域目前基本是以深度学习算法为主,但实际上很多时候对图片的很多处理方法,并不需要采用深度学习的网络模型,采用目前成熟的图像处理库即可实现,比如 OpenCV 和 PIL ,对图片进行简单的调整大小、裁剪、旋转,或者是对图片的模糊操作。
所以本文主要是介绍用 OpenCV 实现一些基本的图像处理操作,本文的目录如下所示:
- 安装
- 旋转图片
- 裁剪图片
- 调整图片大小
- 调整图片对比度
- 模糊图片
- 高斯模糊
- 中值模糊
- 边缘检测
- 转为灰度图
- 形心检测
- 对彩色图片采用蒙版(mask)
- 提取图片的文字(OCR)
- 检测和修正歪曲的文字
- 颜色检测
- 去噪
- 检测图片的轮廓
- 移除图片的背景
原文地址:
https://likegeeks.com/python-image-processing/
代码和样例图片的地址:
https://github.com/ccc013/CodesNotes/tree/master/opencv_notes
https://github.com/ccc013/CodesNotes/blob/master/opencv_notes/opencv_image_process_tutorial.ipynb
1. 安装
OpenCV 的安装还是比较简单的,直接用 pip 命令在命令行安装即可,输入以下命令:
pip install opencv-python
验证是否安装成功,可以运行 python 命令,然后分别输入以下命令:
import cv2
运行成功,没有报错,即安装成功。
2. 旋转图片
首先,还是需要导入 cv2 模块:
import cv2
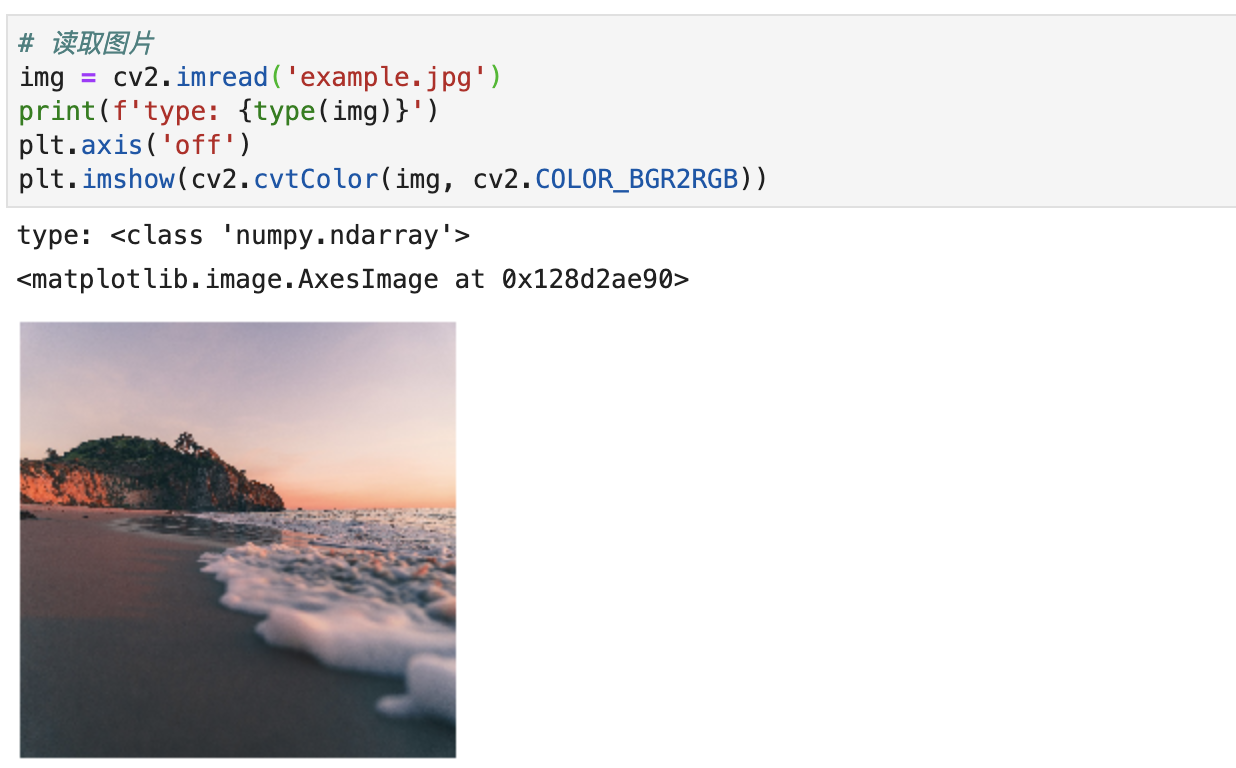
然后第一件事情就是读取图片,调用imread 函数即可,输入参数是图片的路径,如下代码所示:
# 读取图片
img = cv2.imread('example.jpg')
print(f'type: {type(img)}')
plt.axis('off')
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
然后打印读取的图片类型,可以知道是一个numpy 的多维数组,即矩阵的形式。
上述代码运行结果如下:
下面的所有功能实现,我都是在 jupyter notebook 上实现的,所以展示图片部分和原文有所不同,原文展示图片代码是采用:
cv2.imshow('original image', img)
cv2.waitKey(0)
而在 jupyter 中,需要先导入下面的库:
import matplotlib.pyplot as plt
%matplotlib inline
然后直接调用 plt.imshow() 函数,不过 opencv 都需要做一个转换过程,即:
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
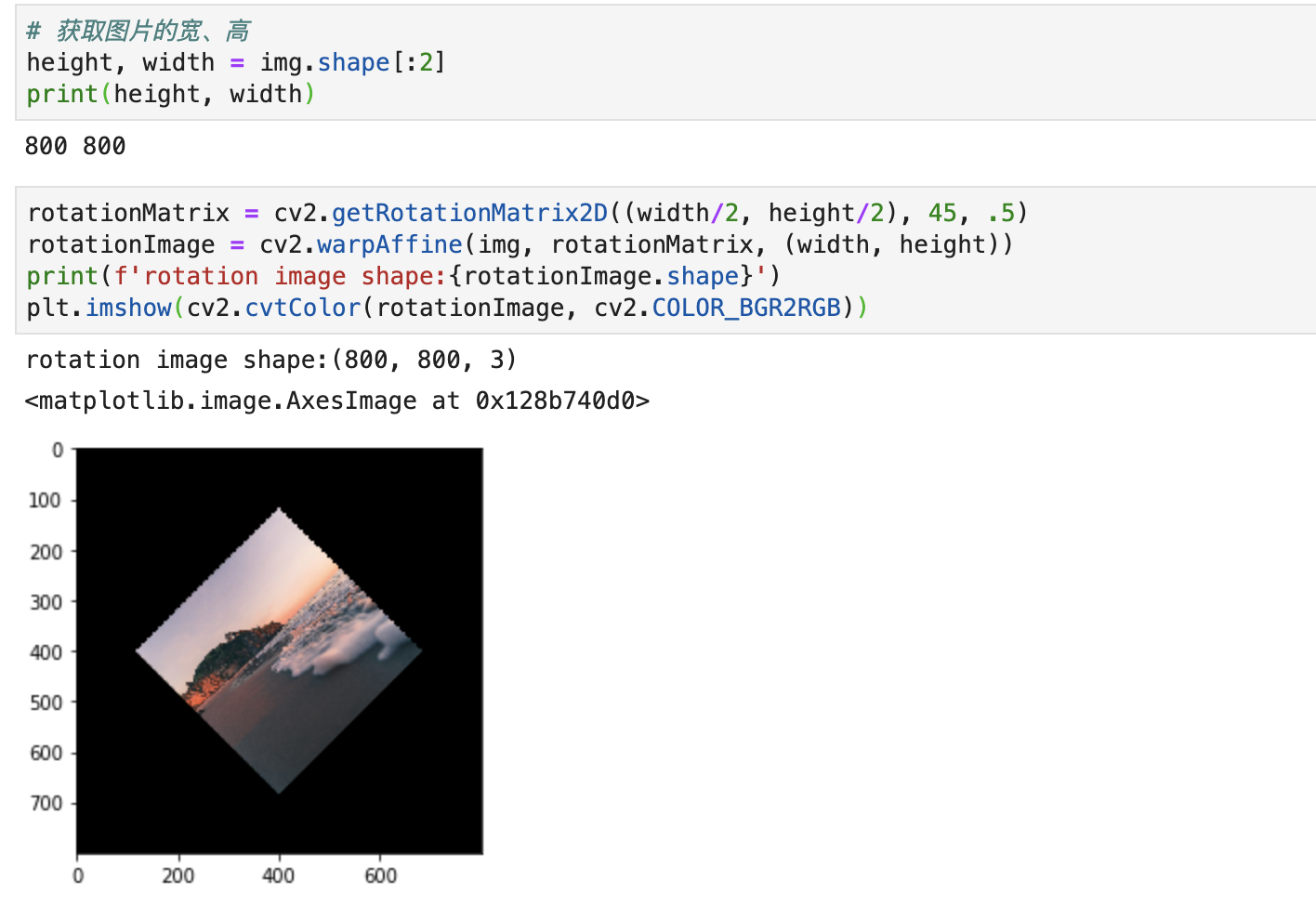
读取好图片后,接下来就是实现旋转图片,这里分为以下三个步骤:
- 获取图片的宽和高
- 调用函数
cv2.getRotationMatrix2D()得到旋转矩阵 - 通过
wrapAffine实现旋转
实现的代码如下所示:
# 获取图片的宽、高
height, width = img.shape[:2]
print(height, width)
rotationMatrix = cv2.getRotationMatrix2D((width/2, height/2), 45, .5)
rotationImage = cv2.warpAffine(img, rotationMatrix, (width, height))
print(f'rotation image shape:{rotationImage.shape}')
plt.imshow(cv2.cvtColor(rotationImage, cv2.COLOR_BGR2RGB))
结果如下所示:
3. 裁剪图片
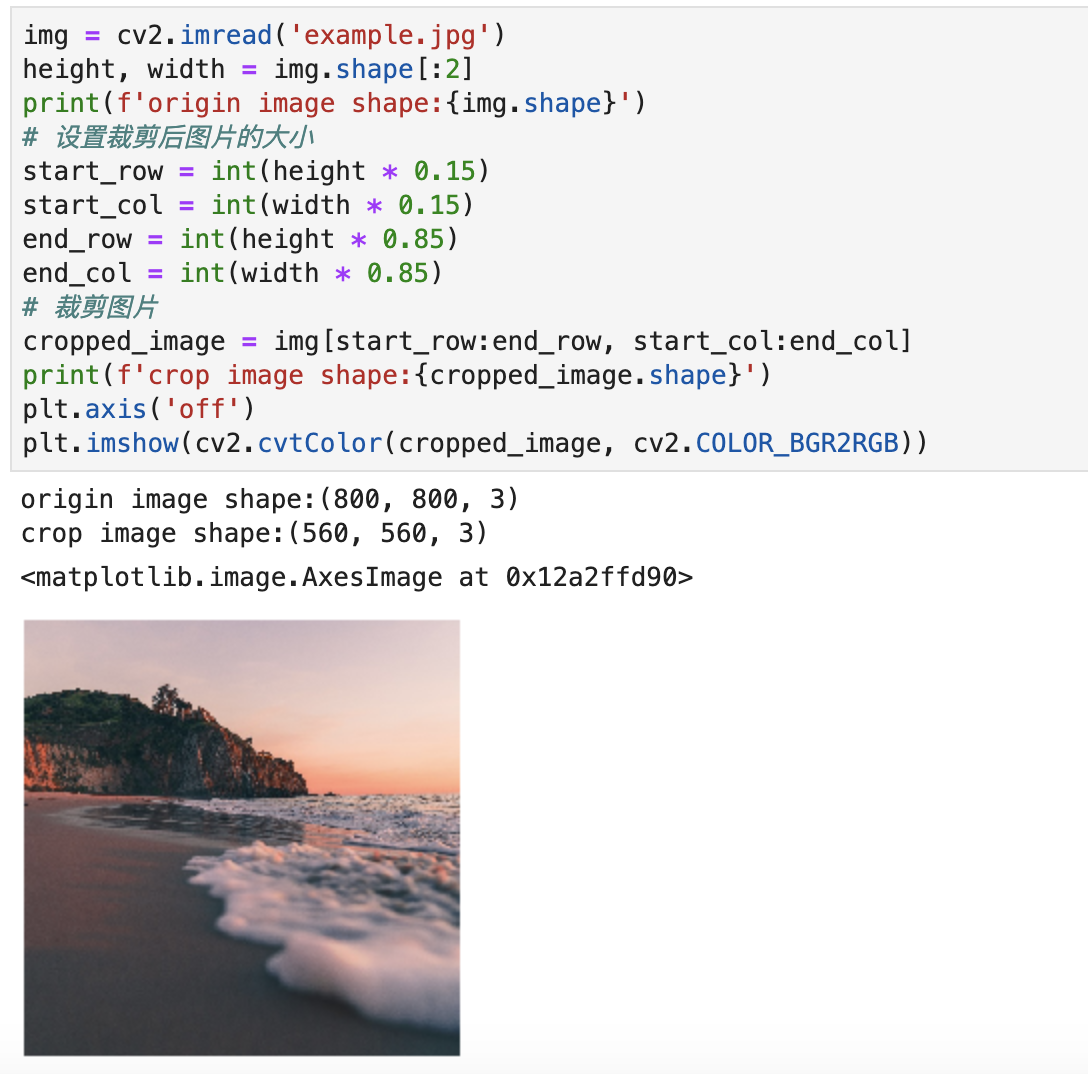
裁剪图片的步骤如下:
- 读取图片,并获取图片的宽和高;
- 确定裁剪后图片的宽和高;
- 开始裁剪操作
实现代码如下所示:
img = cv2.imread('example.jpg')
height, width = img.shape[:2]
print(f'origin image shape:{img.shape}')
# 设置裁剪后图片的大小
start_row = int(height * 0.15)
start_col = int(width * 0.15)
end_row = int(height * 0.85)
end_col = int(width * 0.85)
# 裁剪图片
cropped_image = img[start_row:end_row, start_col:end_col]
print(f'crop image shape:{cropped_image.shape}')
plt.axis('off')
plt.imshow(cv2.cvtColor(cropped_image, cv2.COLOR_BGR2RGB))
效果如下图所示:
4. 调整图片大小
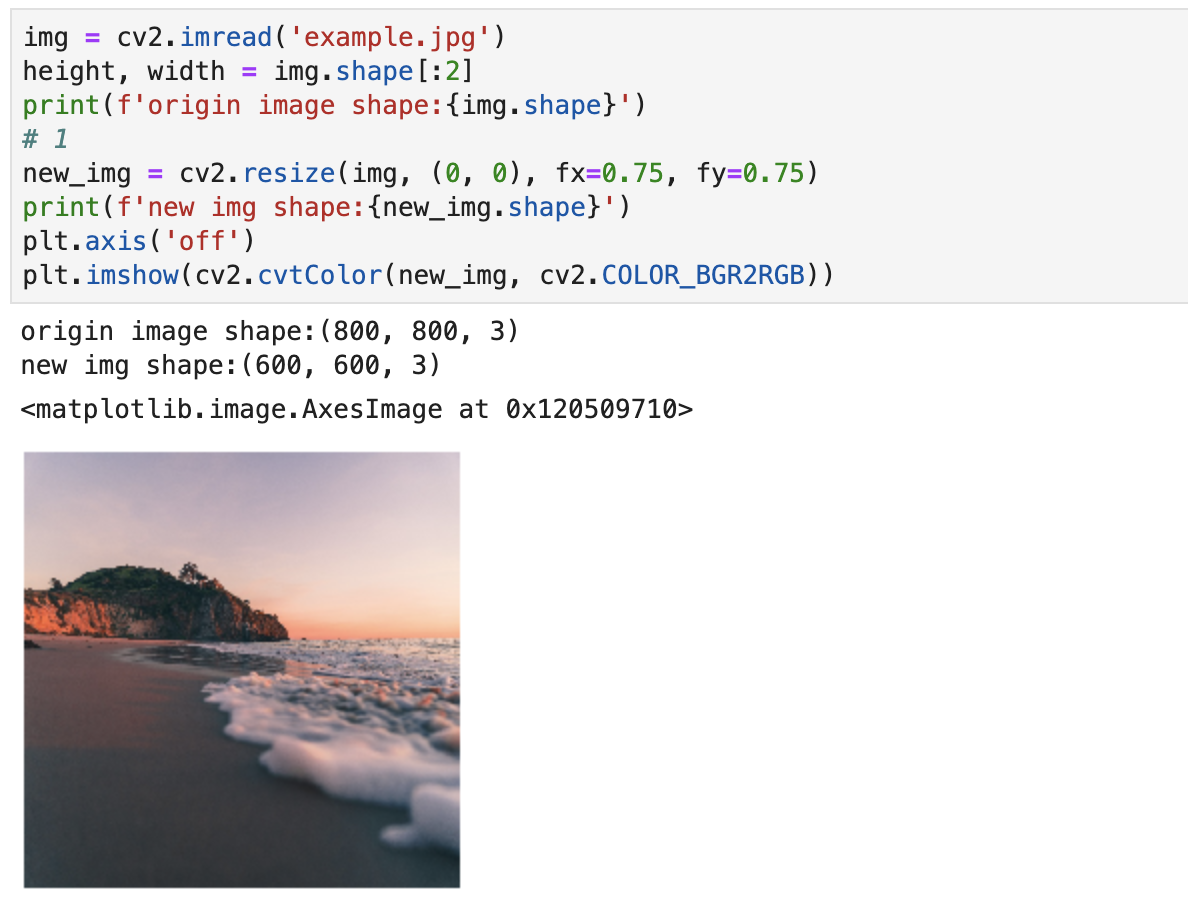
对图片进行调整大小的操作,采用的是resize() 函数,这里有两种方式进行调整大小:
- 坐标轴方式来指定缩放比例,即
fx, fy参数; - 直接给出调整后图片的大小。
第一种方式的实现代码:
img = cv2.imread('example.jpg')
height, width = img.shape[:2]
print(f'origin image shape:{img.shape}')
# 1
new_img = cv2.resize(img, (0, 0), fx=0.75, fy=0.75)
print(f'new img shape:{new_img.shape}')
plt.axis('off')
plt.imshow(cv2.cvtColor(new_img, cv2.COLOR_BGR2RGB))
实现效果:
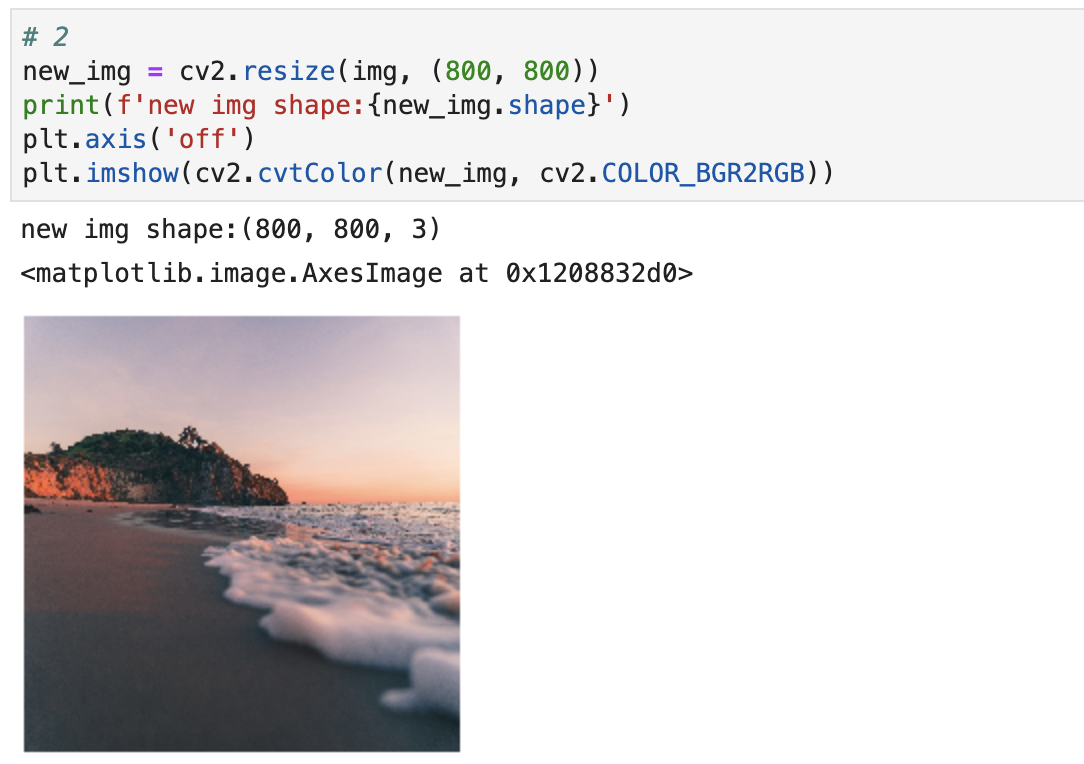
第二种方法的实现代码:
# 2
new_img = cv2.resize(img, (800, 800))
print(f'new img shape:{new_img.shape}')
plt.axis('off')
plt.imshow(cv2.cvtColor(new_img, cv2.COLOR_BGR2RGB))
实现结果如下所示:
5. 调整图片对比度
在 Python 的 OpenCV 模块中并没有特定的实现调整图片对比度的函数,但官方文档给出实现调整图片亮度和对比度的公式,如下所示:
new_img = a*original_img + b
官方文档地址:
https://docs.opencv.org/master/d3/dc1/tutorial_basic_linear_transform.html
这里公式中的 a 就是 $\alpha$, 表示图片的对比度,
- 如果它大于 1,就是高对比度;
- 如果在 0-1 之间,那就是低对比度;
- 等于 1,表示没有任何变化
b 是 $\beta$ ,数值范围是 -127 到 127;
要实现上述公式,可以采用 addWeighted() 方法,它输出的图片是一个 24 位的 0-255 范围的彩色图片。
其语法如下所示:
cv2.addWeighted(source_img1, alpha1, source_img2, alpha2, beta)
这个方法是接收两张输入的图片,然后根据 alpha1 和 alpha2 来将两种图片进行融合。
如果只是想调整图片的对比度,那么可以将第二个图片通过 Numpy 设置为 0。
所以,实现的代码如下所示:
import numpy as np
img = cv2.imread('example.jpg')
# 高对比度
hight_contrast_img = cv2.addWeighted(img, 2.5, np.zeros(img.shape, img.dtype), 0, 0)
# 低对比度
low_contrast_img = cv2.addWeighted(img, 0.5, np.zeros(img.shape, img.dtype), 0, 0)
plt.figure(figsize=(32, 16))
plt.subplot(3, 1, 1)
plt.title('origin image')
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.subplot(3, 1, 2)
plt.title('hight contrast image')
plt.imshow(cv2.cvtColor(hight_contrast_img, cv2.COLOR_BGR2RGB))
plt.subplot(3, 1, 3)
plt.title('low contrast image')
plt.imshow(cv2.cvtColor(low_contrast_img, cv2.COLOR_BGR2RGB))
实现效果如下所示:


6. 模糊图片
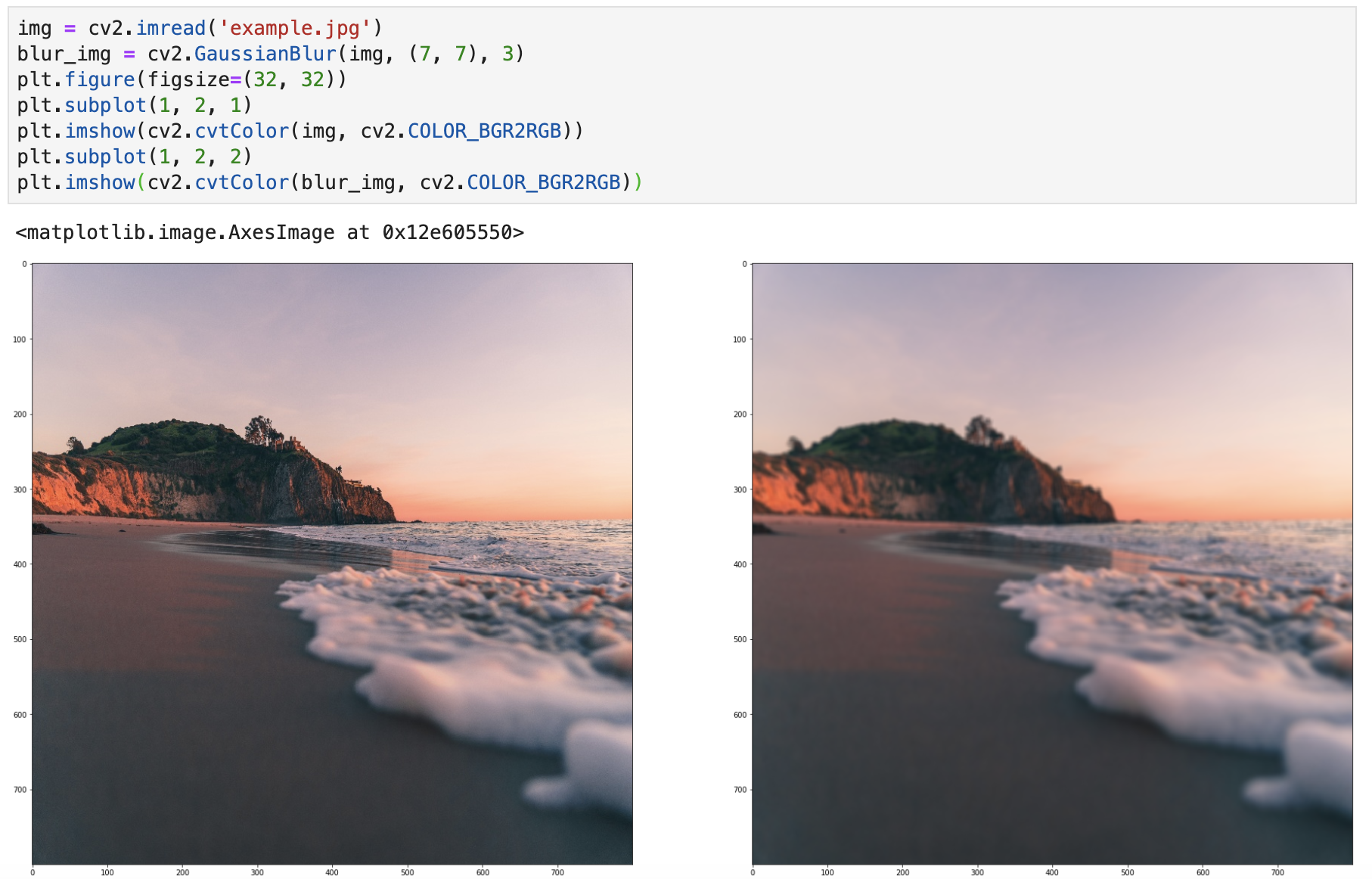
高斯模糊
高斯模糊采用的是 GaussianBlur() 方法,采用高斯核,并且核的宽和高必须是正数,且是奇数。
高斯滤波主要用于消除高斯噪声,可以保留更多的图像细节,经常被称为最有用的滤波器。
实现的代码如下所示:
img = cv2.imread('example.jpg')
blur_img = cv2.GaussianBlur(img, (7, 7), 3)
plt.figure(figsize=(32, 32))
plt.subplot(1, 2, 1)
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.subplot(1, 2, 2)
plt.imshow(cv2.cvtColor(blur_img, cv2.COLOR_BGR2RGB))
实现效果:
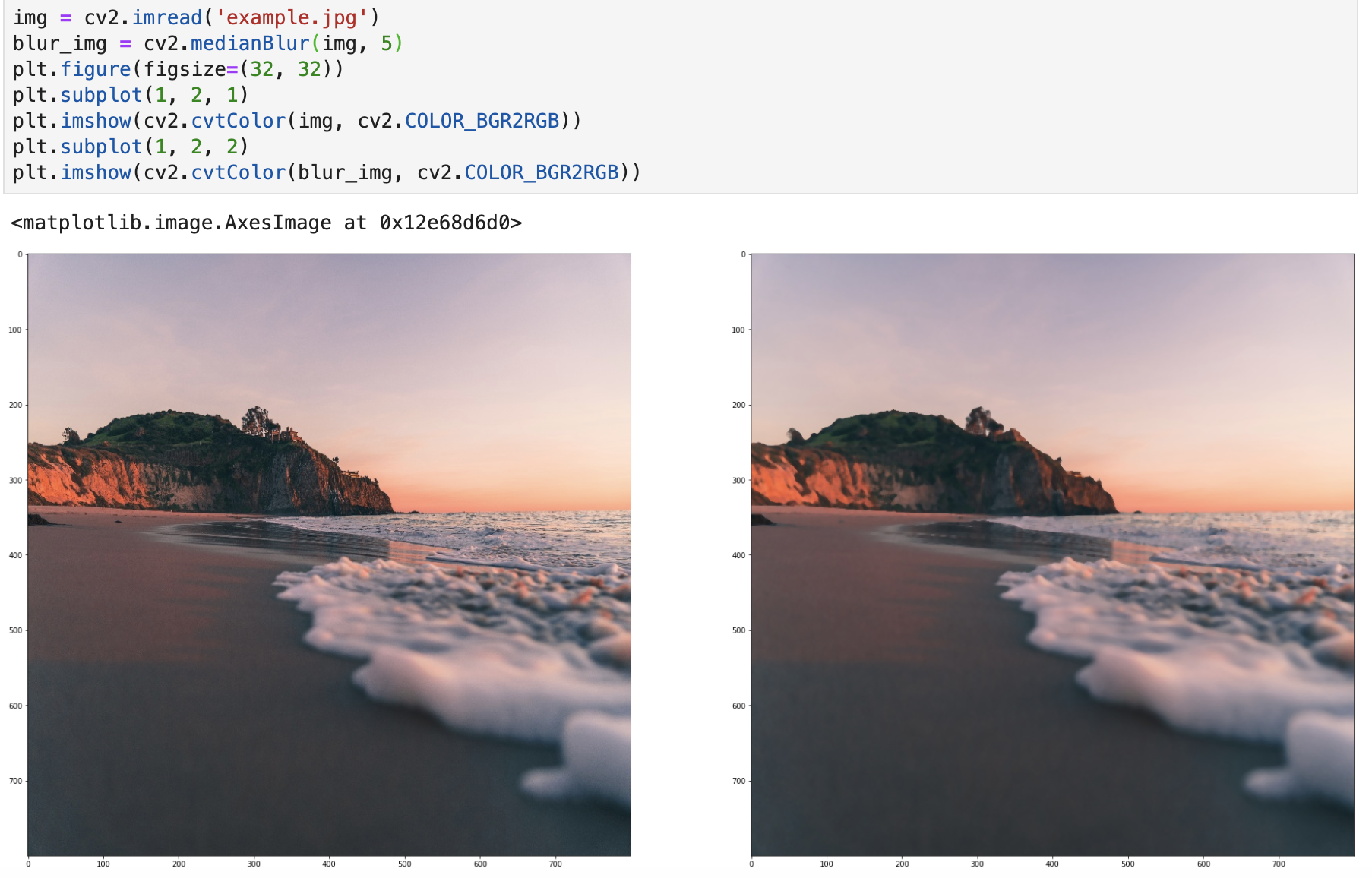
中值模糊
对于中值模糊,就是用区域内的中值来代替本像素值,因此孤立的斑点,比如 0 或者 255 的数值很容易消除掉。
所以中值模糊主要用于消除椒盐噪声和斑点噪声。
实现代码:
img = cv2.imread('example.jpg')
blur_img = cv2.medianBlur(img, 5)
plt.figure(figsize=(32, 32))
plt.subplot(1, 2, 1)
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.subplot(1, 2, 2)
plt.imshow(cv2.cvtColor(blur_img, cv2.COLOR_BGR2RGB))
实现效果如下所示:
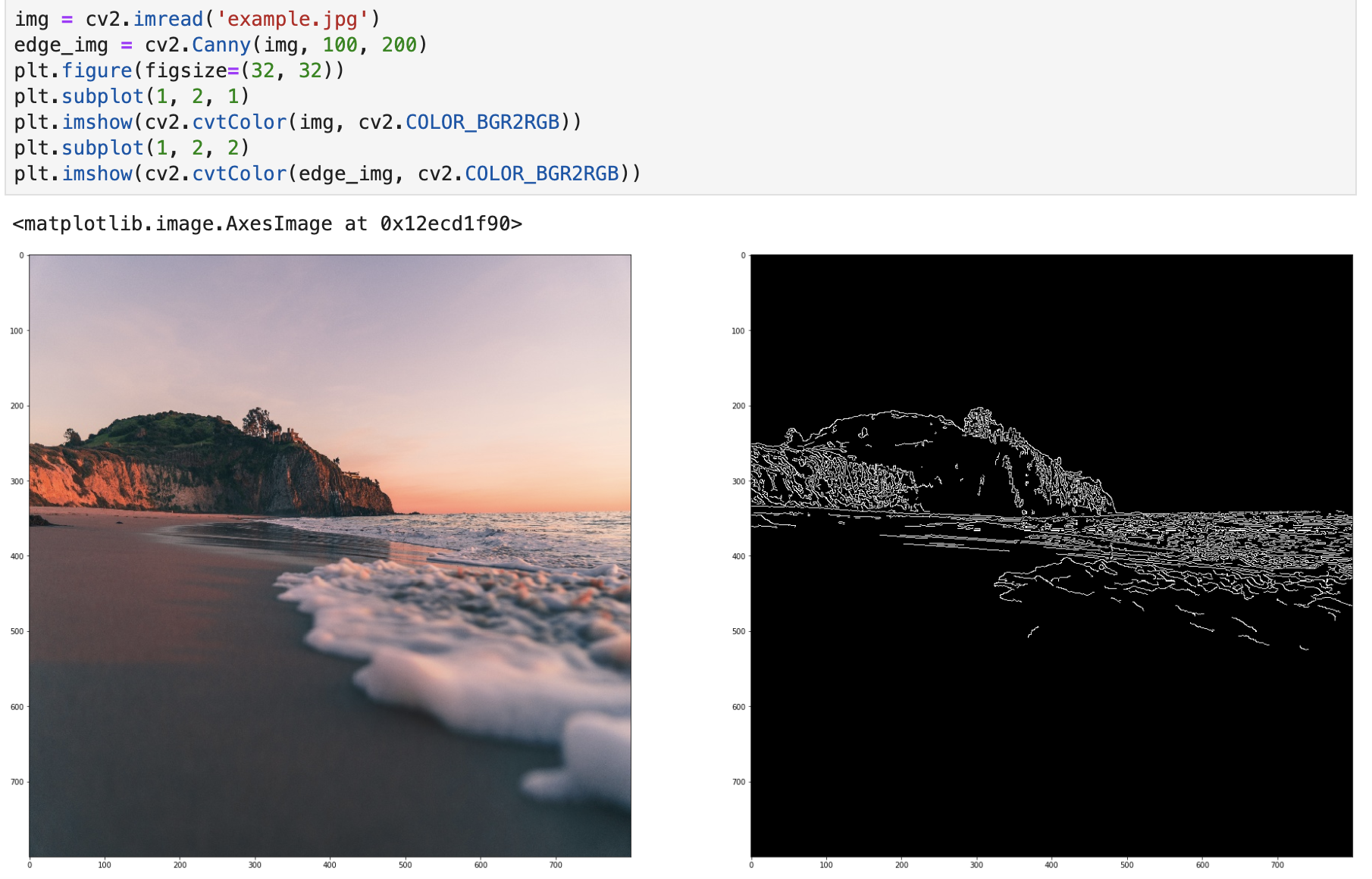
7. 边缘检测
边缘检测主要是通过Canny() 方法,它实现了 Canny 边缘检测器,这也是目前最优的边缘检测器。
Canny() 方法的语法如下:
cv2.Canny(image, minVal, maxVal)
其中 minVal 和 maxVal 分别表示梯度强度值的最小值和最大值。
实现代码如下:
img = cv2.imread('example.jpg')
edge_img = cv2.Canny(img, 100, 200)
plt.figure(figsize=(32, 32))
plt.subplot(1, 2, 1)
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.subplot(1, 2, 2)
plt.imshow(cv2.cvtColor(edge_img, cv2.COLOR_BGR2RGB))
实现结果:
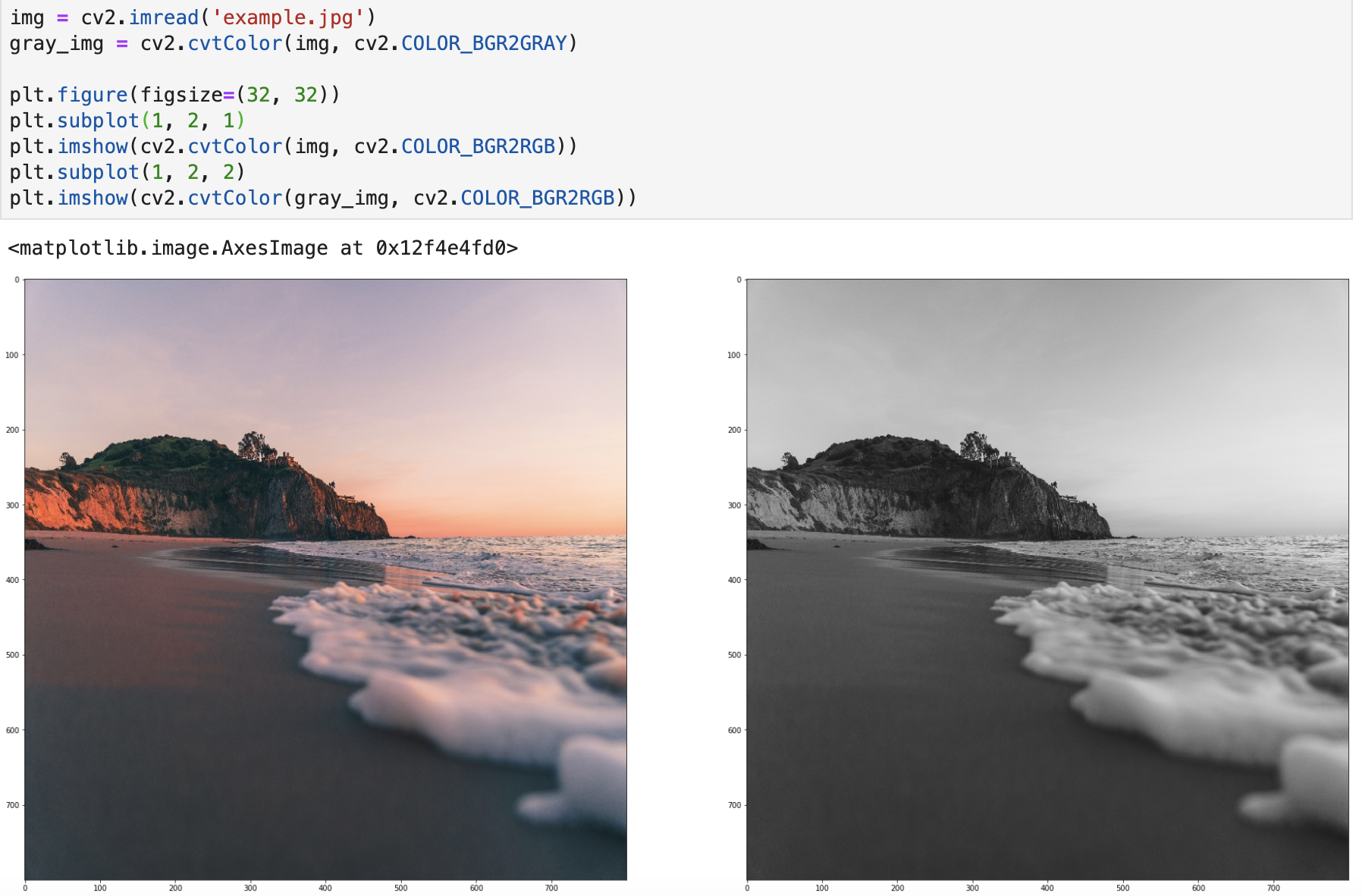
8. 转为灰度图
最简单的将图片转为灰度图的方法,就是读取的时候,代码如下所示:
img = cv2.imread("example.jpg", 0)
而另一种方法就是用 BGR2GRAY ,实现代码:
img = cv2.imread('example.jpg')
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
plt.figure(figsize=(32, 32))
plt.subplot(1, 2, 1)
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.subplot(1, 2, 2)
plt.imshow(cv2.cvtColor(gray_img, cv2.COLOR_BGR2RGB))
实现效果:
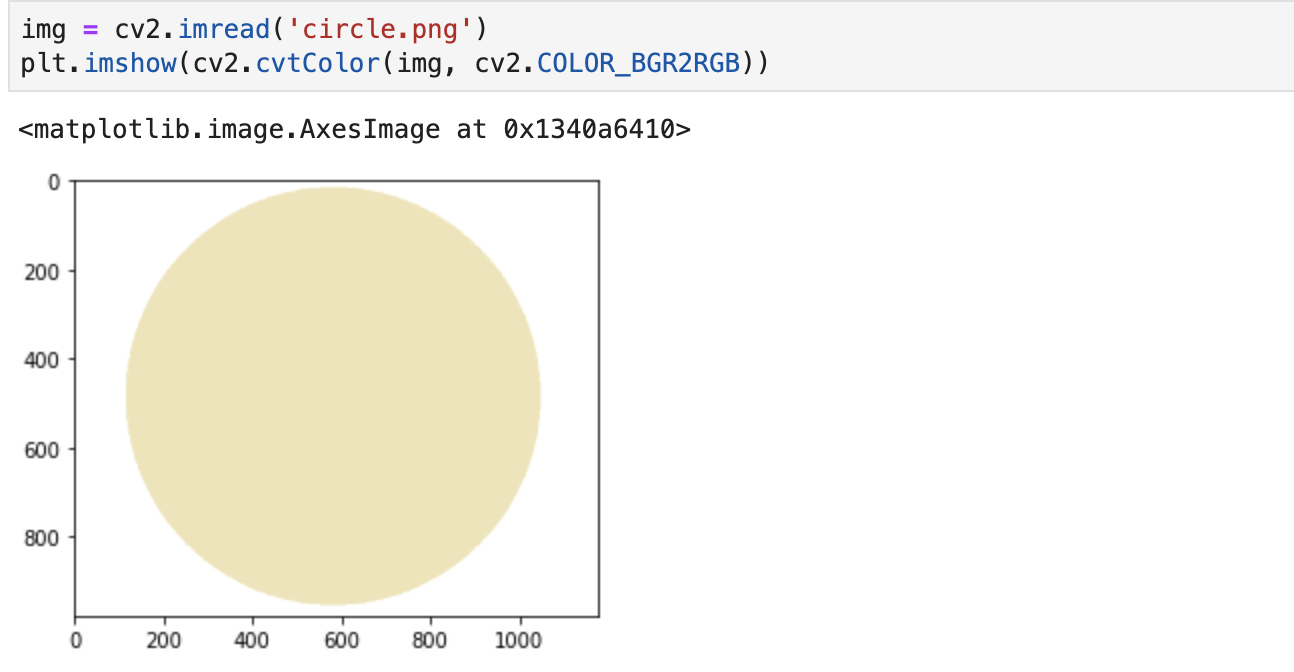
9. 形心检测
检测一张图片的形心位置,实现步骤如下所示:
- 读取图片,并转为灰度图;
- 通过
moments()方法计算图片的moments; - 接着利用第二步的结果来计算形心的 x,y 坐标
- 最后可以绘图展示检测的结果。
本例使用的图片如下:
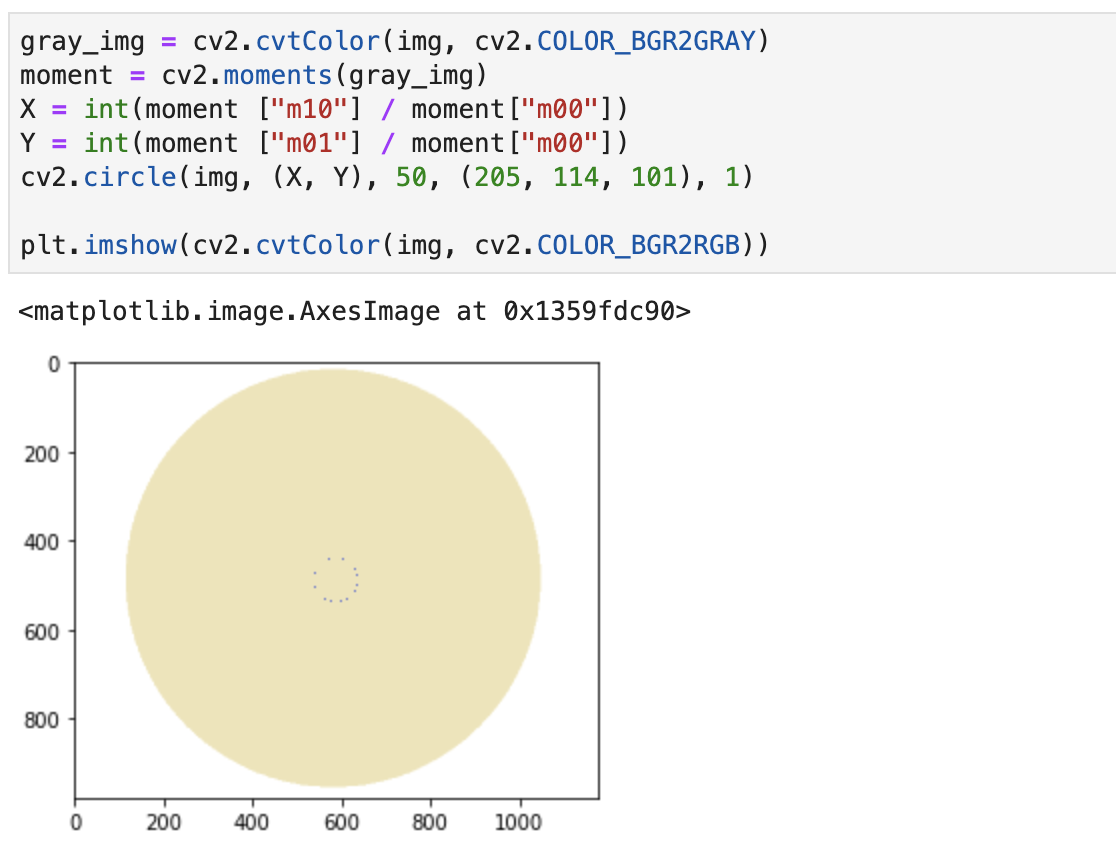
实现代码:
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
moment = cv2.moments(gray_img)
X = int(moment ["m10"] / moment["m00"])
Y = int(moment ["m01"] / moment["m00"])
cv2.circle(img, (X, Y), 50, (205, 114, 101), 1)
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
实现的效果:
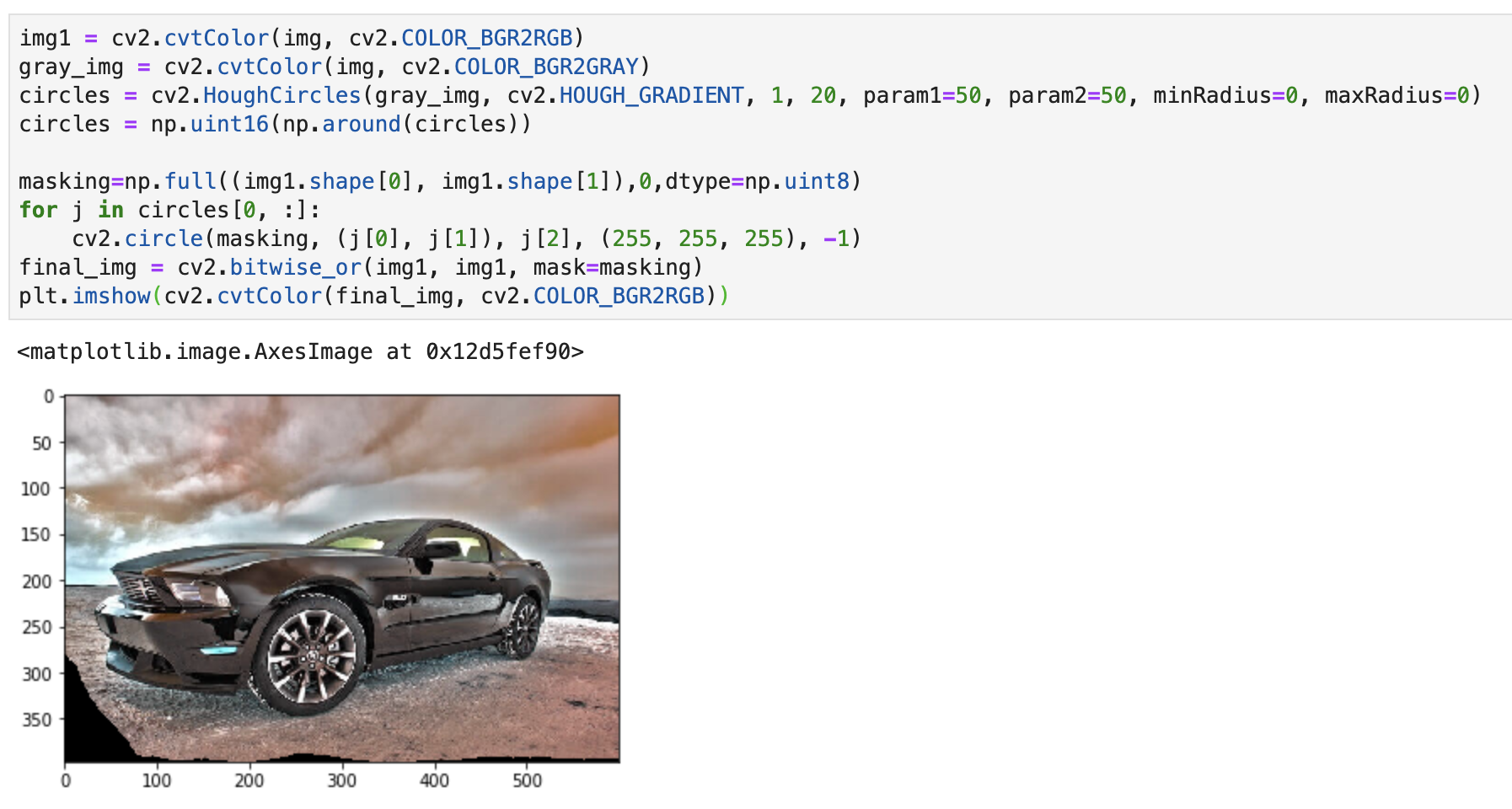
10.对彩色图片采用蒙版(mask)
图像蒙版就是将一张图片作为另一张图片的蒙版,或者是修改图片中的像素值。
本例中将采用HoughCircles() 方法来应用蒙版,这个方法可以检测图片中的圆,然后对这些圆应用蒙版。
本例采用的图片为:

实现代码:
img1 = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
circles = cv2.HoughCircles(gray_img, cv2.HOUGH_GRADIENT, 1, 20, param1=50, param2=50, minRadius=0, maxRadius=0)
circles = np.uint16(np.around(circles))
masking=np.full((img1.shape[0], img1.shape[1]),0,dtype=np.uint8)
for j in circles[0, :]:
cv2.circle(masking, (j[0], j[1]), j[2], (255, 255, 255), -1)
final_img = cv2.bitwise_or(img1, img1, mask=masking)
plt.imshow(cv2.cvtColor(final_img, cv2.COLOR_BGR2RGB))
实现效果:
11.提取图片的文字(OCR)
实现提取图片的文字是通过安装使用谷歌的 Tesseract-OCR,首先需要从下面这个网址中下载:
https://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-3.05.02-20180621.exe
接着再进行安装:
pip install pytesseract
如果是 mac,安装步骤可以是这样的:
brew install tesseract
pip install pytesseract
本例使用的图片:

实现代码如下所示:
import pytesseract
pytesseract.pytesseract.tesseract_cmd = '/usr/local/bin/tesseract'
img = cv2.imread('pytext.png')
pytesseract.image_to_string(img)
实现结果:
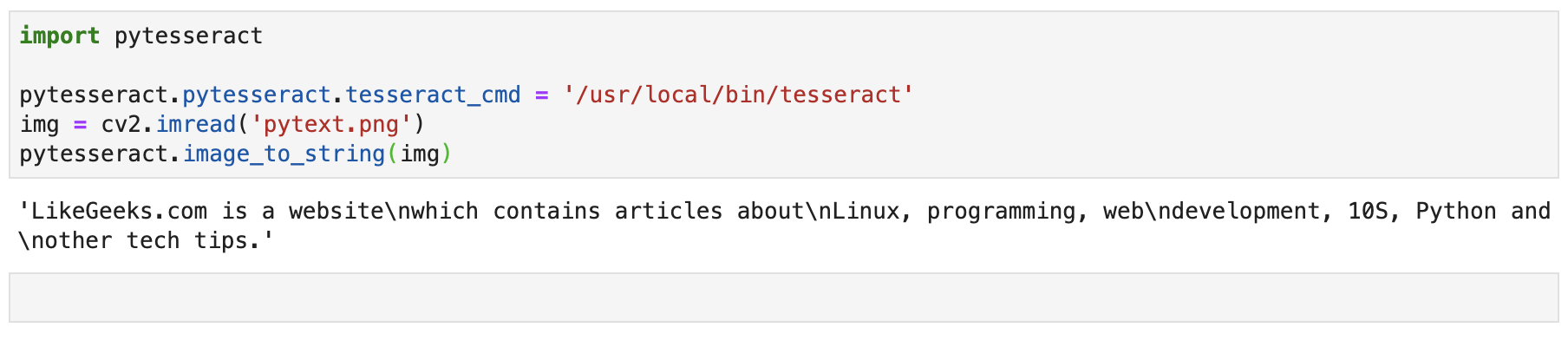
注意这里需要设置 tesseract 的执行路径,两种方法,第一种是设置环境变量:
windows 版:https://blog.csdn.net/luanyongli/article/details/81385284
第二种是在代码中进行指定,即代码中pytesseract.pytesseract.tesseract_cmd = '/usr/local/bin/tesseract',
这里我用的是 Mac,所以这个路径可以在命令行中输入which tesseract 来找到。
12. 检测和修正歪曲的文字
在本例中,使用的图片如下:

首先还是先读取图片,并转换为灰度图:
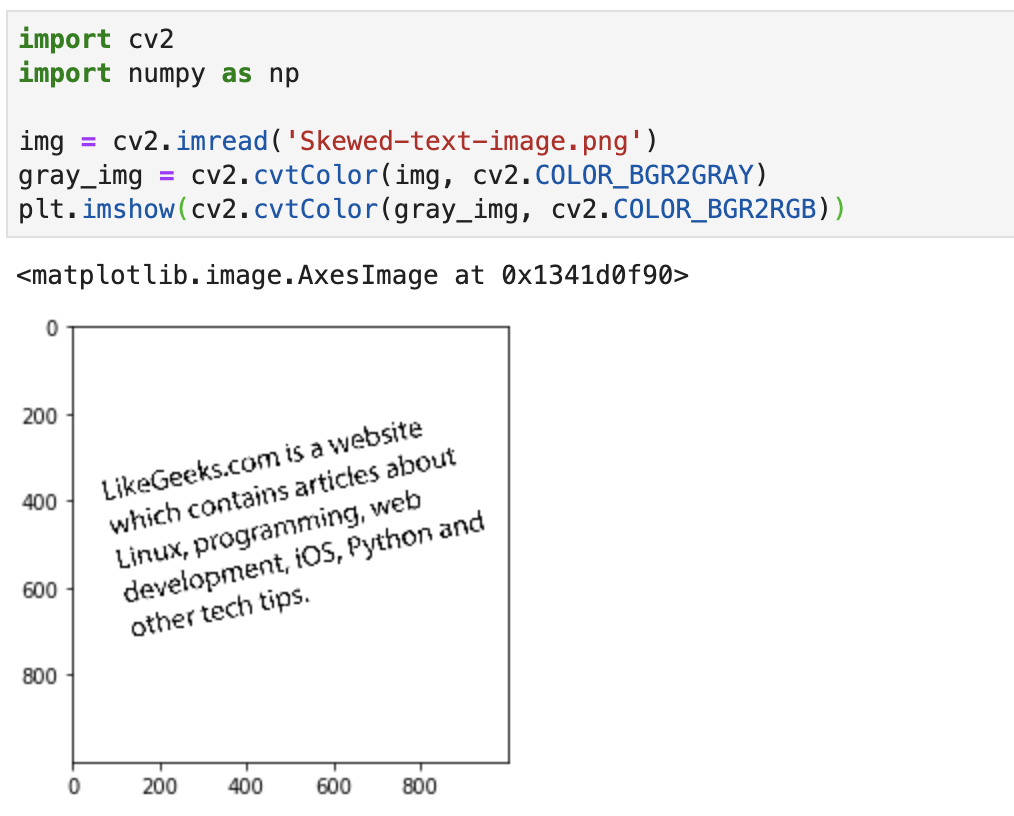
接着采用 bitwise_not 方法将背景和文字颜色进行交换,变成白字黑底:
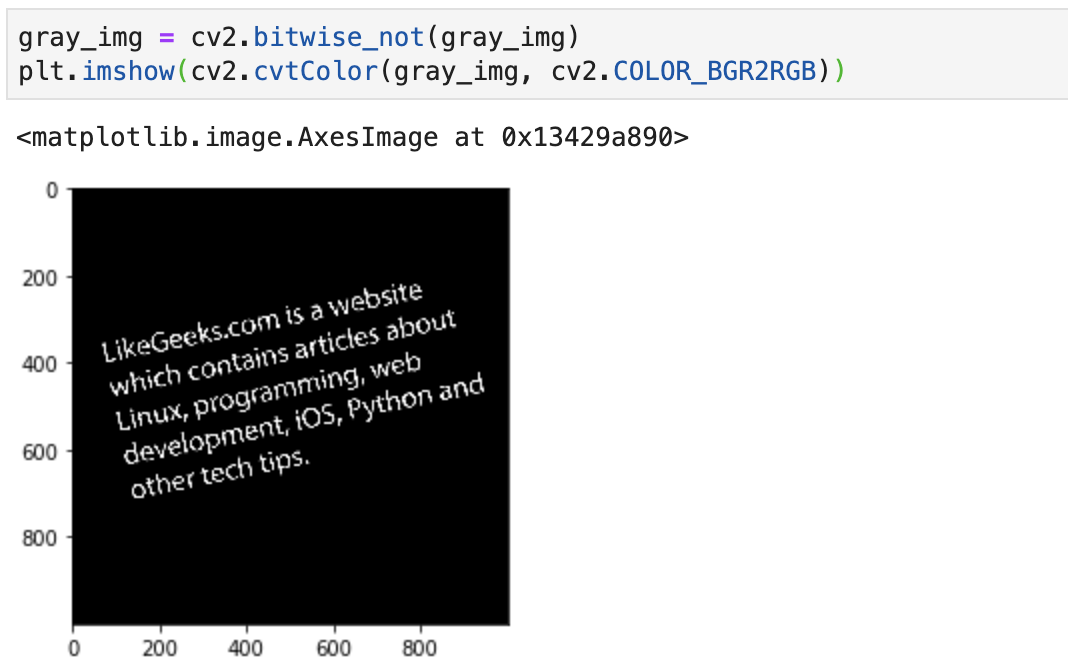
接着分别找到 x,y 坐标中大于 0 值的像素值,并通过minAreaRect() 计算得到歪曲的角度,接着就是计算要修正的角度,然后再通过之前旋转图片的方法来修正,实现代码和结果如下:
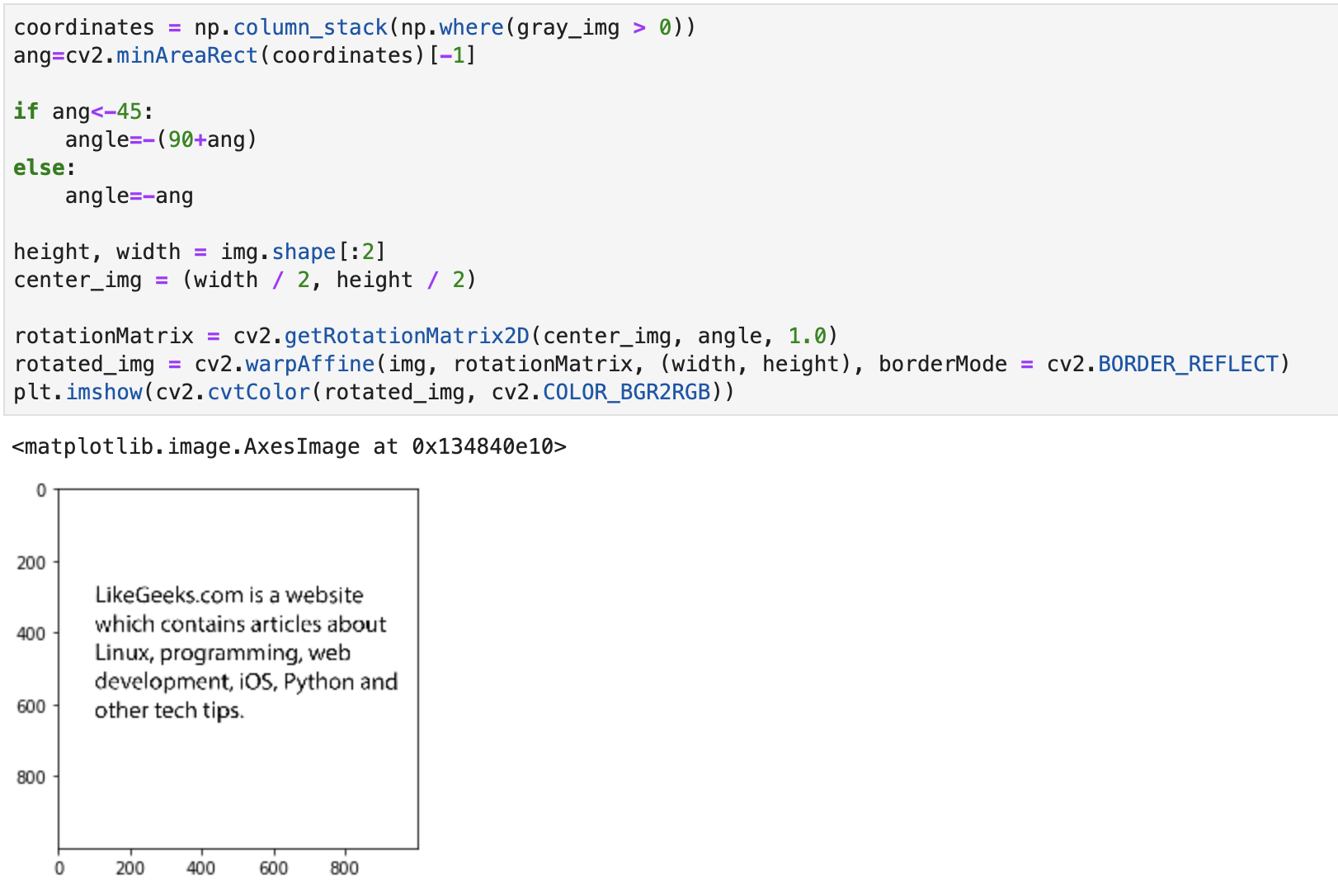
完整的实现代码:
import cv2
import numpy as np
img = cv2.imread('Skewed-text-image.png')
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gray_img = cv2.bitwise_not(gray_img)
coordinates = np.column_stack(np.where(gray_img > 0))
ang=cv2.minAreaRect(coordinates)[-1]
if ang<-45:
angle=-(90+ang)
else:
angle=-ang
height, width = img.shape[:2]
center_img = (width / 2, height / 2)
rotationMatrix = cv2.getRotationMatrix2D(center_img, angle, 1.0)
rotated_img = cv2.warpAffine(img, rotationMatrix, (width, height), borderMode = cv2.BORDER_REFLECT)
plt.imshow(cv2.cvtColor(rotated_img, cv2.COLOR_BGR2RGB))
13. 颜色检测
在本次例子中实现检测图片中的绿色区域,使用的图片:

首先是读取图片后,转换到 HSV 空间:
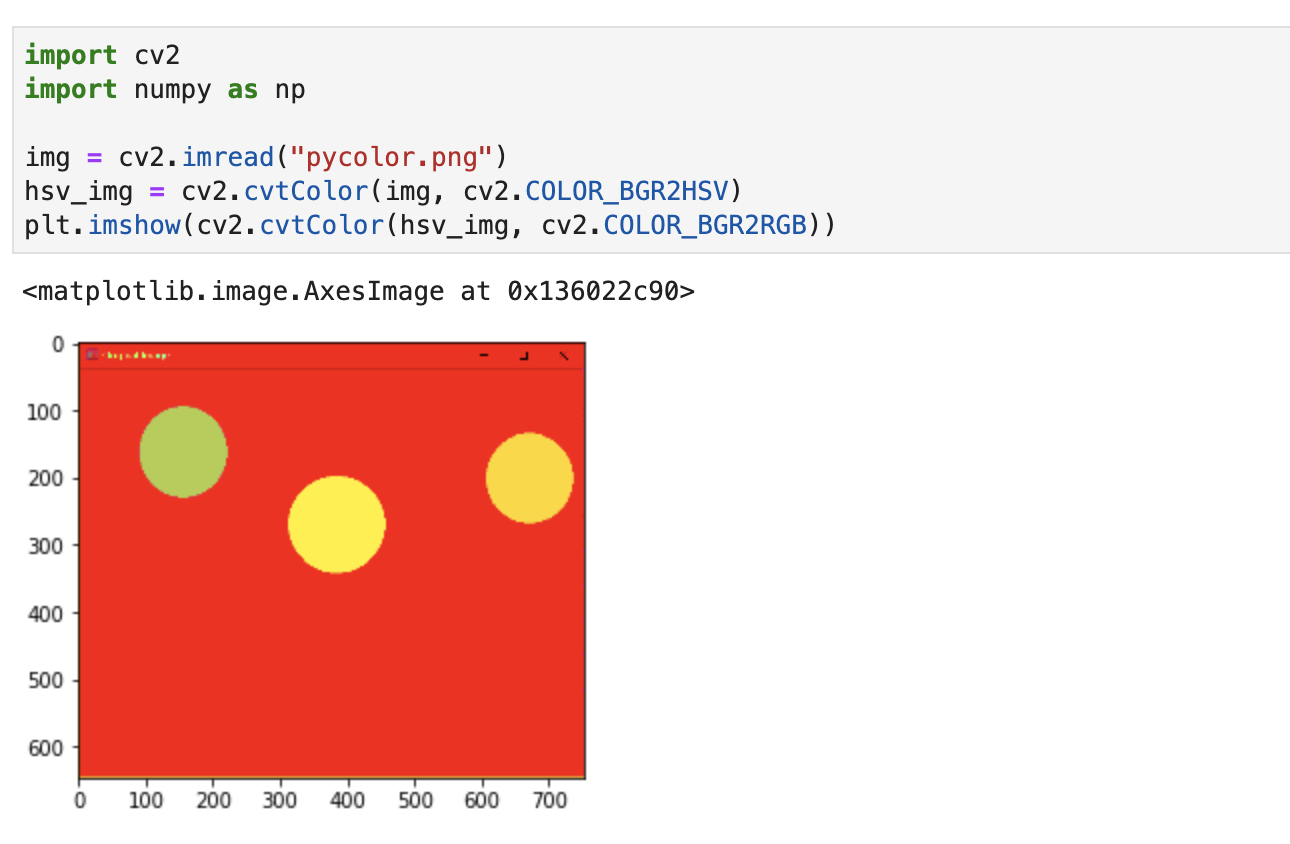
接着需要通过 Numpy 设置绿色像素值的上下范围区间:
lower_green = np.array([34, 177, 76])
upper_green = np.array([255, 255, 255])
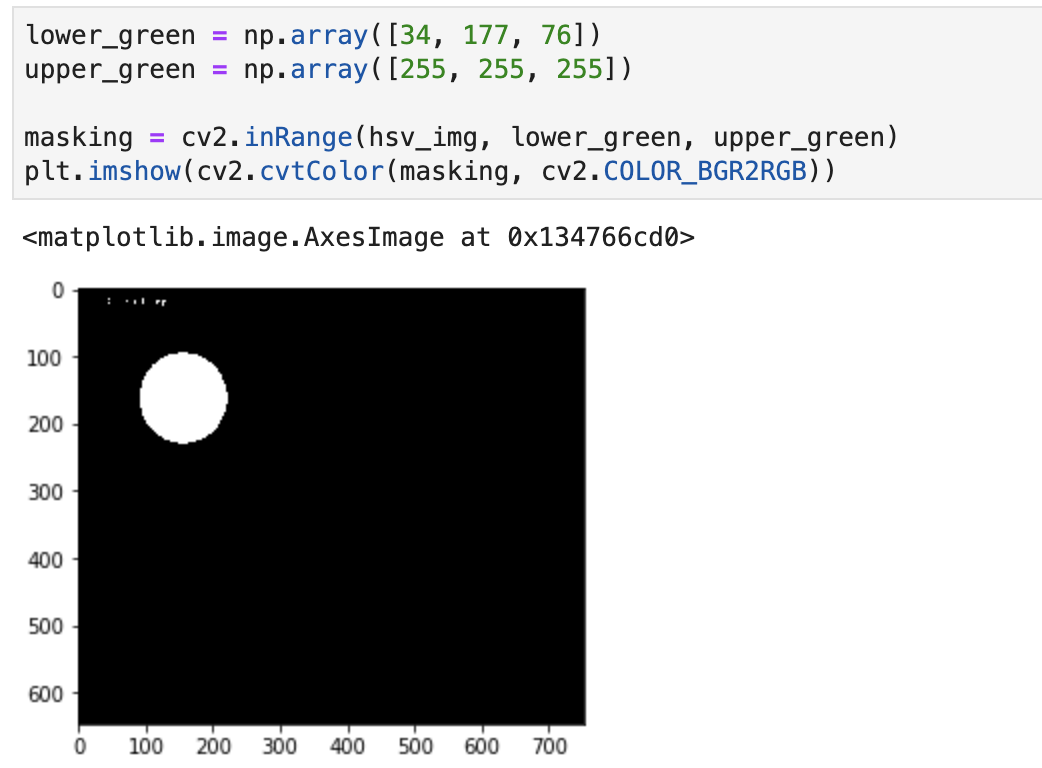
接着通过 inRange() 方法来判断输入图片中是否包含在设置后的绿色区间范围内,如果有,那就表示检测到绿色这种颜色的像素区域。
完整实现的代码:
import cv2
import numpy as np
img = cv2.imread("pycolor.png")
hsv_img = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
plt.imshow(cv2.cvtColor(hsv_img, cv2.COLOR_BGR2RGB))
lower_green = np.array([34, 177, 76])
upper_green = np.array([255, 255, 255])
masking = cv2.inRange(hsv_img, lower_green, upper_green)
plt.imshow(cv2.cvtColor(masking, cv2.COLOR_BGR2RGB))
实现结果:
14. 去噪
OpenCV 中提供了下面 4 种图像去噪的方法:
fastNlMeansDenoising():从灰度图中降噪;fastNlMeansDenoisingColored():从彩色图片中降噪fastNlMeansDenoisingMulti():从灰度图片帧(灰度视频)中降噪;fastNlMeansDenoisingColoredMulti():从彩色图片帧中降噪
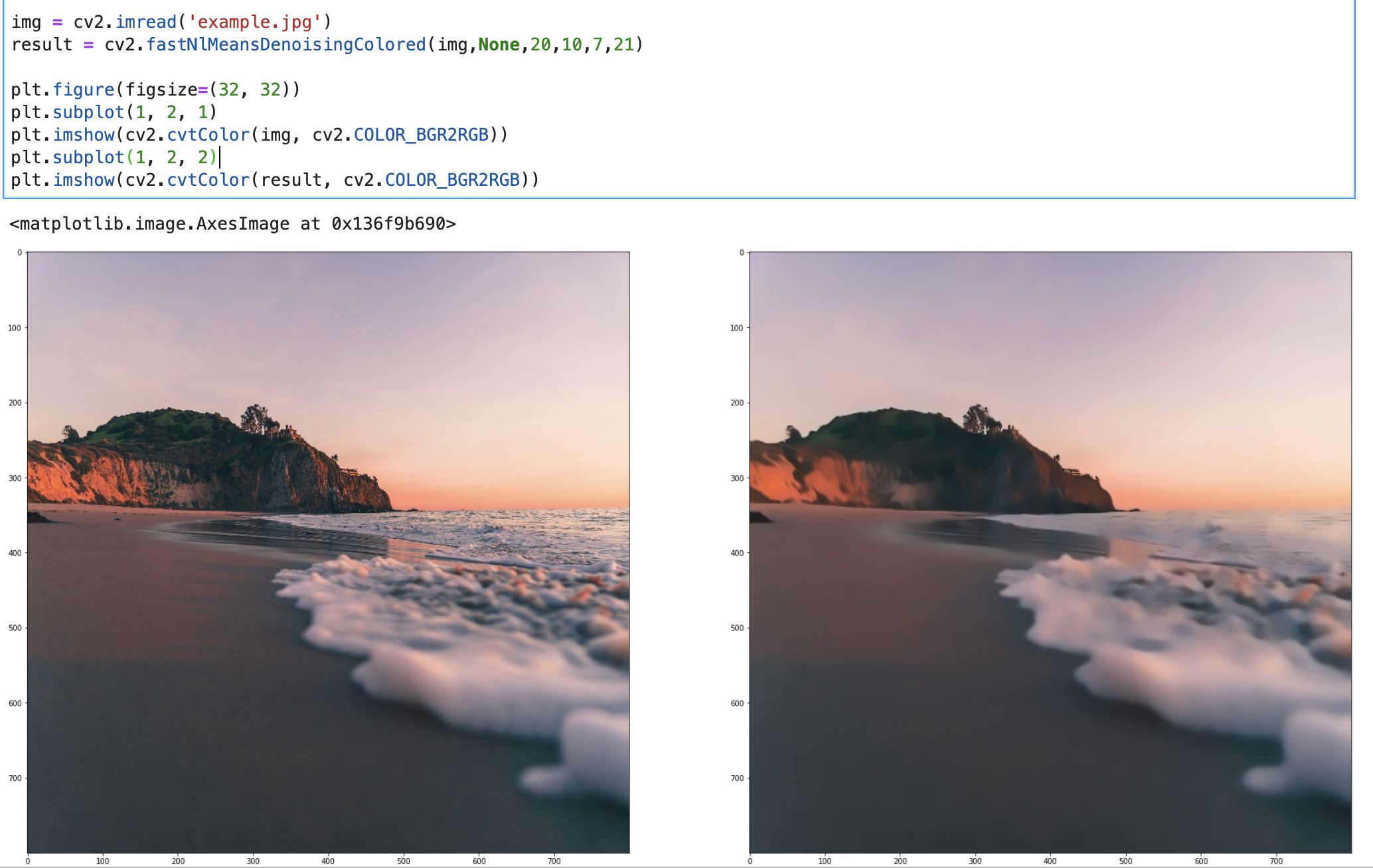
本次例子会用第二种方法:fastNlMeansDenoisingColored()
实现的代码如下所示:
import cv2
img = cv2.imread('example.jpg')
result = cv2.fastNlMeansDenoisingColored(img,None,20,10,7,21)
plt.figure(figsize=(32, 32))
plt.subplot(1, 2, 1)
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.subplot(1, 2, 2)
plt.imshow(cv2.cvtColor(result, cv2.COLOR_BGR2RGB))
其中对于方法fastNlMeansDenoisingColored()的个参数分别是:
- 输入的原图
- 输出图片,不过这里设置为 None,我们直接保存到
result变量里; - 滤波器强度
- 和滤波器强度一样,但针对的是彩色图片的噪声,一般设置为 10;
- 模板块像素大小,必须是奇数,一般设置为 7;
- 计算给定像素均值的窗口大小
实现结果:
15. 检测图片的轮廓
轮廓是图片中将连续的点连接在一起的曲线,通常检测轮廓的目的是为了检测物体。本例中使用的图片如下:

检测轮廓的步骤如下:
- 读取图片,并转为灰度图;
- 通过
threshold() 找到阈值,通常设置 127-255 的区间 - 采用
findContours()进行检测轮廓,具体使用方法可以查看官方文档:https://docs.opencv.org/3.4.2/d3/dc0/group__imgproc__shape.html#ga17ed9f5d79ae97bd4c7cf18403e1689a - 最后是通过
drawContours()来绘制画好的轮廓,然后展示出来
实现代码:
import cv2
img = cv2.imread('opencv_contour_example.png')
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
retval, thresh = cv2.threshold(gray_img, 127, 255, 0)
img_contours, _ = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
cv2.drawContours(img, img_contours, -1, (0, 255, 0))
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
实现效果:

16. 移除图片的背景
移除图片背景的实现思路是这样的:
- 检测图片主要物体的轮廓;
- 为背景通过
np.zeros生成一个蒙版 mask; - 采用
bitwise_and运算符来结合检测轮廓后的图片和蒙版 mask
本次样例使用的原图:

实现代码:
import cv2
import numpy as np
img = cv2.imread("opencv_bg.png")
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
_, thresh = cv2.threshold(gray_img, 127, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
img_contours = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)[-2]
img_contours = sorted(img_contours, key=cv2.contourArea)
for i in img_contours:
if cv2.contourArea(i) > 100:
break
mask = np.zeros(img.shape[:2], np.uint8)
cv2.drawContours(mask, img_contours, -1, 255, -1)
new_img = cv2.bitwise_and(img, img, mask=mask)
plt.figure(figsize=(32, 32))
plt.subplot(1, 2, 1)
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.subplot(1, 2, 2)
plt.imshow(cv2.cvtColor(new_img, cv2.COLOR_BGR2RGB))
实现结果:

小结
本文是简单介绍了基于 opencv 实现的一些图像处理操作,从基础的旋转,裁剪,调整大小,到模糊图片,边缘检测,修正歪曲文字,去噪,检测轮廓等操作,都给出了基础的实现代码,如果需要更深入了解,这里推荐:
- opencv 官方文档:https://docs.opencv.org/master/d9/df8/tutorial_root.html
- https://github.com/ex2tron/OpenCV-Python-Tutorial
- 图像处理 100 问:https://github.com/gzr2017/ImageProcessing100Wen
最后,原文地址:
https://likegeeks.com/python-image-processing/
代码和样例图片的地址:
https://github.com/ccc013/CodesNotes/tree/master/opencv_notes
https://github.com/ccc013/CodesNotes/blob/master/opencv_notes/opencv_image_process_tutorial.ipynb
欢迎关注我的公众号--算法猿的成长

