

linux 命令学习1——tr命令
tr命令
NAME
tr - translate or delete characters
SYNOPSIS
tr [OPTION]... SET1 [SET2]
DESCRIPTION
Translate, squeeze, and/or delete characters from standard input, writing to standard output.
-c, -C, --complement
use the complement of SET1
-d, --delete
delete characters in SET1, do not translate
-s, --squeeze-repeats
replace each sequence of a repeated character that is listed in
the last specified SET, with a single occurrence of that character
-t, --truncate-set1
first truncate SET1 to length of SET2
--help display this help and exit
--version
output version information and exit
SETs are specified as strings of characters. Most represent themselves.
Interpreted sequences are:
\NNN character with octal value NNN (1 to 3 octal digits)
\\ backslash
\a audible BEL
\b backspace
\f form feed
\n new line
\r return
\t horizontal tab
\v vertical tab
eg: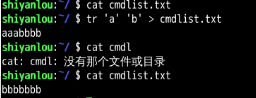 将 从标准输入的字符把 a替换成b 重定向到cmdlist.txt 文件中(Ctrl+z 停止输入字符)
将 从标准输入的字符把 a替换成b 重定向到cmdlist.txt 文件中(Ctrl+z 停止输入字符)
任务: 分别计算上述命令的MAN文档的行数
STEP1: 将上述命令放置到一个文本文件中, 命令为 cmds.list

ls, cp, rm , mv, cat , head, tail , cd , pwd, mkdir , touch, rename, less, find, which, locate, chmod, chown, less, ln, tar, umask
grep, sed, awk, tr, uniq, sort, join, cut, tee, wc,
ps, top, fg, kill, who,
netstat , scp , ssh, ping, wget
set, alias, . , source, sudo , su, date,
man ,
xargs
STEP2:使用 tr 命令先将 , 转化为 换行,并去掉空格和空行;
$ tr ',' '\n' < cmds.list | tr -d ' ' | grep -v '^$' > result.mid
(grep -v '^$'意思是取非空行的行,'^$’为正则表达式)
step3及实验结果待续

