

rocketMq和kafka的性能对比和原理
根据阿里巴巴中间件团队对rocketMq,kafka和rabbitMq的发送消息性能的测试,在单机同步发送的场景下,Kafka>RocketMQ>RabbitMQ。如下图:
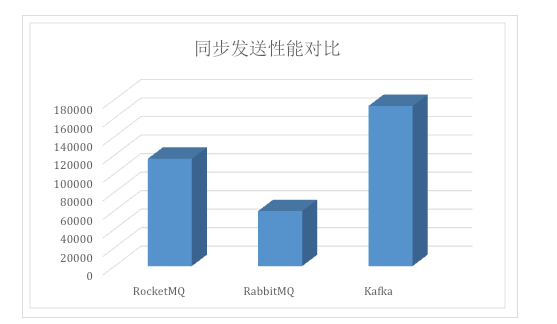
Kafka的吞吐量高达17.3w/s,
RocketMQ吞吐量在11.6w/s
RabbitMQ的吞吐量5.95w/s,CPU资源消耗较高。它支持AMQP协议,实现非常重量级,为了保证消息的可靠性在吞吐量上做了取舍。
为什么kafka和rocketMq性能如此高呢,详见以下文章:https://blog.csdn.net/z69183787/article/details/80323581
https://www.cnblogs.com/cai-cai777/p/10212907.html
kafka和rocketMq都使用顺序io写磁盘和零复制。而Kafka的TPS跑到单机百万,rocketMQ单机写入TPS单实例约7万条/秒,单机部署3个Broker,可以跑到最高12万条/秒,消息大小10个字节。
kafka性能如此之高主要是由于Producer端将多个小消息合并,批量发向Broker:
kafka采用异步发送的机制,当发送一条消息时,消息并没有发送到broker而是缓存起来,然后直接向业务返回成功,当缓存的消息达到一定数量时再批量发送。此时减少了网络io,从而提高了消息发送的性能,但是如果消息发送者宕机,会导致消息丢失,业务出错,所以理论上kafka利用此机制提高了io性能却降低了可靠性。
RocketMQ却没有这样做,主要原因在于:
- 制片人通常使用的Java语言,缓存过多消息,GC是个很严重的问题
- Producer调用发送消息接口,消息未发送到Broker,向业务返回成功,此时Producer宕机,会导致消息丢失,业务出错
- Producer通常为分布式系统,且每台机器都是多线程发送,我们认为线上的系统单个Producer每秒产生的数据量有限,不可能上万。
- 缓存的功能完全可以由上层业务完成。
但是 当broker里面的topic的partition数量过多时,kafka的性能却不如rocketMq,是因为kafka和rocketMq在存储机制上的不同。
kafka和rocketMq都使用文件存储,但是,kafka是一个分区一个文件,当topic过多,分区的总量也会增加,kafka中存在过多的文件,当对消息刷盘时,就会出现文件竞争磁盘,出现性能的下降。

一个partition(分区)一个文件,顺序读写。这样带来的影响是,一个分区只能被一个消费组中的一个 消费线程进行消费,因此可以同时消费的消费端也比较少。
而rocketMq中,所有的队列都存储在一个文件中,每个队列的存储的消息量也比较小,因此topic的增加对rocketMq的性能的影响较小。也从而rocketMq可以存在的topic比较多,可以适应比较复杂的业务。
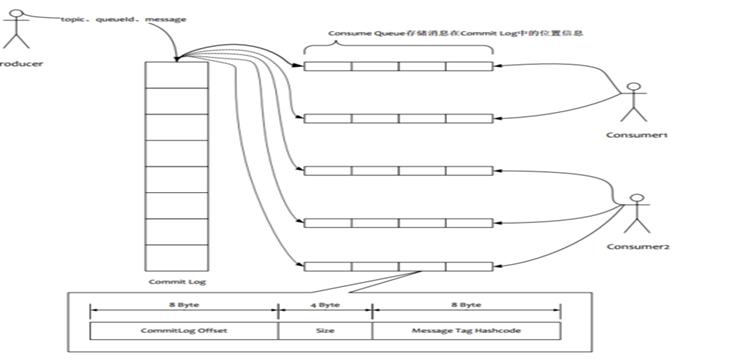
所有的队列存储一个文件(commitlog)中,所以rocketmq是顺序写io,随机读。每次读消息时先读逻辑队列consumQue中的元数据,再从commitlog中找到消息体。增加了开销。

资料来源:http://jm.taobao.org/2016/04/07/kafka-vs-rocketmq-topic-amout/

