
缓存穿透
什么是缓存穿透?
缓存穿透,是指查询一个数据库一定不存在的数据。正常的使用缓存流程大致是,数据查询先进行缓存查询,如果key不存在或者key已经过期,再对数据库进行查询,并把查询到的对象,放进缓存。如果数据库查询对象为空,则不放进缓存,也就是缓存和数据库都查询不到这条数据,导致每一次都请求到数据库中去。
这种查询不存在数据的现象我们称为缓存穿透。
缓存穿透带来的问题
假设一下用大量的请求去查到一个不存在ID的数据,可能会导致你的数据库由于压力过大而宕掉。
解决方法
- Redis缓存
之所以会发生缓存穿透在于缓存中没有存储这些空数据的key。从而导致每次请求都会到数据库。
那么我们可以采用将这些key对应的值设置为null并存储到缓存中,当再一次请求时会先去查询Redis是否有该key,如果有则直接返回null,没有则走后面的业务。 - BloomFilter
BloomFilter 类似于一个hbase set 用来判断某个元素(key)是否存在于某个集合中。
这种方式在大数据场景应用比较多。
比如:
1.Hbase 中使用它去判断数据是否在磁盘上。
2.爬虫场景判断url 是否已经被爬取过。
这种方案可以加在第一种方案中,在缓存之前在加一层 BloomFilter ,在查询的时候先去 BloomFilter 去查询 key 是否存在,如果不存在就直接返回,存在再走查缓存 -> 查 DB。
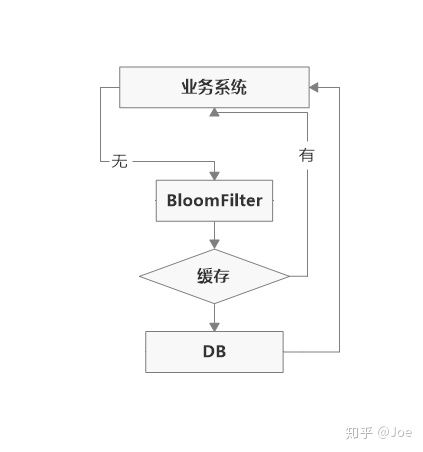
如何选择?
针对于一些恶意攻击,攻击带过来的大量不存在的key建议采用使用第二种方案进行过滤掉这些key。
对于key异常多、请求重复率比较低的数据建议采用使用第一种方案过滤掉并根据情况设置过期时间。


