hive表分区存储
1、创建hive分区表
create table if not exists tb1
(
id string,
name string
)
partitioned by(dt string)
2、分区表的字段个数可以大于数据源表
项目背景:数据源为SQLServer,每天新增200W条数据,需要每天定时导入到Hive库中。
问题:用户指定需要按照Timestamp字段分区,因为SQLServer库和Hive库分别在两个不同的系统中,这样一来,如果拿Timestamp字段作为分区字段,
势必会丢失时间精度(从 yyyy-MM-dd hh:MM:ss.xxxx 丢失到 yyyy-MM-dd),因为这些字段都是工业上的实时读取的值,这个结果不是客户预期的。
解决方案:保持生产数据的结构不变,新建一张表(比生产的库新增一条字段),并以此字段作为分区字段,来完成分区操作(主要解决查询效率问题)
生产系统的表:
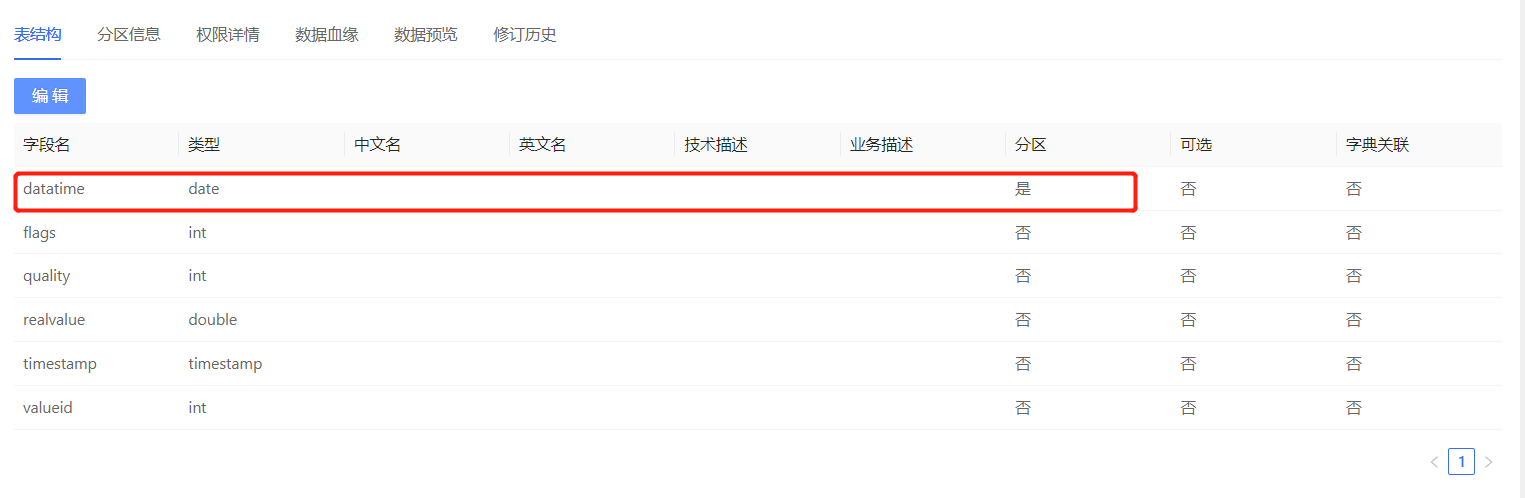
Hive库中建的分区表(新增了一条datatime字段):
建表DDL:
CREATE TABLE `sc_data` (
`ValueID` int,
`Timestamp` timestamp,
`RealValue` double,
`Quality` int,
`Flags` int) partitioned by(datatime date);
Hive库中正确插入数据:

静态指定分区,往分区表插入数据:
insert overwrite table fenqu
partition (dt)
select id,name,dt
from fenqu_ori;
3、对分区表的理解
hive底层是用hdfs来做存储的,所以hive的分区表可以理解为文件夹存储形式。在对分区表进行查询时,分区查询信息可输入可不输入。
但是,在数据量较大时,根据分区查询将极大提高效率。
eg:查询分区数据,其实和正常的SQL查询基本一致,只是如下例子中的create_date字段,是建分区表时的分区字段而已:
select * from AccountRegister where create_date="2014-10-1";
4、动态创建分区表
ref:https://blog.csdn.net/qq_41489540/article/details/108771653
https://blog.csdn.net/qq_44868502/article/details/102851282

 浙公网安备 33010602011771号
浙公网安备 33010602011771号