

基于OpenCV & Dlib & MTCNN的人脸检测的效果对比
ref: https://github.com/vipstone/faceai
ref: https://github.com/imistyrain/MTCNN
PS: 1 安装dlib库花了好长时间,最终在CSDN上花钱下载了一个轮子,安装:pip3 install dlib-19.17.0-cp37-cp37m-win_amd64
链接:https://pan.baidu.com/s/1h7uyJkmxHNVbGlE93eI8VQ
提取码:j8rc
2 我用于测试的图片,是身份证正反面复印件(银行的数据,有的人脸非常模糊~~~)
3 安装mxnet库:pip install mxnet-cu100 (我的cuda是v10.0)
我把原作者的代码改了一下,用于遍历一个文件夹下的所有图片
PS: 用于人脸识别的.dat文件:
链接: https://pan.baidu.com/s/1yo_aawFgly0vjtBatxLrSw 提取码: yh5v
Dlib人脸检测:



1 #coding=utf-8 2 #图片检测 - Dlib版本 3 import cv2 4 import dlib 5 import glob 6 import datetime 7 8 dealedimg = "img/dealedimg/" # 检测到一个人脸,并框正确 9 unhandledimg = "img/unhandledimg/" # 检测不到人脸 10 errorhandledimg = "img/errorhandledimg/" # 检测错误 11 multiFaceimg = "img/multiFaceimg/" # 多张人脸 12 originalimg = "img/originalimg/" 13 14 15 #人脸分类器 16 detector = dlib.get_frontal_face_detector() 17 # 获取人脸检测器 18 predictor = dlib.shape_predictor( 19 "D:\\software\\anaconda3\\Lib\\site-packages\\dlib\\shape_predictor_68_face_landmarks.dat" 20 ) 21 # 程序开始时间 22 startTime = datetime.datetime.now() 23 # 循环遍历originalimg路径下的所有图片 24 count = 0 25 count1 = 0 26 for index, filename in enumerate(glob.glob(originalimg + '*.jpg')): 27 img = cv2.imread(filename) # 读取图片 28 gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转换灰色 29 # 预测出的脸的集合,第二个参数代表图片的放大倍数 30 dets = detector(img, 3) 31 faceCounts = len(dets) 32 imgName = filename.split("\\")[1] 33 # 检测到多个人脸 34 if faceCounts > 1: 35 print("检测到多个人脸==========================") 36 cv2.imwrite(multiFaceimg + imgName, img) 37 continue 38 # 检测不到人脸 39 if faceCounts == 0: 40 count = count + 1 41 print("未检测到人脸。。。。。count = " + count.__str__()) 42 cv2.imwrite(unhandledimg + imgName, img) 43 continue 44 # 检测到一个人脸 45 if faceCounts: 46 # 寻找人脸的68个标定点 47 shape = predictor(img, dets[0]) 48 # 特征点个数 49 characterCounts = len(shape.parts()) 50 if characterCounts < 68: 51 # 如果特征点个数不足68个,就可以说明不是人脸(不能完全说明??) 52 print("框到的矩形不是人脸+++++++++++++++++++++++") 53 cv2.imwrite(errorhandledimg + imgName, img) 54 continue 55 # 框到了正确的一个人脸,则遍历所有点,打印出其坐标,并圈出来 56 count1 = count1 + 1 57 print("--------------框到的特征点的个数: " + characterCounts.__str__() + "个,第" + count1.__str__() + "张识别正确的图----------------") 58 for pt in shape.parts(): 59 pt_pos = (pt.x, pt.y) 60 cv2.circle(img, pt_pos, 1, (0, 255, 0), 2) 61 # 在图片中标注人脸,并显示 62 left = dets[0].left() 63 top = dets[0].top() 64 right = dets[0].right() 65 bottom = dets[0].bottom() 66 cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0), 2) 67 cv2.imwrite(dealedimg + imgName, img) 68 # 程序结束时间 69 endTime = datetime.datetime.now() 70 print((endTime - startTime))
OpenCV人脸检测:
1 #coding=utf-8 2 #图片检测 - OpenCV版本 3 import cv2 4 import datetime 5 import glob 6 7 dealedimg = "img/dealedimg/" 8 unhandledimg = "img/unhandledimg/" 9 originalimg = "img/originalimg/" 10 multiFaceimg = "img/multiFaceimg/" # 多张人脸 11 filepath = "img/originalimg/" 12 # OpenCV人脸识别分类器 13 # 在使用OpenCV的人脸检测之前,需要一个人脸训练模型,格式是xml的,我们这里使用OpenCV提供好的人脸分类模型xml 14 # 调用已经训练好的模型 15 classifier = cv2.CascadeClassifier( 16 "D:\software\Python37\Lib\site-packages\opencv-master\data\haarcascades\haarcascade_frontalface_default.xml" 17 ) 18 19 # 程序开始时间 20 startTime = datetime.datetime.now() 21 # 循环遍历filepath路径下的所有图片 22 count = 0 23 for index, filename in enumerate(glob.glob(originalimg + '*.jpg')): 24 25 img = cv2.imread(filename) # 读取图片 26 gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转换灰色 27 # 直接阈值化是对输入的单通道矩阵逐像素进行阈值分割。 28 ret, binary44 = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_TRIANGLE) 29 # 大津法二值化 30 ret, binaryOTSU = cv2.threshold(gray, 100, 255, cv2.THRESH_OTSU) 31 # 自适应阈值化能够根据图像不同区域亮度分布,改变阈值 32 binary = cv2.adaptiveThreshold(gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 25, 10) 33 # 高斯滤波 - 去噪 34 img_GaussianBlur = cv2.GaussianBlur(binary, (7, 7), 0) 35 36 color = (0, 255, 0) # 定义绘制颜色 37 # 调用识别人脸 38 # classifier.detectMultiScale()参数讲解: 39 # 参数1:image - -待检测图片,一般为灰度图像加快检测速度; 40 # 41 # 参数2:objects - -被检测物体的矩形框向量组; 42 # 参数3:scaleFactor - -表示在前后两次相继的扫描中,搜索窗口的比例系数。默认为1 43 # .1 44 # 即每次搜索窗口依次扩大10 %; 45 # 参数4:minNeighbors - -表示构成检测目标的相邻矩形的最小个数(默认为3个)。 46 # 如果组成检测目标的小矩形的个数和小于 47 # min_neighbors - 1 48 # 都会被排除。 49 # 如果min_neighbors 50 # 为 51 # 0, 则函数不做任何操作就返回所有的被检候选矩形框, 52 # 这种设定值一般用在用户自定义对检测结果的组合程序上; 53 # 参数5:flags - -要么使用默认值,要么使用CV_HAAR_DO_CANNY_PRUNING,如果设置为 54 # 55 # CV_HAAR_DO_CANNY_PRUNING,那么函数将会使用Canny边缘检测来排除边缘过多或过少的区域, 56 # 57 # 因此这些区域通常不会是人脸所在区域; 58 # 参数6、7:minSize和maxSize用来限制得到的目标区域的范围。 59 # 图片放大 60 fx = 2 61 fy = 2 62 img2 = cv2.resize(img, (0, 0), fx=fx, fy=fy, interpolation=cv2.INTER_CUBIC) 63 64 faceRects = classifier.detectMultiScale( 65 img2, scaleFactor=1.2, minNeighbors=3, minSize=(32, 32)) 66 imgName = filename.split("\\")[1] 67 faceCounts = len(faceRects) 68 if faceCounts > 1: # 检测到多个人脸 69 print("检测到多个人脸==========================") 70 cv2.imwrite(multiFaceimg + imgName, img) 71 continue 72 # 检测不到人脸 73 if faceCounts == 0: 74 count = count + 1 75 print("未检测到人脸。。。。。count = " + count.__str__()) 76 cv2.imwrite(unhandledimg + imgName, img) 77 continue 78 # 检测到一个人脸 79 if faceCounts: # 大于0则检测到人脸 80 for faceRect in faceRects: # 单独框出每一张人脸 81 x, y, w, h = faceRect 82 # 框出人脸 83 cv2.rectangle(img, (x, y), (x + h, y + w), color, 2) 84 # 左眼 85 cv2.circle(img, (x + w // 4, y + h // 4 + 30), min(w // 8, h // 8), 86 color) 87 # 右眼 88 cv2.circle(img, (x + 3 * w // 4, y + h // 4 + 30), min(w // 8, h // 8), 89 color) 90 # 嘴巴 91 cv2.rectangle(img, (x + 3 * w // 8, y + 3 * h // 4), 92 (x + 5 * w // 8, y + 7 * h // 8), color) 93 # 程序结束时间 94 endTime = datetime.datetime.now() 95 print((endTime - startTime)) 96 # 保存画了框的图片 97 # 保存圖像 98 x = x + 1 99 # img_saving_path = filepath.replace('.jpg', str(x) + '.jpg') 100 # print(str) 101 cv2.imwrite(dealedimg + imgName, img) 102 height, width = img.shape[:2] 103 size = (int(width * 0.5), int(height * 0.5)) 104 img2 = cv2.resize(img, size, interpolation=cv2.INTER_AREA) 105 # cv2.imshow("image", img2) # 显示图像 106 # cv2.waitKey(0) 107 cv2.destroyAllWindows()
MTCNN人脸检测:
1 # coding: utf-8 2 import mxnet as mx 3 from mtcnn_detector import MtcnnDetector 4 import cv2 5 import os 6 import time 7 import glob 8 import datetime 9 10 dealedimg = "../imgs/dealedimg/" # 检测到一个人脸,并框正确 11 unhandledimg = "../imgs/unhandledimg/" # 检测不到人脸 12 errorhandledimg = "../imgs/errorhandledimg/" # 检测错误 13 multiFaceimg = "../imgs/multiFaceimg/" # 多张人脸 14 originalimg = "../imgs/originalimg/" 15 # 程序开始时间 16 startTime = datetime.datetime.now() 17 # 循环遍历originalimg路径下的所有图片 18 19 20 def testimg(detector): 21 count = 0 22 count1 = 0 23 for index, filename in enumerate(glob.glob(originalimg + '*.jpg')): 24 img = cv2.imread(filename) # 读取图片 25 gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转换灰色 26 imgName = filename.split("\\")[1] 27 t1 = time.time() 28 results = detector.detect_face(img) 29 print('time: ', time.time() - t1) 30 if results is not None: 31 faceCounts = len(results[0]) 32 total_boxes = results[0] 33 points = results[1] 34 print("-------------length is: " + faceCounts.__str__()+"--------------") 35 # 检测到多个人脸 36 if faceCounts > 1: 37 print("检测到多个人脸==========================") 38 for b in total_boxes: 39 cv2.rectangle(img, (int(b[0]), int(b[1])), (int(b[2]), int(b[3])), (0, 255, 0)) 40 41 for p in points: 42 for i in range(5): 43 cv2.circle(img, (p[i], p[i + 5]), 1, (0, 255, 0), 2) 44 cv2.imwrite(multiFaceimg + imgName, img) 45 continue 46 # 检测不到人脸 47 if faceCounts == 0: 48 count = count + 1 49 print("未检测到人脸。。。。。count = " + count.__str__()) 50 cv2.imwrite(unhandledimg + imgName, img) 51 continue 52 # 检测到一个人脸 53 if faceCounts: 54 # draw = img.copy() 55 for b in total_boxes: 56 cv2.rectangle(img, (int(b[0]), int(b[1])), (int(b[2]), int(b[3])), (0, 255, 0), 2) 57 58 for p in points: 59 for i in range(5): 60 cv2.circle(img, (p[i], p[i + 5]), 1, (0, 255, 0), 2) 61 62 # 框到了正确的一个人脸 63 count1 = count1 + 1 64 print("第" + count1.__str__() + "个识别正确的图片") 65 cv2.imwrite(dealedimg + imgName, img) 66 # 程序结束时间 67 endTime = datetime.datetime.now() 68 print((endTime - startTime)) 69 else: 70 print("===========未检测到人脸===================" ) 71 cv2.imwrite(errorhandledimg + imgName, img) 72 continue 73 # -------------- 74 # test on camera 75 # -------------- 76 # def testcamera(detector): 77 # 78 # camera = cv2.VideoCapture(0) 79 # while True: 80 # grab, frame = camera.read() 81 # img = cv2.resize(frame, (640,480)) 82 # 83 # t1 = time.time() 84 # results = detector.detect_face(img) 85 # print('time: ',time.time() - t1) 86 # 87 # if results is None: 88 # cv2.imshow("detection result", img) 89 # cv2.waitKey(1) 90 # continue 91 # 92 # total_boxes = results[0] 93 # points = results[1] 94 # 95 # draw = img.copy() 96 # for b in total_boxes: 97 # cv2.rectangle(draw, (int(b[0]), int(b[1])), (int(b[2]), int(b[3])), (255, 255, 255)) 98 # 99 # for p in points: 100 # for i in range(5): 101 # cv2.circle(draw, (p[i], p[i + 5]), 1, (255, 0, 0), 2) 102 # cv2.imshow("detection result", draw) 103 # key=cv2.waitKey(1) 104 # if 'q'==chr(key & 255) or 'Q'==chr(key & 255): 105 # break; 106 107 108 if __name__=="__main__": 109 detector = MtcnnDetector(model_folder='../model/mxnet', ctx=mx.cpu(0), num_worker = 4 , accurate_landmark = False) 110 testimg(detector) 111 # testcamera(detector)c
人脸检测效果对比:
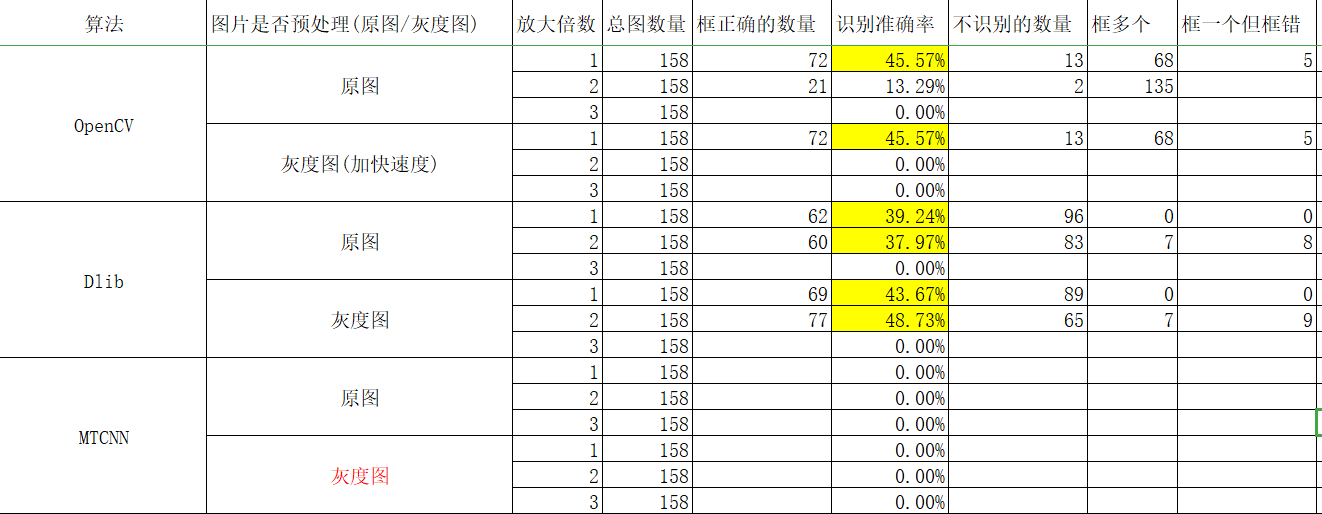
PS: 还有一些测试没有弄完,我先发一版,持续更新~~~


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 字符编码:从基础到乱码解决