

python模块(os,sys,hashlib,collections)
列出目录下所有文件
os.listdir(path=None):列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式返回。
创建文件夹
os.mkdir(path):创建文件夹
os.makedirs(name):递归创建文件夹
删除文件夹
os.rmdir(path):删除文件夹(只能删除空目录,有文件不能删除)
os.removedirs(name):递归删除到根目录(只能删除空目录,目录里不能有文件)
文件相关
os.remove(path):删除一个文件
os.rename(src,dst):重命名文件/目录
os.stat(path):获取文件/目录信息
操作系统相关
os.sep:输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep:输出当前平台使用的行终止符,win下为"\r\n",Linux下为"\n"
os.pathsep:输出用于分割文件路径的字符串 win下为";",Linux下为:":"
os.name:输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.environ:获取系统环境变量
执行系统命令相关
os.system(command):运行shell命令
os.popen(cmd).read():运行shell命令,获取执行结果
path系列路径相关
os.path.abspath(path):返回path规范化的绝对路径
os.path.split(path):将path分割成目录和文件名组成的元组。
os.path.dirname(path):返回path的目录。其实就是os.path.split(path)的第一个元素。
os.path.basename(path):如果path是文件的路径则返回文件名,如果path是一个文件夹,这返回空。
os.path.exists(path):如果path存在返回True否则返回False
os.path.isabs(path):如果path是绝对路径,返回True
os.path.isfile(path):如果path是一个文件,返回True。否则返回False
os.path.isdir(path):如果path是一个目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]):将多个路径组合后返回,第一个绝对路径之前的参数将被忽略。
os.path.getatime(path):返回path所指向的文件或者目录的最后访问时间
os.path.getmtime(path):返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path):获取文件大小.对目录不准
os.getcwd():获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname"):切换目录
os.curdir:返回当前目录: ('.')
os.pardir:获取当前目录的父目录字符串名:('..')
sys模块
sys.argv:命令行参数List,第一个元素是程序本身路径
sys.exit(n):退出程序,正常退出时exit(0),错误退出sys.exit(1)
sys.version:获取Python解释程序的版本信息
sys.path:返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform:返回操作系统平台名称
hashlib模块
摘要算法,摘要算法又称哈希算法、散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示)。
摘要算法就是通过摘要函数f()对任意长度的数据data计算出固定长度的摘要digest,目的是为了发现原始数据是否被人篡改过。
摘要算法之所以能指出数据是否被篡改过,就是因为摘要函数是一个单向函数,计算f(data)很容易,但通过digest反推data却非常困难。而且,对原始数据做一个bit的修改,都会导致计算出的摘要完全不同。
我们以常见的摘要算法MD5为例,计算出一个字符串的MD5值:
import hashlib md5 = hashlib.md5() # 创建_hashlib.HASH的对象 md5.update("md5".encode("utf-8")) # 字符串md5是要被加密的数据 md5_hex = md5.hexdigest() # 获取md5加密后的数据 print(md5_hex) # 打印内容如下 1bc29b36f623ba82aaf6724fd3b16718
如果数据量很大,可以分块多次调用update(),最后计算的结果是一样的:
MD5是最常见的摘要算法,速度很快,生成结果是固定的128 bit字节,通常用一个32位的16进制字符串表示。
另一种常见的摘要算法是SHA1,调用SHA1和调用MD5完全类似:
import hashlib sha1 = hashlib.sha1() sha1.update("sha1".encode("utf-8")) sha1_hex = sha1.hexdigest() print(sha1_hex) # 打印内容如下 415ab40ae9b7cc4e66d6769cb2c08106e8293b48
SHA1的结果是160 bit字节,通常用一个40位的16进制字符串表示。
SHA1的安全系数比MD5还要高一些,而且摘要的长度要比MD5长。
比SHA1更安全的算法是SHA256和SHA512,不过越安全的算法越慢,而且摘要长度更长。用法与SHA1一样。
collections模块
Python内置模块,在内置数据类型(dict、list、set、tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等。
1、namedtuple: 生成可以使用名字来访问元素内容的tuple。
2、deque: 双端队列,可以快速的从头或尾追加和删除元素。
3、Counter: 计数器,主要用来计数。
4、OrderedDict: 有序字典。
5、defaultdict: 带有默认值的字典。
namedtuple:命名元组。
我们知道元组是不可被修改的容器,如元组(10,2),单从这个元组的元素来看,我们不知道这个元组的元素到底表示的是什么。它可以表示一对普通数字,亦可以表示一个坐标轴的两个坐标,还可以表示10的2次幂等,为了解决这个问题namedtuple应运而生。下面是基础示例:
我们假设(10,2)是一个坐标:
from collections import namedtuple # 创建命名元组对象命名,并指定元组长度 point = namedtuple("point",["x","y"]) # 创建命名元组 tuple_1 = point(10,2) # 以x,y的形式打印元素 print(tuple_1.x,tuple_1.y) # 打印内容如下 10 2
下面以计算长方体体积为例:
from collections import namedtuple # 创建命名元组对象命名,并指定元组长度 Cuboid = namedtuple("Cuboid",["len","width","height"]) # 创建命名元组 tuple_1 = Cuboid(10,8,6) # 对比两种打印方式我们就可以看出 # 第一种明显比第二种打印方式更容易理解 print(tuple_1.len * tuple_1.width * tuple_1.height) print(tuple_1[0] * tuple_1[1] * tuple_1[2]) # 打印内容如下 480 480
由上面的示例可以知道有时候利用命名元组引用元素的时候,我们可以更容易理解元素所表示的是什么。这样对代码的理解会更好。
deque:双端队列
deque与列表类似都是线性存储,但是队列只支持在队列的头部和尾部追加和删除元素,属于列表的特殊版。在插入元素和删除元素的效率上比列表更快。因为列表不仅可以在头部和尾部追加和删除元素,还可以在任意位置追加和删除元素。每当列表删除一个非头部和尾部元素的时候,列表就要重新进行排序以保证列表的线性存储。如下图所示:
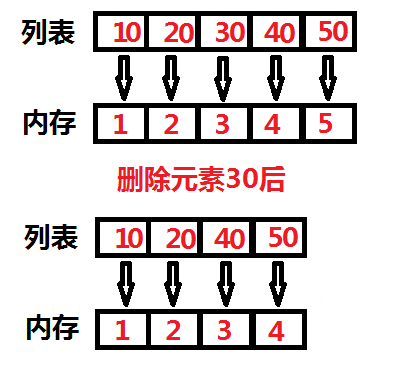
由上图我们知道元素30对应的内存地址是3,删除元素30后,为保证列表的线性,元素40和元素50内存地址都向前移了一位,元素40的内存地址由原来的4变成3,元素50的内存地址由原来的5变成4。如果把列表的第一个元素删除了,后面的整个列表都会依次向前补齐位置。而双端队列不会,无论是删除队列的头还是尾队列的整体不会进行补位的操作。
from collections import deque deque_list = deque([1,2,3,4]) deque_list.appendleft("a") # 向头部追加元素 deque_list.append("z") # 向尾部追加元素 print("追加后的数据是:",deque_list) deque_list.pop() # 删除尾部元素 deque_list.popleft() # 删除头部元素 print("删除后的数据是:",deque_list) # 打印内容如下 追加后的数据是: deque(['a', 1, 2, 3, 4, 'z']) 删除后的数据是: deque([1, 2, 3, 4])
OrderedDict:有序字典
有序字典是按照键插入顺序进行排列的(Python3.X的字典是按着键插入顺序进行排序的,Python2.X的字典键是按照ASCII表的顺序进行排序。)
如下:Python2.7中进行测试。
dict_1 = {} dict_1["z"] = 1 dict_1["c"] = 3 dict_1["a"] = 2 dict_od = OrderedDict() # 有序字典 dict_od["z"] = 1 dict_od["c"] = 3 dict_od["a"] = 2 print(dict_1) print(dict_od) # 打印有序字典 # 打印内容如下 {'a': 2, 'c': 3, 'z': 1} OrderedDict([('z', 1), ('c', 3), ('a', 2)])
defaultdict:默认字典
1、如果默认字典的键不存在,不会报错。
2、在定义默认字典时可以指定值的类型。
示例:将列表中大于3的元素保存到字典的“a”键中,将小于3的元素保存到字典的“b”键中。
如下:使用普通字典的方法。
list_1 = [1,2,3,4,5,6] dict_1 = {} for i in list_1: if i > 3: if "a" in dict_1: dict_1["a"].append(i) else: dict_1["a"] = [i] else: if "b" in dict_1: dict_1["b"].append(i) else: dict_1["b"] = [i] print(dict_1) # 打印内容如下 {'b': [1, 2, 3], 'a': [4, 5, 6]}
如下:使用默认字典的方法。
from collections import defaultdict list_1 = [1,2,3,4,5,6] dict_d = defaultdict(list) # 定义默认字典 for i in list_1: if i > 3: dict_d["a"].append(i) else: dict_d["b"].append(i) print(dict_d) # 打印内容如下 defaultdict(<class 'list'>, {'b': [1, 2, 3], 'a': [4, 5, 6]})
对比两个代码段可以发现使用默认字典的方式代码更加简洁,结构更加清晰明了。
Counter:统计可迭代对象中每个元素出现的次数。
from collections import Counter list_1 = ["a","b","a",1,2,3,1] print(Counter(list_1)) # 打印内容如下 Counter({'a': 2, 1: 2, 'b': 1, 2: 1, 3: 1})
下一篇:shutil、zipfile、tarfile的简单应用:https://www.cnblogs.com/caesar-id/p/10458397.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号