
第三次作业
代码地址:https://github.com/bibubu/WordCount.git
git用户名:bibubu
博客链接:https://www.cnblogs.com/cadaver/
作业链接:https://edu.cnblogs.com/campus/xnsy/SoftwareEngineeringClass1/homework/2882
一 项目需求分析
实现一个命令行程序,输入文件名以命令行参数传入。
例如我们在命令行窗口(cmd)中输入:
wordCount.exe input.txt则会统计input.txt中的以下几个指标
- 统计文件的字符数:
- 只需要统计Ascii码,汉字不需考虑
- 空格,水平制表符,换行符,均算字符
- 统计文件的单词总数,单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
- 英文字母:A-Z,a-z
- 字母数字符号:A-Z,a-z,0-9
- 分割符:空格,非字母数字符号
- 例:file123是一个单词,123file不是一个单词。file,File和FILE是同一个单词
- 统计文件的有效行数:任何包含非空白字符的行,都需要统计。
- 统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
- 按照字典序输出到文件txt:例如,windows95,windows98和windows2000同时出现时,则先输出windows2000
- 输出的单词统一为小写格式
- 输出的格式为
-
characters: number words: number lines: number <word1>: number <word2>: number ...
二 实现过程及关键代码
首先,参数是以命令行参数的形式传入的,而且是多参,所以要先判断识别参数
string inputPath = "input.txt"; //作为输入文件的路径 string outputPath = "output.txt"; //作为输出文件的路径 int m = 0; //词组单词个数 int n = 10; //需要统计最高频率输出的单词个数 if(args.Length == 4) //命令行参数只有-i与-o参数时 { inputPath = args[1]; outputPath = args[3]; } else //命令行参数不止有-i与-o参数时 { for(int i=0;i<args.Length;i++) { if (string.Equals(args[i], "-i"))//获取-i参数 inputPath = args[i + 1]; if (string.Equals(args[i], "-o"))//获取-o参数 outputPath = args[i + 1]; if (string.Equals(args[i], "-m"))//获取-m参数 m = int.Parse(args[i + 1]); if (string.Equals(args[i], "-n"))//获取-n参数 n = int.Parse(args[i + 1]); } }
下面是几个功能模块的实现,统计字符数,单词数,行数,还有频率最高的n个单词,前三个功能主要用到了正则表达式,使用正则表达式来匹配相应的字符串。统计单词频率这一功能则是使用了集合和字典的一些特性来实现的,具体见代码:
/// <summary> /// 统计字符串中所有字符总数 /// </summary> /// <param name="text">要统计字符数的字符串</param> /// <returns>字符总个数</returns> public static int charactersNum(string text) { int ch = 0; ch = Regex.Matches(text, @"[\S| ]").Count; return ch; } /// <summary> /// 统计字符串中所有单词总数 /// </summary> /// <param name="text">要统计的字符串</param> /// <returns>返回一个储存了所有单词的集合包括重复的单词</returns> public static List<string> wordsNum(string text) { List<string> words = new List<string>(); MatchCollection matches = Regex.Matches(text, @"[A-Za-z]{4}[A-Za-z0-9]*(\W|$)"); foreach(Match match in matches) { words.Add(match.Value); } return words; } /// <summary> /// 统计字符串中文本行数 /// </summary> /// <param name="text">要统计的字符串</param> /// <returns>字符串行数</returns> public static int linesNum(string text) { int lines = 0; lines = Regex.Matches(text, @"\r").Count + 1; return lines; } /// <summary> /// 统计一个集合中单词出现的频率 /// </summary> /// <param name="wordList">单词的集合</param> /// <returns>返回一个字典储存了集合中单词与其出现频率</returns> public static Dictionary<string, int> wordFrequency(List<string> wordList) { Dictionary<string,int> dic = new Dictionary<string,int>(); foreach(string s in wordList) //遍历集合中每个单词 { int val; if (dic.TryGetValue(s, out val)) { //如果指定的字典的键存在则将值+1 dic[s] += 1; } else { //不存在,则添加 dic.Add(s, 1); } } return dic; } /// <summary> /// 找出单词字典中出现频率最高的n个单词 /// </summary> /// <param name="dic">储存单词及出现频率的字典</param> /// <param name="n">需要输出单词个数</param> /// <returns>一个储存了频率最高的n个单词及其频率的字典</returns> public static Dictionary<string, int> maxFrequency(Dictionary<string, int> dic, int n) { Dictionary<string, int> d = new Dictionary<string, int>(); //判断需要的单词个数是否超出总单词个数 int x = 0; if (n <= dic.Count) x = n; else x = dic.Count; while(d.Count < x) { List<string> l = new List<string>(); //多个单词有相同频率时储存至这个临时集合中按字典顺序排序 int maxValue = dic.Values.Max(); ; //字典中单词的最高频率 foreach(string s in dic.Keys) { if (dic[s] == maxValue) //获取拥有最高频率的单词 { l.Add(s); //添加至临时集合中 } } //将这一轮获取到的单词从原来的字典中删除 foreach(string s in l) { dic.Remove(s); } //给这一轮获取到的单词按字典顺序排序然后按顺序添加到一个新的字典中 l.Sort(string.CompareOrdinal); foreach(string s in l) { d.Add(s, maxValue); if (d.Count >= x) //获取到足够数量的单词后退出 break; } } return d; }
三 单元测试及错误分析
然后进行单元测试进行错误分析,最开始的时候maxFrequency这一函数始终不能通过单元测试,分析原因后发现错误在对字典的keys集合遍历的过程中对字典中的元素进行了删除操作,导致无法继续遍历下去,于是乎改为遍历结束后再对字典中要删除的元素进行统一删除。最后所有函数都通过了单元测试。
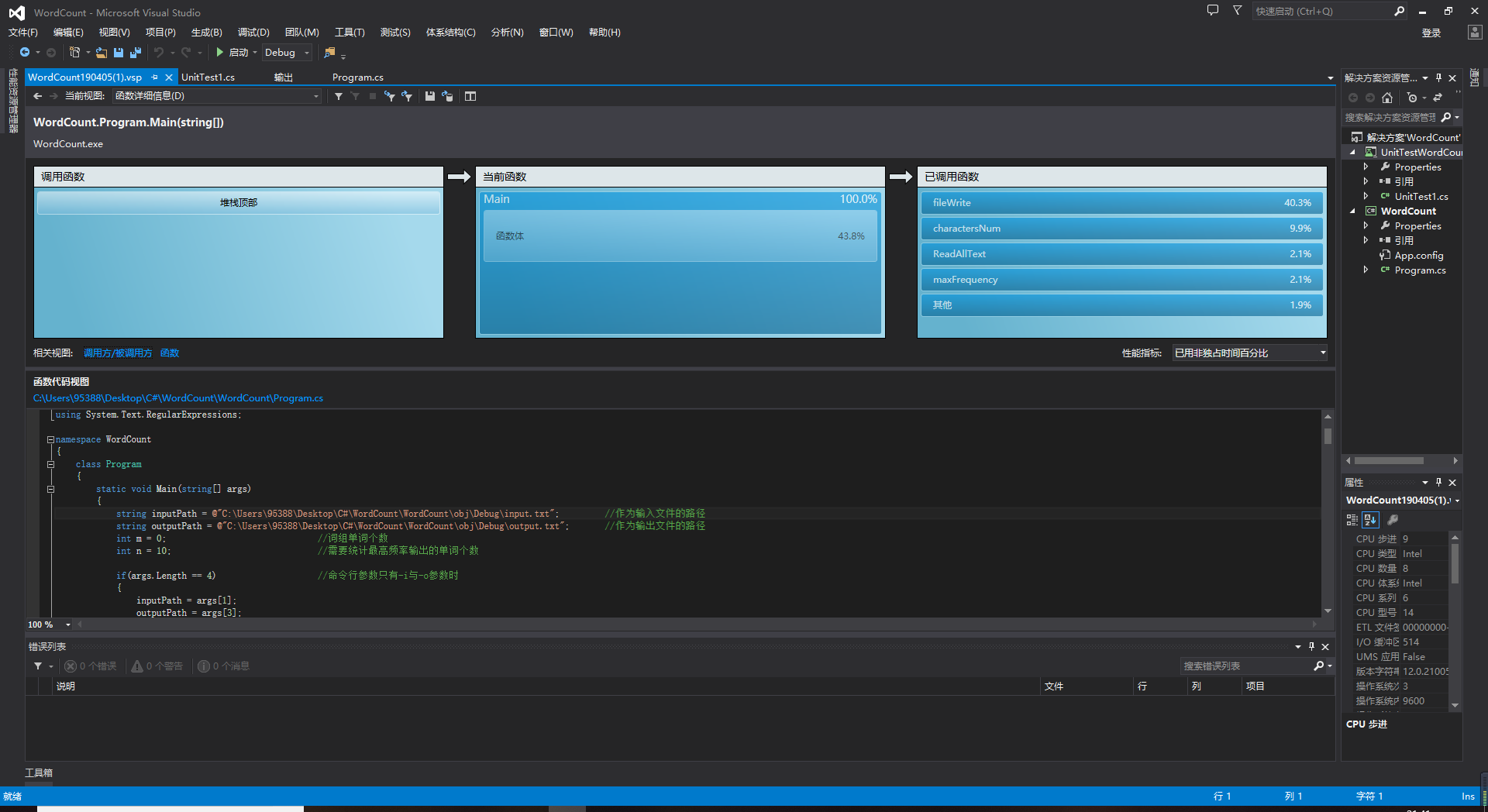
四 效能分析
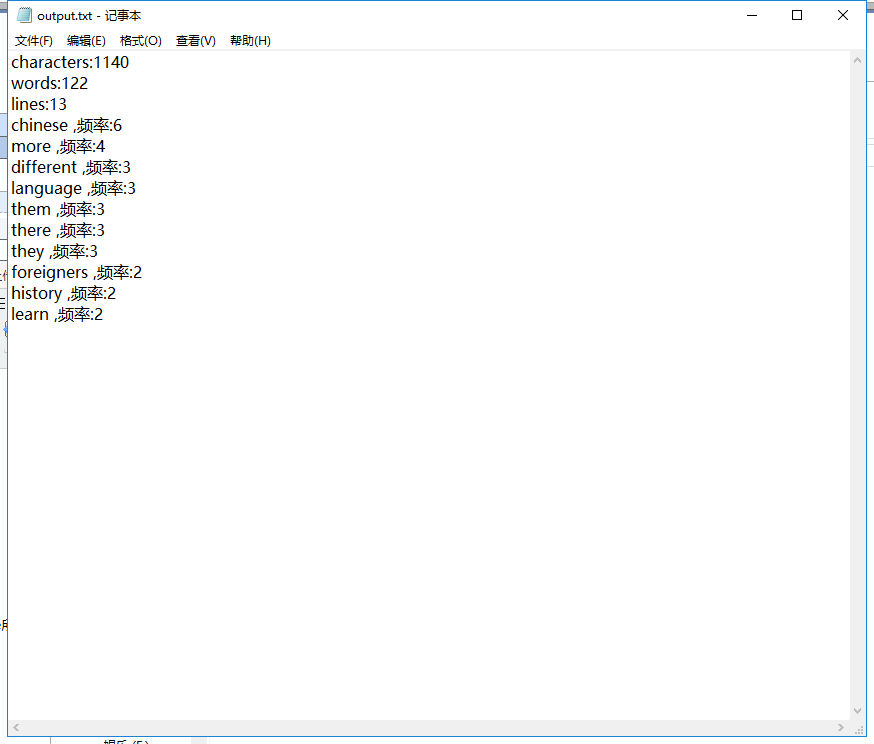
输入和输出文件如下:
经过效能分析后发现函数fileWrite所占用的运行时间比重最大,达到了40.3%,此函数的主要功能是将输出信息写入到指定文件中。占运行时间比重第二的是characterNum函数为9.9%,此函数功能是统计输入文件中的所有字符个数,耗时可能与文本信息的长度有关。其他函数的运行时间占比都很小。
五 小结
经过这次作业后,学到了许多新知识,比如说从命令行接收参数,字典中键值对的一些操作。同时,也对以前学过的知识运用的更熟练了,比如foreach的运用,还有集合与字典的相关操作。总之,每一次项目都收获不小,学到新的知识,经历一些挫折。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号