大数据处理框架之Strom: Storm拓扑的并行机制和通信机制
一、并行机制
Storm的并行度 ,通过提高并行度可以提高storm程序的计算能力。
1.组件关系:
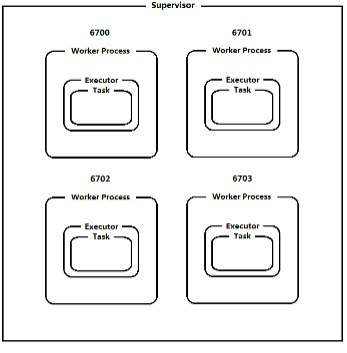
Supervisor node物理节点,可以运行1到多个worker,不能超过supervisor.slots.ports数量;
worker:工作进程,即jvm.为特定拓扑的一个或者多个组件Spout/Bolt产生一个或者多个Executor。默认情况下一个Worker运行一个Executor
Executor:线程Thread,为特定拓扑的一个或者多个组件Spout/Bolt实例运行一个或者多个Task。默认情况下一个Executor运行一个Task。
Task:任务
2.代码配置并行度
//工作进程Worker数量 Config config = new Config(); config.setNumWorkers(3); //注意此参数不能大于supervisor.slots.ports数量。 //执行器Executor数量 线程数量 TopologyBuilder builder = new TopologyBuilder(); builder.setSpout(id, spout, parallelism_hint); //设置Spout的Executor数量参数parallelism_hint builder.setBolt(id, bolt, parallelism_hint); //设置Bolt的Executor数量参数parallelism_hint //任务Task数量 指定任务数 会平均分配到执行器里 TopologyBuilder builder = new TopologyBuilder(); builder.setSpout(id, spout, parallelism_hint).setNumTasks(val); //设置Spout的Executor数量参数parallelism_hint,Task数量参数val builder.setBolt(id, bolt, parallelism_hint).setNumTasks(val); //设置Bolt的Executor数量参数parallelism_hint,Task数量参数val
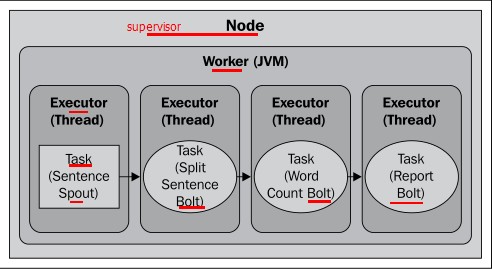
图解并行度:
2.1 默认1个worker,1个Executor,1个task
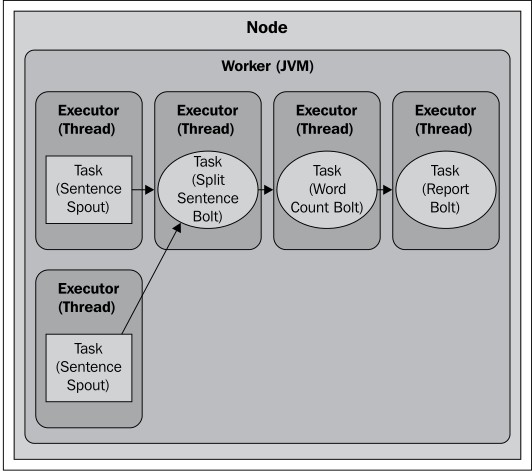
2.2 spout 设置并行度2
builder.setSpout(SENTENCE_SPOUT_ID, spout, 2);
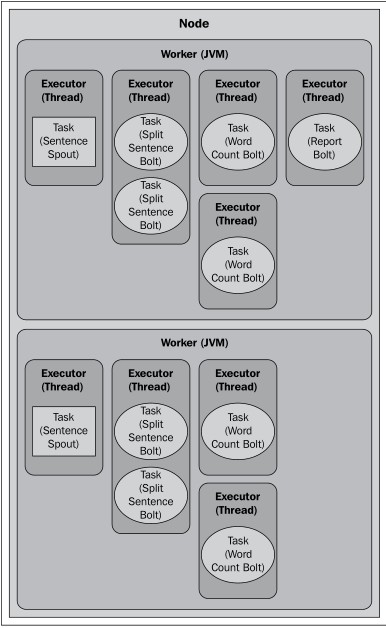
2.3 设置多worker 多并行度,多任务
#设置两个worker
Config config = new Config();
config.setNumWorkers(2);
#splitBolt并行度2,任务数4
builder.setBolt(SPLIT_BOLT_ID, splitBolt, 2).setNumTasks(4).shuffleGrouping(SENTENCE_SPOUT_ID);
#splitBolt并行度4
builder.setBolt(COUNT_BOLT_ID, countBolt, 4).fieldsGrouping(SPLIT_BOLT_ID, newFields("word"));
3.并行度再平衡
使用storm命令或者storm UI 操作
# 重新配置拓扑 # -w 10 设置10秒超时时间 # -n “myTopology” 拓扑使用5个Worker进程 # -e “blue-spout” Spout使用3个Executor # -e “yellow-blot” Bolt使用10个Executor storm rebalance myTopology -w 10 -n 5 -e blue-spout=3 -e yellow-blot=10
附示例:
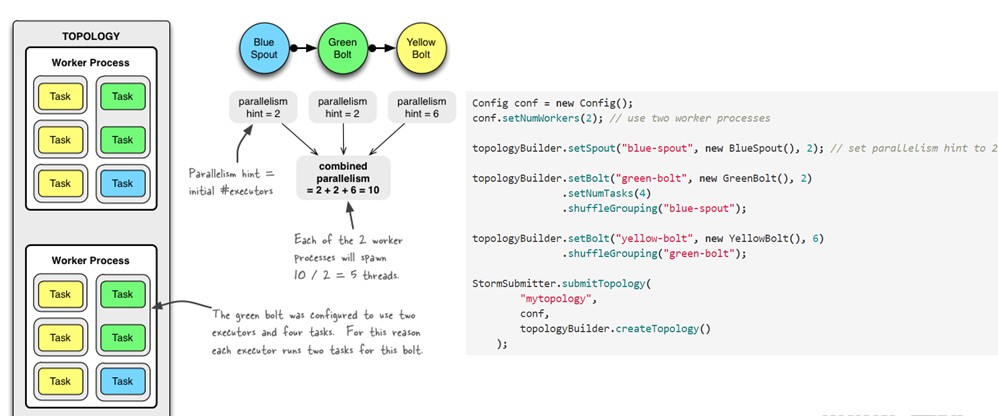
二、通信机制:
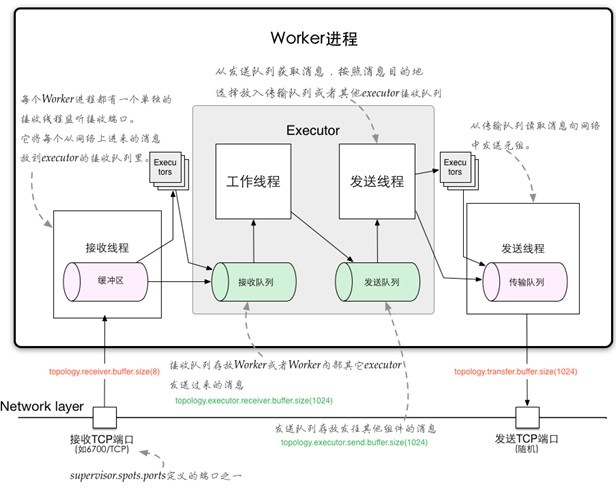
1、Worker进程间的数据通信
ZMQ
ZeroMQ 开源的消息传递框架,并不是一个MessageQueue
Netty
Netty是基于NIO的网络框架,更加高效。(之所以Storm 0.9版本之后使用Netty,是因为ZMQ的license和Storm的license不兼容。)
2、Worker内部的数据通信
Disruptor
实现了“队列”的功能。
可以理解为一种事件监听或者消息处理机制,即在队列当中一边由生产者放入消息数据,另一边消费者并行取出消息数据处理。
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号