中小型系统必要可行的性能测试实践--jmeter落地实践
为什么选择jmeter,业界用的广而且免费。本篇着重如何具体的开展性能测试:应该做哪些类型的性能测试?每种类型下采用什么类型线程组?每种类型监控数据的角度?在具体场景下的思路、具体配置?
一、性能场景的分析与创建
压测的场景来源于性能需求,性能需求侧重点不同,选择的测试场景和压测类型也不相同。对于旧系统来自于运维数据的分析,对于新系统来自于合理预估,按场景和规则预估,比如做OA,总用户10000个,测试打卡功能做并发,上午8:30-9:00之间。一般大部分的公司很难超过500。5000以上,1万,十万,百万一定要集群。我们这里立足于中小型系统实际,在没有明确压测指标要求的情况下,在特定的硬件配置下检查系统的最大承载并发量以及检验系统的稳定性如何为目的去做性能压测,我们这里选择常见的四种性能测试类型:基准测试、负载测试、压力测试、稳定性测试。
(1)按照业务流程角度:
单接口测试:对单个接口测试;比如:登录、查询商品、下单、支付四个接口
多接口的混合测试:多个接口的混合测试,比如:下单、支付属于一个业务事务,那么下单接口和支付接口就要一起测试,具体是通过jmeter的事务控制器来实现。
(2)按照用户量场景角度:用户量逐渐增多场景(梯度压测),通过不断地增加用户数(1个、10个、100个...),不断的消耗系统的资源,以达到系统的瓶颈。
一般来说都是上面两个组合起来使用,比如不管是单接口还是多接口,都要采用用户量逐渐增多的梯度压测来压测系统。
二、压测脚本的编写、调试、增强
1、如果没有场景,开发也没有给接口URL,可以使用jmeter代理录制脚本
(1)设置客户端的代理:控制面板-->Internet选项-->连接-->局域网设置-->勾上代理输入jmeter所在电脑的ip和8888端口。
(2)jmeter添加一个空线程组,下面要加一个HTTP cookie管理器;然后再加一个HTTP代理服务器

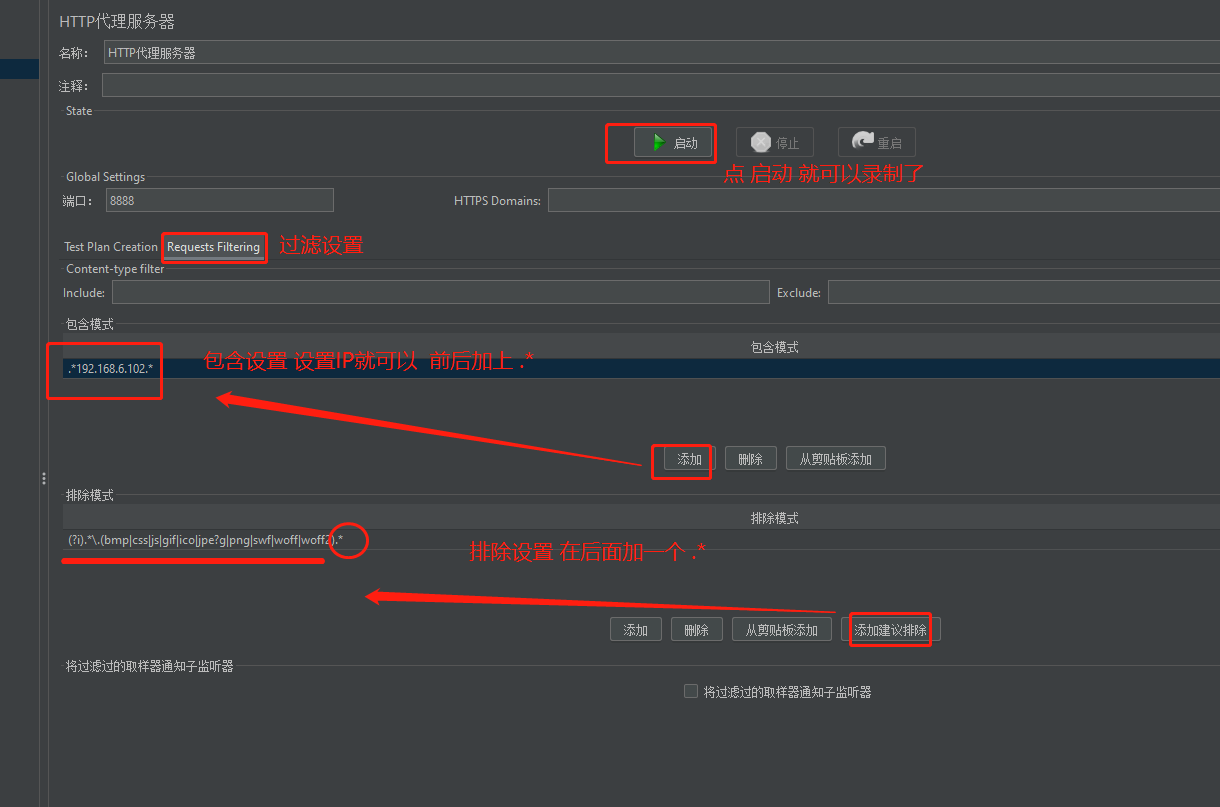
(3)录制脚本:在浏览器上操作业务,jmeter就会记录下所有的请求
参考:jmeter性能压测脚本生成及完善
2、特殊接口处理--登录、鉴权接口的处理
场景一:测试接口需要先登录鉴权,否则待测试的接口发出的请求无法被正常处理,因此要预先登录,jmeter通过setUp线程组做一个事前登录,然后将鉴权信息设置为全局变量,后面接口通过http信息头管理器提取鉴权值,进而保证接口鉴权成功
参考:JMeter之模拟用户登录后进行接口压测
场景二:采用多用户压测,每次使用不同的用户测试接口。
参考:jmeter多用户压测
场景三:绕过登录直接压测接口,不需要用户登录,直接复制现有系统一个鉴权信息即可。
参考:绕过登录直接压测接口
3、使用Jmeter监视器--查看结果树,调试接口,比如查看请求入参,响应结果,保证接口正确性。
三、脚本执行&指标监控
基于性能测试的四种类型来展开。注意:使用jmeter压测一般是无界面方式执行,用来减少施压机资源消耗,确保压测数据的可靠性。
1、基准测试
使用1个线程(虚拟用户)进行测试,使用 聚合报告 或者 grafana监控一段时间内平均吞吐量、平均响应时间两个指标,作为基准测试数据--TPS基数 和 平均响应时间基数。
具体jmeter配置:
| 线程组类型 | 普通线程组 |
| 线程数 | 1个 |
| 持续时长 | 120秒-300秒 |
2、负载测试
负载测试旨在通过不断增加系统并发量,直到系统到达性能瓶颈,以此推算出系统可承载用户数和吞吐量,找出系统或应用程序的上限。基于吞吐量、平均响应时间、成功率是确定负载性能重要指标:

随着并发数增加,吞吐量逐渐增加到顶峰,这是最好状态,但是此时系统承载的用户(线程)数是比较小的;并发数继续增加,吞吐量逐渐下降,响应时间持续增加,直到出现请求错误,此时系统就是处于高压状态,到达系统瓶颈、拐点;后续的并发数增加,吞吐量逐渐继续下降,响应时间和错误率会继续升高,这时系统不能正常运转了,后续的监控数据也就没有多大参考意义。
(1)进行性能测试,就是模拟高并发场景来测试系统,那如何模拟高并发呢?
高并发就是多线程,通过jmeter线程组设置不同的线程数来实现。性能测试里负载测试也叫容量测试,测试系统能够承载的最大用户数,而jmeter线程数=用户数。
(2)如何确定线程数量?
如果给出性能要求,比如抗住1000/s并发,然后通过基准测试数据得到平均响应时间是10ms,那么1个线程1秒可以发出的并发量:1*1000 / 10 = 100个请求,目标并发是1000/s,那么初始线程数 = 1000 / 100 = 10个线程,然后再按照梯度策略逐步增加;如果没有给出性能要求,线程数量一开始是没法确定的,策略就是逐步增加,采用梯度加压方式,jmeter有个梯度线程组(Stepping Thread Group,jmeter需要安装Custom Thread Groups插件)可以做这个事,不用纠结应该配置多少数量。
具体配置:注意步进线程数根据业务需要来确定;每个梯度持续时长最低120s,充分的时间才能暴露问题;总的线程数初始也不确定,先随便写一个,如果能撑住就继续加,反正不可能测一遍,系统的性能是慢慢探索出来的。
| 线程组类型 | 梯度线程组 |
| 策略 | 10个线程持续120s,20个线程持续120s,30个线程持续120s,... 100个线程持续120s,然后每5s关闭10个 |

(3)通过promtetheus+grafana+influxDB监测数据确定系统负载
主要监控吞吐量、错误数、活跃线程数、响应时间四个指标数据,直到系统开始出错,出错了就说明系统扛不住了,不能正常运行了,也就是系统处于高压状态、崩溃的边缘,然后就分析这个时间点的其他指标数据,通过数据关系得出性能数据。
举例:

<1>先来看错误数仪表盘,显示在2022-09-16 21:06:25时间点系统出错了;
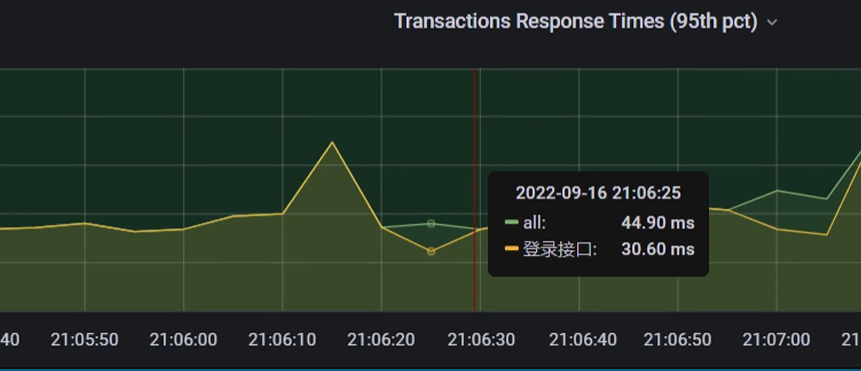
<2>然后看响应时间仪表盘,在2022-09-16 21:06:25时间点响应时间约30ms,那么1个线程1秒内可以发出 1000 / 30 = 33 个请求;
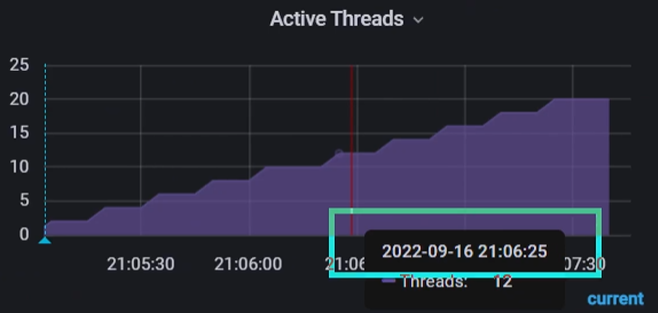
<3>然后看活跃线程仪表盘,在2022-09-16 21:06:25时间点活跃线程数12个,那么12个线程1秒内总共可以发出 12 * 33 = 396 个请求;
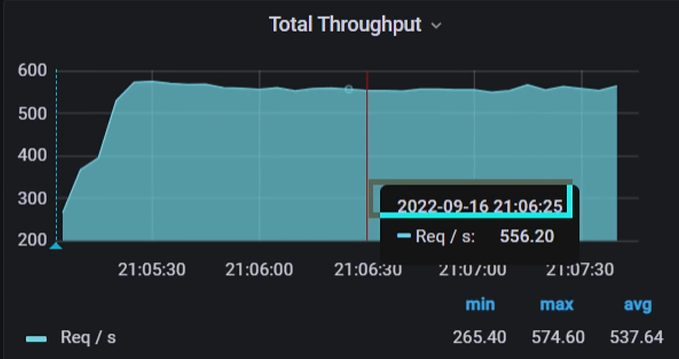
<4>然后看吞吐量仪表盘,整体逐渐增加最后趋于平稳,在2022-09-16 21:05:25到达最大值574.6/sec,在2022-09-16 21:06:25时间点556.2/s,平均值在537.64/s;
注意:grafana监控的吞吐量和计算的tps不一致,为什么?这是采样的频率有关,仪表盘上的吞吐量需要按照采样频率修正一下
参考:
综上数据分析,系统在最好状态下吞吐量574.6/s,在高压状态下吞吐量为396/s,最大承载12个用户,响应时间33.60ms。
参考:
(4)根据聚合报告推测负载
如果没有部署promtetheus+grafana监控体系,可以仅使用聚合报告数据,结合两个公式【TPS倍数 = TPS(吞吐量)/ TPS基数,RT倍数 = 平均响应时间(毫秒) / 平均响应时间基数】来做对比分析。
举例:
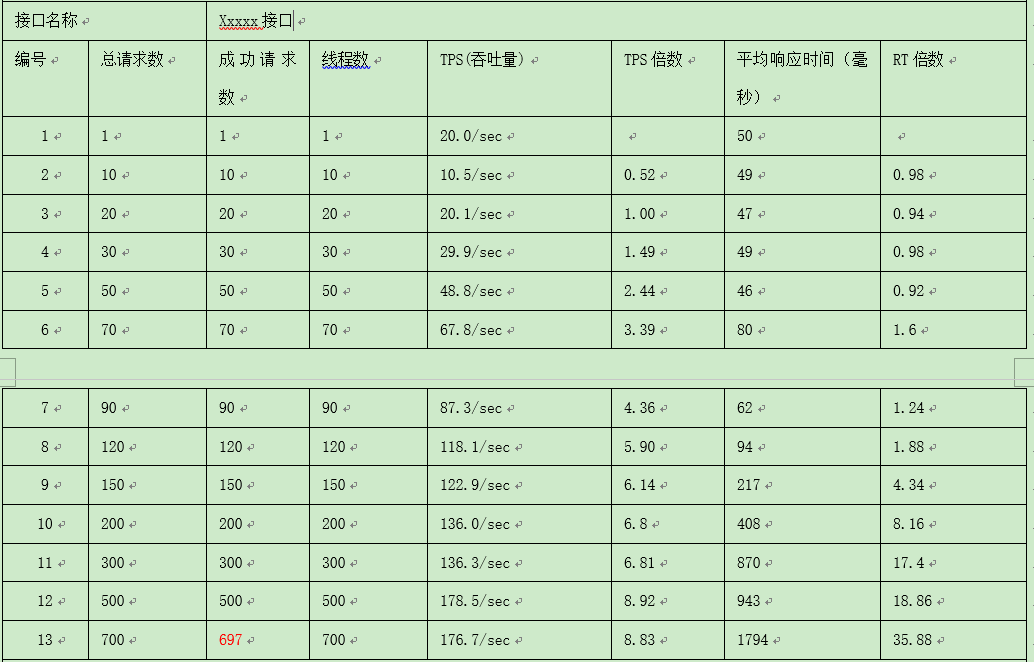
通过上述聚合报告数据可以看出:
初始时,当并发量成倍增加时,吞吐量也随着成倍增加;当并发量到达150时,吞吐量不再成倍增长,出现疲软;当并发量持续增加时,吞吐量缓慢增加;当并发量达到700时,请求开始出现异常,平均请求时间约为1.8秒;综上数据,在目前的资源配置下,xxxx接口最大吞吐量178.5/sec,最大承载用户数500个,平均响应时间943ms,此时系统性能到了瓶颈点。
3、压力测试
负载测试是为了探索系统到达性能瓶颈时的性能指标,而压力测试检测系统在极重的负载条件下出现的问题,作为后续优化的目标。
3.1 压力测试可细分为并发测试和大数据量测试:
(1)并发测试:通过负载测试已经得到系统最大负载指标-最大线程数N,压力测试就使用N或者N+10,N+20...等高于最大值程数来压测系统,当测试多用户并发访问同一个应用、模块、数据时是否产生隐藏的并发问题。并发测试不是为了获取系统的性能指标,而是为了发现并发引发的问题,如:线程锁、内存泄漏、资源争用等。
(2)大数据量测试:包含独立数据量测试,主要是针对某些系统存储、传输、查询等业务进行大数据量测试,如测试系统存储能力,IO传输速率、读取速率、慢查询等
负载测试只关注什么时候到达性能瓶颈以及到达性能瓶颈时的线程数、响应时间、吞吐量、错误率指标,没有关注服务器资源和程序资源,但是压力测试的时候就需要关注了,只有通过这些数据才能确定是什么原因导致系统到达性能瓶颈。
3.2 具体有两个角度测试
(1)尖峰压测:通过阶梯线程组构造一个线程数尖峰,比如10 20 10,来观察资源利用情况;
(2)浪涌压测:通过浪涌线程组(Ultimate Thread Group)构造一波波的线程高峰浪潮,比如10 0 10 0 10 0,来观察资源利用情况;
4、稳定性测试
使用普通线程组,通常采用系统稳定运行情况下的并发用户数或者日常运行用户数,持续运行较长一段时间(比如1*24、3*24、7*24),保证达到系统疲劳强度需求的业务量范围,确定系统在长时间工作强度时的性能问题。
稳定性测试可以发现如下问题:
(1)系统变慢:刚开始还好好的,时间久了,系统变得越来越慢;
(2)系统遇到功能问题:刚开始,功能还正常,时间久了,同样的操作就出错了;
(3)系统完全崩溃:时间久了,突然宕机了;
参考:稳定性测试
四、瓶颈定位
在负载测试、压力测试阶段,可以拿到系统到达性能瓶颈时的资源使用监控数据,从而分析是哪一个资源导致系统到达性能瓶颈。
(1)首先看服务器资源,如果服务器资源利用率很高,说明CPU、内存、带宽、磁盘已经不够用了;
(2)如果服务器资源利用率不是很高,还有较多的份额,但是也到达系统性能瓶颈,这就说明是服务器资源以外的因素导致的,那就是程序,比如java程序查看JVM,mysql、nginx、redis、MQ等是否存在限制,借助yourKit、Arthas等工具深入分析程序中资源利用情况,线程、堆内存、连接数、缓存、索引、超时时间等等,导致性能问题的原因各种各样,没有规律,这个地方是难点,需要具备丰富的技术积累(广度+深度)。
五、性能调优
根据四中分析的原因,自然而然的就会给出对应的调优措施。
比如:
服务器资源CPU不够用了,那就增加CPU;
JVM的FullGC频繁就调整GC参数 或 优化代码;
MYSQL里监测到慢查询就优化SQL或者加索引;
...
六、输出测试报告
文档编写,主要是记录三、四、五中监控数据和定位分析过程,可以参考模板。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号