【机器学习算法】逻辑回归
环境
spark-1.6
python3.5
一、逻辑回归
逻辑回归又叫logistic回归分析,是一种广义的线性回归分析模型。线性回归要求因变量必须是连续性的数据变量,逻辑回归要求因变量必须是分类变量,可以是二分类或者多分类(多分类都可以归结到二分类问题),逻辑回归的输出是0~1之间的概率。比如要分析年龄,性别,身高,饮食习惯对于体重的影响,如果体重是实际的重量,那么就要使用线性回归。如果将体重分类,分成了高,中,低三类,就要使用逻辑回归进行分类。
(1)逻辑回归公式: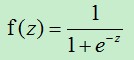 , 其中,e是自然对数,无限不循环小数,
, 其中,e是自然对数,无限不循环小数, 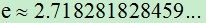 ,
,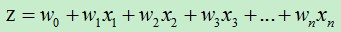
逻辑回归公式又叫逻辑函数(Logistic function)或者S形函数(Sigmoid function)。逻辑回归公式的图像如下:
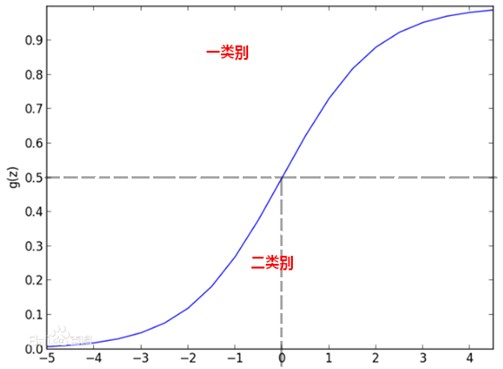
即当z=0时,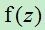 =0.5,当z
=0.5,当z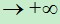 时, 趋近于1,当
时, 趋近于1,当 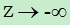 时, 趋近于0。
时, 趋近于0。
逻辑回归的输出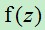 就是位于0~1之间的概率,假设现在判断病人是否生病,得到的z=2对应的 =0.7,我们可以归结为生病,如果z=-2对应的
就是位于0~1之间的概率,假设现在判断病人是否生病,得到的z=2对应的 =0.7,我们可以归结为生病,如果z=-2对应的 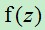 =0.1我们就可以认为不生病。当z=0时,
=0.1我们就可以认为不生病。当z=0时, =0.5是决策的边界。
=0.5是决策的边界。
(2)假设 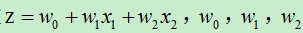 都大于零,那么当z=0时, =0.5。也就是
都大于零,那么当z=0时, =0.5。也就是 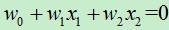 时, =0.5,当z=0时使用图像来表达两个自变量的关系为:
时, =0.5,当z=0时使用图像来表达两个自变量的关系为:
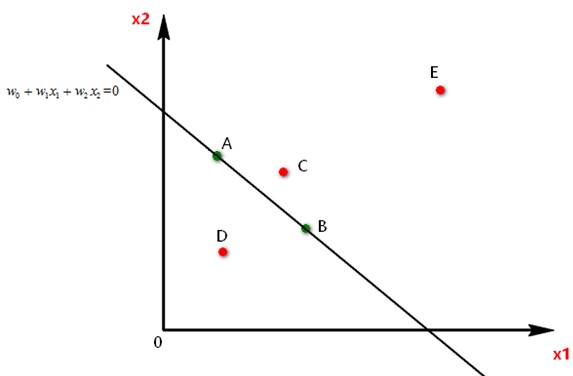
图中A、B、C、D、E点都表示有 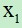 ,
, 两个维度的数据,现要使用逻辑回归对五个点分成两类:I和II类:
两个维度的数据,现要使用逻辑回归对五个点分成两类:I和II类:
A点和B点都在直线上,对应的z值是0,那么逻辑回归结果 =0.5,将A,B两点划分为I类和II类都可以,假设我们规定当z>=0属于I类,z<0属于II类,那么A,B属于I类。
C点位于直线的上方,对应的z值要大于零,反映到S形函数上对应的 >0.5属于I类,同理,E也属于I类,D点属于II类。
图中E点的z值远大于C点的z值,反映到S形函数中,E点属于I类的概率比C点属于I类的概率要大的多。
训练逻辑回归模型,在这里就是训练出一条直线将两个类别的点隔开。如果维度是3,那么训练逻辑回归模型就是训练一个平面将两个类别的点隔开。如果维度大于3,那么训练逻辑回归模型就是训练一个超平面将两个类别的点隔开。
二、案例:音乐分类(使用python的sklearn包)
1、概念
时域分析:
对一个信号来说,信号强度随时间的变化的规律就是时域特性,例如一个信号的时域波形可以表达信号随着时间的变化。
频域分析:
对一个信号来说,在对其进行分析时,分析信号和频率有关的部分,而不是和时间相关的部分,和时域相对。也就是信号是由哪些单一频率的的信号合成的就是频域特性。频域中有一个重要的规则是正弦波是频域中唯一存在的波。即正弦波是对频域的描述,因为时域中的任何波形都可用正弦波合成。
傅里叶变换:
一般来说,时域的表示较为形象直观,频域分析则简练。傅里叶变换是贯穿时域和频域的方法之一,傅里叶变换就是将难以处理的时域信号转换成了易于分析的频域信号。
傅里叶原理:任何连续测量的时序信号,都可以表示为不同频率的正弦波信号的无限叠加。

2、音乐分类的步骤:
(1)通过傅里叶变换将不同7类里面所有原始wav格式音乐文件转换为特征,并取前1000个特征,存入文件以便后续训练使用
(2)读入以上7类特征向量数据作为训练集
(3)使用sklearn包中LogisticRegression的fit方法计算出分类模型
(4)读入黑豹乐队歌曲”无地自容”并进行傅里叶变换同样取前1000维作为特征向量
(5)调用模型的predict方法对音乐进行分类,结果分为rock即摇滚类
首先来看一下单个音乐文件的频谱图:
# -*- coding:utf-8 -*- from scipy import fft from scipy.io import wavfile from matplotlib.pyplot import specgram import matplotlib.pyplot as plt # 可以先把一个wav文件读入python,然后绘制它的频谱图(spectrogram)来看看是什么样的 #画框设置 #figsize=(10, 4)宽度和高度的英寸 # dpi=80 分辨率 # plt.figure(figsize=(10, 4),dpi=80) # # (sample_rate, X) = wavfile.read("E:/genres/metal/converted/metal.00065.au.wav") # print sample_rate, X.shape # specgram(X, Fs=sample_rate, xextent=(0,30)) # plt.xlabel("time") # plt.ylabel("frequency") ##线的形状和颜色 # plt.grid(True, linestyle='-', color='0.75') ##tight紧凑一点 # plt.savefig("E:/metal.00065.au.wav5.png", bbox_inches="tight") # 当然,我们也可以把每一种的音乐都抽一些出来打印频谱图以便比较,如下图: # def plotSpec(g,n): # sample_rate, X = wavfile.read("E:/genres/"+g+"/converted/"+g+"."+n+".au.wav") # specgram(X, Fs=sample_rate, xextent=(0,30)) # plt.title(g+"_"+n[-1]) # # plt.figure(num=None, figsize=(18, 9), dpi=80, facecolor='w', edgecolor='k') # plt.subplot(6,3,1);plotSpec("classical","00001");plt.subplot(6,3,2);plotSpec("classical","00002") # plt.subplot(6,3,3);plotSpec("classical","00003");plt.subplot(6,3,4);plotSpec("jazz","00001") # plt.subplot(6,3,5);plotSpec("jazz","00002");plt.subplot(6,3,6);plotSpec("jazz","00003") # plt.subplot(6,3,7);plotSpec("country","00001");plt.subplot(6,3,8);plotSpec("country","00002") # plt.subplot(6,3,9);plotSpec("country","00003");plt.subplot(6,3,10);plotSpec("pop","00001") # plt.subplot(6,3,11);plotSpec("pop","00002");plt.subplot(6,3,12);plotSpec("pop","00003") # plt.subplot(6,3,13);plotSpec("rock","00001");plt.subplot(6,3,14);plotSpec("rock","00002") # plt.subplot(6,3,15);plotSpec("rock","00003");plt.subplot(6,3,16);plotSpec("metal","00001") # plt.subplot(6,3,17);plotSpec("metal","00002");plt.subplot(6,3,18);plotSpec("metal","00003") # plt.tight_layout(pad=0.4, w_pad=0, h_pad=1.0) # plt.savefig("D:/compare.au.wav.png", bbox_inches="tight") # 对单首音乐进行傅里叶变换 #画框设置figsize=(9, 6)宽度和高度的英寸,dpi=80是分辨率 plt.figure(figsize=(9, 6), dpi=80) #sample_rate代表每秒样本的采样率,X代表读取文件的所有信息 音轨信息,这里全是单音轨数据 是个数组【双音轨是个二维数组,左声道和右声道】 #采样率:每秒从连续信号中提取并组成离散信号的采样个数,它用赫兹(Hz)来表示 sample_rate, X = wavfile.read("../../data/genres/jazz/converted/jazz.00002.au.wav") print(sample_rate,X,type(X),len(X)) plt.subplot(211) #画wav文件时频分析的函数 specgram(X, Fs=sample_rate) plt.xlabel("time") plt.ylabel("frequency") plt.subplot(212) #fft 快速傅里叶变换 fft(X)得到振幅 即当前采样下频率的振幅 fft_X = abs(fft(X)) print("fft_x",fft_X,len(fft_X)) #画频域分析图 注意Python3里要求把NFFT、noverlap、Fs默认参数写上 可能会报错 python2不用 specgram(fft_X,NFFT=256,noverlap=128,Fs=2) plt.xlabel("frequency") plt.ylabel("amplitude") plt.savefig("../../data/jazz.00000.au.wav.fft.png") plt.show()
结果:
# 22050 [ 110 161 124 ... 1865 1683 1248] <class 'numpy.ndarray'> 661794 # fft_x [40496. 42167.35454671 31547.4214156 ... 45633.12023717 31547.4214156 42167.35454671] 661794

训练模型:
# -*- coding:utf-8 -*- """ 使用logistic regression处理音乐数据,音乐数据训练样本的获得和使用快速傅里叶变换(FFT)预处理的方法需要事先准备好 1. 把训练集扩大到每类100个首歌,类别仍然是六类:jazz,classical,country, pop, rock, metal 2. 同时使用logistic回归训练模型 3. 引入一些评价的标准来比较Logistic测试集上的表现 """ from scipy import fft from scipy.io import wavfile import numpy as np # 准备音乐数据 def create_fft(g,n): rad="../../data/genres/"+g+"/converted/"+g+"."+str(n).zfill(5)+".au.wav" #sample_rate 音频的采样率,X代表读取文件的所有信息 (sample_rate, X) = wavfile.read(rad) print(sample_rate) #取1000个频率特征 也就是振幅 fft_features = abs(fft(X)[:1000]) #zfill(5) 字符串不足5位,前面补0 sad="../../data/trainset/"+g+"."+str(n).zfill(5)+ ".fft" np.save(sad, fft_features) #-------create fft 构建训练集-------------- genre_list = ["classical", "jazz", "country", "pop", "rock", "metal","hiphop"] for g in genre_list: for n in range(100): create_fft(g,n) print('running...') print('finished')
使用训练特征对音乐文件分类:
# -*- coding:utf-8 -*- from scipy import fft from scipy.io import wavfile from sklearn.linear_model import LogisticRegression import numpy as np #========================================================================================= # 加载训练集数据,分割训练集以及测试集,进行分类器的训练 # 构造训练集!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! #-------read fft-------------- genre_list = ["classical", "jazz", "country", "pop", "rock", "metal","hiphop"] X=[] Y=[] for g in genre_list: for n in range(100): rad="../../data/trainset/"+g+"."+str(n).zfill(5)+ ".fft"+".npy" #加载文件 fft_features = np.load(rad) X.append(fft_features) #genre_list.index(g) 返回匹配上类别的索引号 Y.append(genre_list.index(g)) #构建的训练集 X=np.array(X) #构建的训练集对应的类别 Y=np.array(Y) # 接下来,我们使用sklearn,来构造和训练我们的两种分类器 #------train logistic classifier-------------- #创建LogisticRegression 要制定solver 否则会告警:FutureWarning: Default solver will be changed to 'lbfgs' in 0.22. Specify a solver to model = LogisticRegression(solver='liblinear',multi_class='ovr',max_iter=1000) #需要numpy.array类型参数 model.fit(X, Y) print('Starting read wavfile...') #prepare test data------------------- # sample_rate, test = wavfile.read("i:/classical.00007.au.wav") sample_rate, test = wavfile.read("../../data/heibao-wudizirong-remix.wav") print(sample_rate,test) testdata_fft_features = abs(fft(test))[:1000] #model.predict(testdata_fft_features) 预测为一个数组,array([类别]) #testdata_fft_features如果不使用reshape(1, -1)处理一下 可能报错ValueError: Expected 2D array, got 1D array instead: #新版本sklearn中所有东西都必须是一个2D矩阵,即使是一个简单的column或row) 使用array.reshape(-1, 1)重新调整你的数据 testdata=testdata_fft_features.reshape(1, -1) # print(testdata) type_index = model.predict(testdata)[0] print(type_index) print(genre_list[type_index])
结果:
Starting read wavfile... 44100 [0 0 0 ... 2 2 0] 0 classical
三、案例:道路拥堵预测(使用spark的MLLIB)
1、道路拥堵训练集
每条道路的拥堵情况不仅和当前道路前一个时间点拥堵情况有关系,还和与这条道路临近的其他道路的拥堵情况有关。甚至还和昨天当前时间点当前道路是否拥堵有关联。我们可以根据这个规律,构建训练集,预测一条道路拥堵情况。
假设现在要训练一个模型:使用某条道路最近三分钟拥堵的情况,预测该条道路下一分钟的拥堵情况。如何构建训练集?
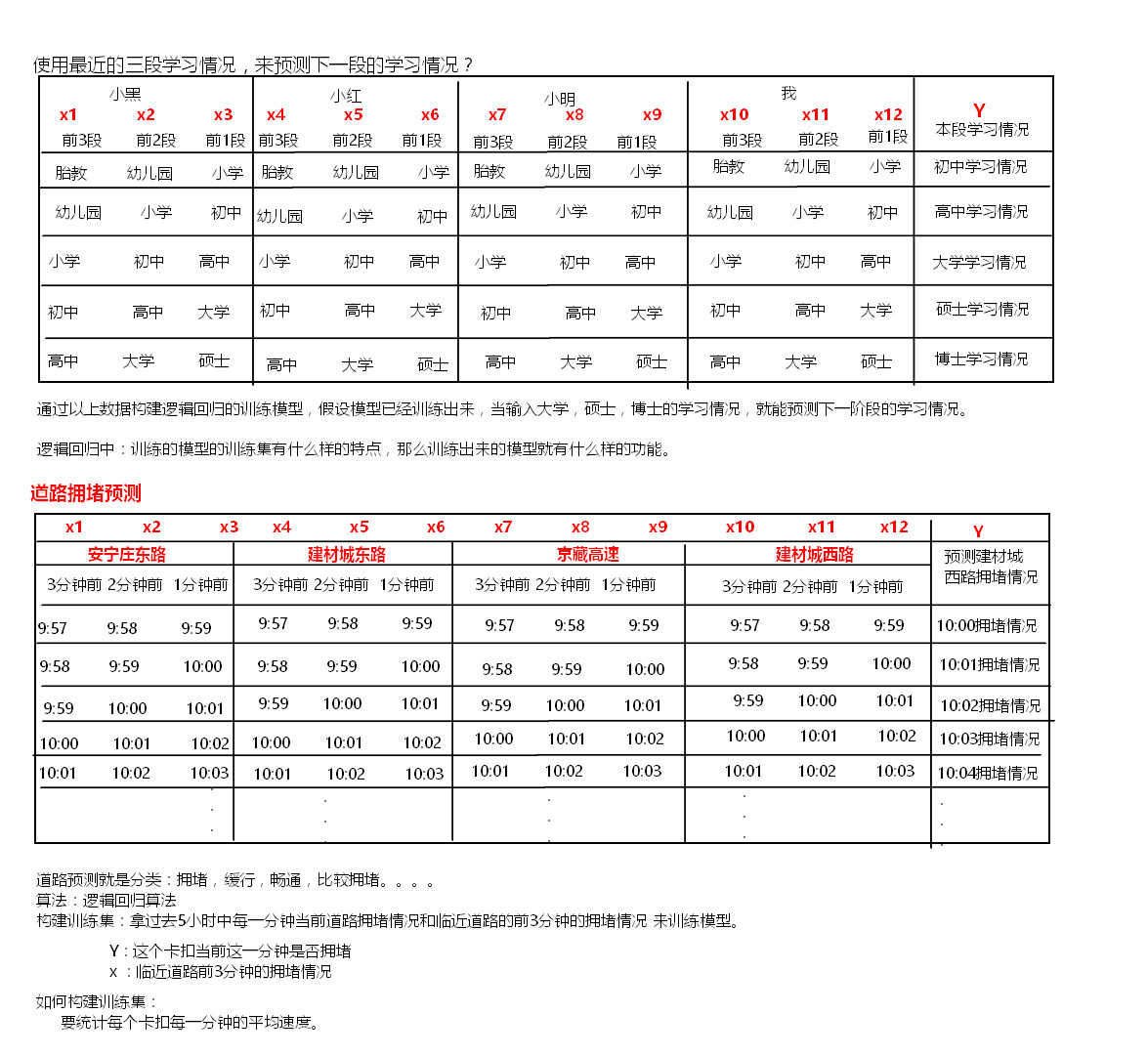
特点:构建的训练集有什么样的特点,依靠训练集训练的模型就具备什么样的功能。
2、步骤:
(1)计算道路每分钟经过的车辆数和速度总和,可以得到道路实时拥堵情况
数据收集:每个路口的摄像头获取数据,将数据发送到kafka里,然后使用sparkstreaming接收并计算每分钟数据,将数据保存到Redis里
发送数据:
package com.ic.traffic.streaming import java.sql.Timestamp import java.util.Properties import kafka.javaapi.producer.Producer import kafka.producer.{KeyedMessage, ProducerConfig} import org.apache.spark.{SparkContext, SparkConf} import org.codehaus.jettison.json.JSONObject import scala.util.Random //向kafka car_events中生产数据 object KafkaEventProducer { def main(args: Array[String]): Unit = { val topic = "car_events" val brokers = "node1:9092,node2:9092,node3:9092" val props = new Properties() props.put("metadata.broker.list", brokers) props.put("serializer.class", "kafka.serializer.StringEncoder") val kafkaConfig = new ProducerConfig(props) val producer = new Producer[String, String](kafkaConfig) val sparkConf = new SparkConf().setAppName("traffic data").setMaster("local[4]") val sc = new SparkContext(sparkConf) val filePath = "./data/2014082013_all_column_test.txt" val records = sc.textFile(filePath) .filter(!_.startsWith(";")) .map(_.split(",")).collect() for (i <- 1 to 100) { for (record <- records) { // prepare event data val event = new JSONObject() event.put("camera_id", record(0)) .put("car_id", record(2)) .put("event_time", record(4)) .put("speed", record(6)) .put("road_id", record(13)) // produce event message producer.send(new KeyedMessage[String, String](topic,event.toString)) println("Message sent: " + event) Thread.sleep(200) } } sc.stop } }
接收、汇总、保存数据:
package com.ic.traffic.streaming import java.text.SimpleDateFormat import java.util.Calendar import kafka.serializer.StringDecoder import net.sf.json.JSONObject import org.apache.spark.SparkConf import org.apache.spark.streaming._ import org.apache.spark.streaming.dstream.DStream import org.apache.spark.streaming.kafka._ import org.apache.spark.streaming.dstream.InputDStream /** * 将每个卡扣的总速度_车辆数 存入redis中 * 【yyyyMMdd_Monitor_id,HHmm,SpeedTotal_CarCount】 */ object CarEventCountAnalytics { def main(args: Array[String]): Unit = { // Create a StreamingContext with the given master URL val conf = new SparkConf().setAppName("CarEventCountAnalytics") if (args.length == 0) { conf.setMaster("local[*]") } val ssc = new StreamingContext(conf, Seconds(5)) // ssc.checkpoint(".") // Kafka configurations val topics = Set("car_events") val brokers = "node1:9092,node2:9092,node3:9092" val kafkaParams = Map[String, String]( "metadata.broker.list" -> brokers, "serializer.class" -> "kafka.serializer.StringEncoder") val dbIndex = 1 // Create a direct stream val kafkaStream: InputDStream[(String, String)] = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics) val events: DStream[JSONObject] = kafkaStream.map(line => { //JSONObject.fromObject 将string 转换成jsonObject val data = JSONObject.fromObject(line._2) println(data) data }) /** * carSpeed K:monitor_id * V:(speedCount,carCount) */ val carSpeed = events.map(jb => (jb.getString("camera_id"),jb.getInt("speed"))) .mapValues((speed:Int)=>(speed,1)) //(camera_id, (speed, 1) ) => (camera_id , (total_speed , total_count)) .reduceByKeyAndWindow((a:Tuple2[Int,Int], b:Tuple2[Int,Int]) => {(a._1 + b._1, a._2 + b._2)},Seconds(60),Seconds(10)) // .reduceByKeyAndWindow((a:Tuple2[Int,Int], b:Tuple2[Int,Int]) => {(a._1 + b._1, a._2 + b._2)},(a:Tuple2[Int,Int], b:Tuple2[Int,Int]) => {(a._1 - b._1, a._2 - b._2)},Seconds(20),Seconds(10)) carSpeed.foreachRDD(rdd => { rdd.foreachPartition(partitionOfRecords => { val jedis = RedisClient.pool.getResource partitionOfRecords.foreach(pair => { val camera_id = pair._1 val speedTotal = pair._2._1 val CarCount = pair._2._2 val now = Calendar.getInstance().getTime() // create the date/time formatters val minuteFormat = new SimpleDateFormat("HHmm") val dayFormat = new SimpleDateFormat("yyyyMMdd") val time = minuteFormat.format(now) val day = dayFormat.format(now) if(CarCount!=0){ jedis.select(dbIndex) jedis.hset(day + "_" + camera_id, time , speedTotal + "_" + CarCount) } }) RedisClient.pool.returnResource(jedis) }) }) println("xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx") ssc.start() ssc.awaitTermination() } }
(2)预测道路的拥堵情况受当前道路附近道路拥堵的情况,受这几个道路过去几分钟道路拥堵的情况。预测道路拥堵情况可以根据附近每条道路和当前道路前3分钟道路拥堵的情况来预测。用附近每条道路和当前道路前3分钟道路的拥堵情况来当做维度。统计这些道路过去5个小时内每分钟的前3分钟拥堵情况构建数据集。
(3)训练逻辑回归模型
(4)保存模型
package com.ic.traffic.streaming import java.text.SimpleDateFormat import java.util import java.util.{Date} import org.apache.spark.mllib.classification.LogisticRegressionWithLBFGS import org.apache.spark.mllib.evaluation.MulticlassMetrics import org.apache.spark.{SparkContext, SparkConf} import org.apache.spark.mllib.linalg.Vectors import org.apache.spark.mllib.regression.LabeledPoint import org.apache.spark.mllib.util.MLUtils import scala.collection.mutable.ArrayBuffer import scala.Array import scala.collection.mutable.ArrayBuffer import org.apache.spark.mllib.classification.LogisticRegressionModel /** * 训练模型 */ object TrainLRwithLBFGS { val sparkConf = new SparkConf().setAppName("train traffic model").setMaster("local[*]") val sc = new SparkContext(sparkConf) // create the date/time formatters val dayFormat = new SimpleDateFormat("yyyyMMdd") val minuteFormat = new SimpleDateFormat("HHmm") def main(args: Array[String]) { // fetch data from redis val jedis = RedisClient.pool.getResource jedis.select(1) // find relative road monitors for specified road // val camera_ids = List("310999003001","310999003102","310999000106","310999000205","310999007204") val camera_ids = List("310999003001","310999003102") val camera_relations:Map[String,Array[String]] = Map[String,Array[String]]( "310999003001" -> Array("310999003001","310999003102","310999000106","310999000205","310999007204"), "310999003102" -> Array("310999003001","310999003102","310999000106","310999000205","310999007204") ) val temp = camera_ids.map({ camera_id => val hours = 5 val nowtimelong = System.currentTimeMillis(); val now = new Date(nowtimelong) val day = dayFormat.format(now)//yyyyMMdd val array = camera_relations.get(camera_id).get /** * relations中存储了每一个卡扣在day这一天每一分钟的平均速度 */ val relations = array.map({ camera_id => // println(camera_id) // fetch records of one camera for three hours ago val minute_speed_car_map = jedis.hgetAll(day + "_'" + camera_id+"'") (camera_id, minute_speed_car_map) }) // relations.foreach(println) // organize above records per minute to train data set format (MLUtils.loadLibSVMFile) val dataSet = ArrayBuffer[LabeledPoint]() // start begin at index 3 //Range 从300到1 递减 不包含0 for(i <- Range(60*hours,0,-1)){ val features = ArrayBuffer[Double]() val labels = ArrayBuffer[Double]() // get current minute and recent two minutes for(index <- 0 to 2){ //当前时刻过去的时间那一分钟 val tempOne = nowtimelong - 60 * 1000 * (i-index) val d = new Date(tempOne) val tempMinute = minuteFormat.format(d)//HHmm //下一分钟 val tempNext = tempOne - 60 * 1000 * (-1) val dNext = new Date(tempNext) val tempMinuteNext = minuteFormat.format(dNext)//HHmm for((k,v) <- relations){ val map = v //map -- k:HHmm v:Speed if(index == 2 && k == camera_id){ if (map.containsKey(tempMinuteNext)) { val info = map.get(tempMinuteNext).split("_") val f = info(0).toFloat / info(1).toFloat labels += f } } if (map.containsKey(tempMinute)){ val info = map.get(tempMinute).split("_") val f = info(0).toFloat / info(1).toFloat features += f } else{ features += -1.0 } } } if(labels.toArray.length == 1 ){ //array.head 返回数组第一个元素 val label = (labels.toArray).head val record = LabeledPoint(if ((label.toInt/10)<10) (label.toInt/10) else 10.0, Vectors.dense(features.toArray)) dataSet += record } } // dataSet.foreach(println) // println(dataSet.length) val data = sc.parallelize(dataSet) // Split data into training (80%) and test (20%). //将data这个RDD随机分成 8:2两个RDD val splits = data.randomSplit(Array(0.8, 0.2)) //构建训练集 val training = splits(0) /** * 测试集的重要性: * 测试模型的准确度,防止模型出现过拟合的问题 */ val test = splits(1) if(!data.isEmpty()){ // 训练逻辑回归模型 val model = new LogisticRegressionWithLBFGS() .setNumClasses(11) .setIntercept(true) .run(training) // 测试集测试模型 val predictionAndLabels = test.map { case LabeledPoint(label, features) => val prediction = model.predict(features) (prediction, label) } predictionAndLabels.foreach(x=> println("预测类别:"+x._1+",真实类别:"+x._2)) // Get evaluation metrics. 得到评价指标 val metrics: MulticlassMetrics = new MulticlassMetrics(predictionAndLabels) val precision = metrics.precision// 准确率 println("Precision = " + precision) if(precision > 0.8){ val path = "hdfs://node1:9000/model/model_"+camera_id+"_"+nowtimelong model.save(sc, path) println("saved model to "+ path) jedis.hset("model", camera_id , path) } } }) RedisClient.pool.returnResource(jedis) } }
(5)使用模型预测道路的拥堵情况
package com.ic.traffic.streaming import java.text.SimpleDateFormat import java.util.Date import org.apache.spark.mllib.classification.{ LogisticRegressionModel, LogisticRegressionWithLBFGS } import org.apache.spark.mllib.evaluation.MulticlassMetrics import org.apache.spark.mllib.linalg.Vectors import org.apache.spark.mllib.regression.LabeledPoint import org.apache.spark.{ SparkConf, SparkContext } import scala.collection.mutable.ArrayBuffer object PredictLRwithLBFGS { val sparkConf = new SparkConf().setAppName("predict traffic").setMaster("local[4]") val sc = new SparkContext(sparkConf) // create the date/time formatters val dayFormat = new SimpleDateFormat("yyyyMMdd") val minuteFormat = new SimpleDateFormat("HHmm") val sdf = new SimpleDateFormat("yyyy-MM-dd_HH:mm:ss") def main(args: Array[String]) { val input = "2019-05-20_17:25:00" val date = sdf.parse(input) val inputTimeLong = date.getTime() // val inputTime = new Date(inputTimeLong) val day = dayFormat.format(date)//yyyyMMdd // fetch data from redis val jedis = RedisClient.pool.getResource jedis.select(1) // find relative road monitors for specified road // val camera_ids = List("310999003001","310999003102","310999000106","310999000205","310999007204") val camera_ids = List("310999003001", "310999003102") val camera_relations: Map[String, Array[String]] = Map[String, Array[String]]( "310999003001" -> Array("310999003001", "310999003102", "310999000106", "310999000205", "310999007204"), "310999003102" -> Array("310999003001", "310999003102", "310999000106", "310999000205", "310999007204")) val temp = camera_ids.map({ camera_id => val list = camera_relations.get(camera_id).get val relations = list.map({ camera_id => // fetch records of one camera for three hours ago (camera_id, jedis.hgetAll(day + "_'" + camera_id + "'")) }) // relations.foreach(println) // organize above records per minute to train data set format (MLUtils.loadLibSVMFile) val aaa = ArrayBuffer[Double]() // get current minute and recent two minutes for (index <- 3 to (1,-1)) { //拿到过去 一分钟,两分钟,过去三分钟的时间戳 val tempOne = inputTimeLong - 60 * 1000 * index val currentOneTime = new Date(tempOne) //获取输入时间的 "HHmm" val tempMinute = minuteFormat.format(currentOneTime) println("inputtime ====="+currentOneTime) for ((k, v) <- relations) { // k->camera_id ; v->speed val map = v if (map.containsKey(tempMinute)) { val info = map.get(tempMinute).split("_") val f = info(0).toFloat / info(1).toFloat aaa += f } else { aaa += -1.0 } } } // Run training algorithm to build the model val path = jedis.hget("model", camera_id) if(path!=null){ val model = LogisticRegressionModel.load(sc, path) // Compute raw scores on the test set. val prediction = model.predict(Vectors.dense(aaa.toArray)) println(input + "\t" + camera_id + "\t" + prediction + "\t") // jedis.hset(input, camera_id, prediction.toString) } }) RedisClient.pool.returnResource(jedis) } }
注意:提高模型的分类数,会提高模型的抗干扰能力。比如道路拥堵情况就分为两类:“畅通”、“拥堵”,如果模型针对一条本来属于“畅通”分类的数据预测错了,那么预测结果只能就是“拥堵”,那么就发生了质的改变。如果我们将道路拥堵情况分为四类:“畅通”,“比较畅通”,“比较拥堵”,“拥堵”。如果模型针对一条本来数据“畅通”分类的数据预测错了,那么预测结果错的情况下就不是只有“拥堵”这个情况,有可能是其他三类的一种,也有一定的概率预测分类为“比较畅通”,那么就相当于提高了模型的抗干扰能力。
关于label和feature:
label是分类,你要预测的东西,而feature则是特征(比如你通过一些特征黄色,圆,得出是月亮)。如果你训练出feature和label的关系,之后你可以通过feature得出label。
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号