【Spark-SQL学习之三】 UDF、UDAF、开窗函数
环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk1.8
scala-2.10.4(依赖jdk1.8)
spark-1.6
一、UDF:用户自定义函数。
可以自定义类实现UDFX接口
示例代码:
Java:
package com.wjy.df; import java.util.ArrayList; import java.util.Arrays; import java.util.List; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.Function; import org.apache.spark.sql.DataFrame; import org.apache.spark.sql.Row; import org.apache.spark.sql.RowFactory; import org.apache.spark.sql.SQLContext; import org.apache.spark.sql.api.java.UDF1; import org.apache.spark.sql.api.java.UDF2; import org.apache.spark.sql.types.DataTypes; import org.apache.spark.sql.types.StructField; import org.apache.spark.sql.types.StructType; public class UDF { public static void main(String[] args) { SparkConf conf = new SparkConf().setMaster("local").setAppName("UDF"); JavaSparkContext sc = new JavaSparkContext(conf); SQLContext sqlContext = new SQLContext(sc); JavaRDD<String> rdd = sc.parallelize(Arrays.asList("xiaoming","xiaohong","xiaolei")); JavaRDD<Row> rdd2 = rdd.map(new Function<String, Row>() { private static final long serialVersionUID = 1L; @Override public Row call(String str) throws Exception { return RowFactory.create(str); } }); /** * 动态创建Schema方式加载DF */ List<StructField> fields = new ArrayList<StructField>(); fields.add(DataTypes.createStructField("name", DataTypes.StringType, true)); StructType schema = DataTypes.createStructType(fields); DataFrame dataFrame = sqlContext.createDataFrame(rdd2, schema); dataFrame.registerTempTable("user"); //定义一个统计字符串长度的函数 /** * 根据UDF函数参数的个数来决定是实现哪一个UDF UDF1,UDF2。。。。UDF1xxx */ sqlContext.udf().register("StrLen", new UDF1<String, Integer>() { private static final long serialVersionUID = 1L; @Override public Integer call(String str) throws Exception { return str.length(); } },DataTypes.IntegerType); sqlContext.sql("select name ,StrLen(name) as length from user").show(); /* * +--------+------+ | name|length| +--------+------+ |xiaoming| 8| |xiaohong| 8| | xiaolei| 7| +--------+------+ */ sqlContext.udf().register("StrLen2", new UDF2<String, Integer, Integer>() { private static final long serialVersionUID = 1L; @Override public Integer call(String str, Integer num) throws Exception { return str.length()+num; } }, DataTypes.IntegerType); sqlContext.sql("select name ,StrLen2(name,10) as length from user").show(); /* * +--------+------+ | name|length| +--------+------+ |xiaoming| 18| |xiaohong| 18| | xiaolei| 17| +--------+------+ */ sc.stop(); } }
Scala:
package com.wjy.df import org.apache.spark.SparkConf import org.apache.spark.SparkContext import org.apache.spark.sql.RowFactory import org.apache.spark.sql.types.DataTypes import org.apache.spark.sql.types.StructField import org.apache.spark.sql.types.StringType import org.apache.spark.sql.SQLContext object UDF { def main(args:Array[String]):Unit={ val conf = new SparkConf().setMaster("local").setAppName(""); val sc = new SparkContext(conf); val sqlContext = new SQLContext(sc); val rdd = sc.makeRDD(Array("zhansan","lisi","wangwu")); val row = rdd.map(x=>{ RowFactory.create(x); }); val schema = DataTypes.createStructType(Array(StructField("name",StringType,true))); val df = sqlContext.createDataFrame(row, schema); df.show;//show方法可以没有() df.registerTempTable("user"); //StrLen sqlContext.udf.register("StrLen", (s:String)=>{s.length()}); sqlContext.sql("select name ,StrLen(name) as length from user").show; //StrLen2 sqlContext.udf.register("StrLen2", (s:String,i:Integer)=>{s.length()+i}); sqlContext.sql("select name ,StrLen2(name,10) as length from user").show; sc.stop(); } }
二、UDAF:用户自定义聚合函数。
实现UDAF函数如果要自定义类要继承UserDefinedAggregateFunction类
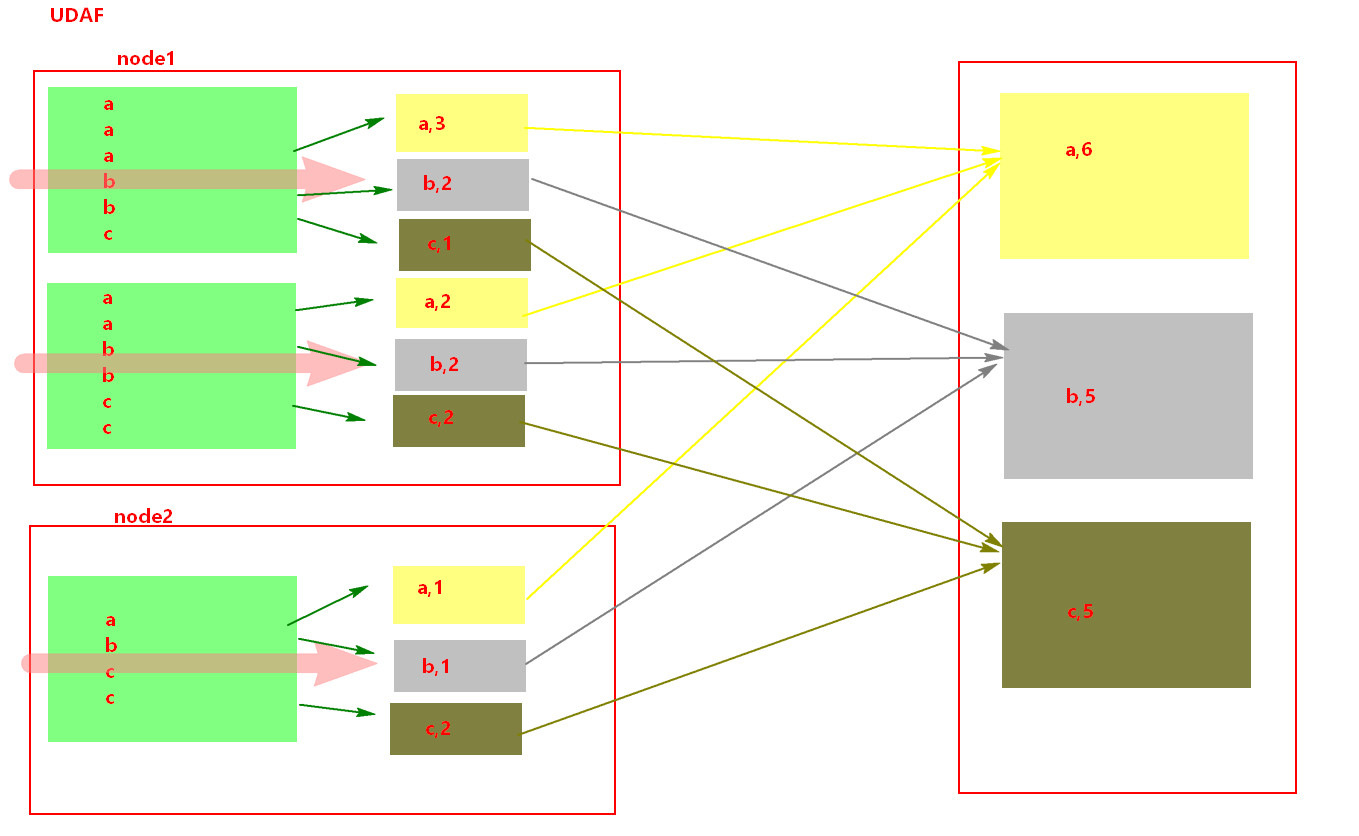
示例代码:
Java:
package com.wjy.df; import java.util.ArrayList; import java.util.Arrays; import java.util.List; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.Function; import org.apache.spark.sql.DataFrame; import org.apache.spark.sql.Row; import org.apache.spark.sql.RowFactory; import org.apache.spark.sql.SQLContext; import org.apache.spark.sql.expressions.MutableAggregationBuffer; import org.apache.spark.sql.expressions.UserDefinedAggregateFunction; import org.apache.spark.sql.types.DataType; import org.apache.spark.sql.types.DataTypes; import org.apache.spark.sql.types.StructField; import org.apache.spark.sql.types.StructType; /** * UDAF 用户自定义聚合函数 * @author root * */ public class UDAF { public static void main(String[] args) { SparkConf conf = new SparkConf().setMaster("local").setAppName("UDAF"); JavaSparkContext sc = new JavaSparkContext(conf); SQLContext sqlContext = new SQLContext(sc); JavaRDD<String> parallelize = sc.parallelize( Arrays.asList("zhangsan","lisi","wangwu","zhangsan","zhangsan","lisi")); JavaRDD<Row> rowRDD = parallelize.map(new Function<String, Row>() { private static final long serialVersionUID = 1L; @Override public Row call(String s) throws Exception { return RowFactory.create(s); } }); List<StructField> fields = new ArrayList<StructField>(); fields.add(DataTypes.createStructField("name", DataTypes.StringType, true)); StructType schema = DataTypes.createStructType(fields); DataFrame df = sqlContext.createDataFrame(rowRDD, schema); df.registerTempTable("user"); /** * 注册一个UDAF函数,实现统计相同值得个数 * 注意:这里可以自定义一个类继承UserDefinedAggregateFunction类也是可以的 */ sqlContext.udf().register("StringCount",new UserDefinedAggregateFunction(){ private static final long serialVersionUID = 1L; /** * 初始化一个内部的自己定义的值,在Aggregate之前每组数据的初始化结果 */ @Override public void initialize(MutableAggregationBuffer buffer) { buffer.update(0, 0); } /** * 指定输入字段的字段及类型 */ @Override public StructType inputSchema() { return DataTypes.createStructType(Arrays.asList(DataTypes.createStructField("name", DataTypes.StringType, true))); } /** * 更新 可以认为一个一个地将组内的字段值传递进来 实现拼接的逻辑 * buffer.getInt(0)获取的是上一次聚合后的值 * 相当于map端的combiner,combiner就是对每一个map task的处理结果进行一次小聚合 * 大聚和发生在reduce端. * 这里即是:在进行聚合的时候,每当有新的值进来,对分组后的聚合如何进行计算 */ @Override public void update(MutableAggregationBuffer buffer, Row arg1) { buffer.update(0, buffer.getInt(0)+1); } /** * 在进行聚合操作的时候所要处理的数据的结果的类型 */ @Override public StructType bufferSchema() { return DataTypes.createStructType(Arrays.asList(DataTypes.createStructField("buffer", DataTypes.IntegerType, true))); } /** * 合并 update操作,可能是针对一个分组内的部分数据,在某个节点上发生的 但是可能一个分组内的数据,会分布在多个节点上处理 * 此时就要用merge操作,将各个节点上分布式拼接好的串,合并起来 * buffer1.getInt(0) : 大聚合的时候 上一次聚合后的值 * buffer2.getInt(0) : 这次计算传入进来的update的结果 * 这里即是:最后在分布式节点完成后需要进行全局级别的Merge操作 */ @Override public void merge(MutableAggregationBuffer buffer1, Row buffer2) { buffer1.update(0, buffer1.getInt(0) + buffer2.getInt(0)); } /** * 指定UDAF函数计算后返回的结果类型 */ @Override public DataType dataType() { return DataTypes.IntegerType; } /** * 最后返回一个和dataType方法的类型要一致的类型,返回UDAF最后的计算结果 */ @Override public Object evaluate(Row row) { return row.getInt(0); } /** * 确保一致性 一般用true,用以标记针对给定的一组输入,UDAF是否总是生成相同的结果。 */ @Override public boolean deterministic() { return true; } }); sqlContext.sql("select name ,StringCount(name) as strCount from user group by name").show(); sc.stop(); } }
Scala:
package com.wjy.df import org.apache.spark.SparkConf import org.apache.spark.SparkContext import org.apache.spark.sql.SQLContext import org.apache.spark.sql.types.DataTypes import org.apache.spark.sql.types.StringType import org.apache.spark.sql.RowFactory import org.apache.spark.sql.expressions.UserDefinedAggregateFunction import org.apache.spark.sql.types.IntegerType import org.apache.spark.sql.expressions.MutableAggregationBuffer import org.apache.spark.sql.Row import org.apache.spark.sql.types.StructType import org.apache.spark.sql.types.DataType class MyUDAF extends UserDefinedAggregateFunction{ // 为每个分组的数据执行初始化值 def initialize(buffer: MutableAggregationBuffer): Unit = { buffer(0) = 0 } //输入数据的类型 def inputSchema: StructType = { DataTypes.createStructType(Array(DataTypes.createStructField("input", StringType, true))) } // 每个组,有新的值进来的时候,进行分组对应的聚合值的计算 def update(buffer: MutableAggregationBuffer, input: Row): Unit = { buffer(0) = buffer.getAs[Int](0)+1 } // 聚合操作时,所处理的数据的类型 def bufferSchema: StructType = { DataTypes.createStructType(Array(DataTypes.createStructField("aaa", IntegerType, true))) } //最后merger的时候,在各个节点上的聚合值,要进行merge,也就是合并 def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = { buffer1(0) = buffer1.getAs[Int](0)+buffer2.getAs[Int](0) } // 最终函数返回值的类型 def dataType: DataType = { DataTypes.IntegerType } // 最后返回一个最终的聚合值 要和dataType的类型一一对应 def evaluate(buffer: Row): Any = { buffer.getAs[Int](0) } //保持一致性 def deterministic: Boolean = { true } } object UDAF { def main(args: Array[String]): Unit = { val conf = new SparkConf() conf.setMaster("local").setAppName("udaf") val sc = new SparkContext(conf) val sqlContext = new SQLContext(sc) val rdd = sc.makeRDD(Array("zhangsan","lisi","wangwu","zhangsan","lisi")) val rowRDD = rdd.map { x => {RowFactory.create(x)} } val schema = DataTypes.createStructType(Array(DataTypes.createStructField("name", StringType, true))) val df = sqlContext.createDataFrame(rowRDD, schema) df.show() df.registerTempTable("user") /** * 注册一个udaf函数 */ sqlContext.udf.register("StringCount", new MyUDAF()) sqlContext.sql("select name ,StringCount(name) as count from user group by name").show() sc.stop() } }
三、开窗函数
开窗函数格式:
row_number() over (partitin by XXX order by XXX)
注意:
row_number() 开窗函数是按照某个字段分组,然后取另一字段的前几个的值,相当于分组取topN;
如果SQL语句里面使用到了开窗函数,那么这个SQL语句必须使用HiveContext来执行,HiveContext默认情况下在本地无法创建。
示例代码:
Java:
package com.wjy.df; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.sql.DataFrame; import org.apache.spark.sql.SaveMode; import org.apache.spark.sql.hive.HiveContext; public class RowNumberWindowFun { public static void main(String[] args) { SparkConf conf = new SparkConf(); conf.setAppName("windowfun"); conf.set("spark.sql.shuffle.partitions","1"); JavaSparkContext sc = new JavaSparkContext(conf); HiveContext hiveContext = new HiveContext(sc); hiveContext.sql("use spark"); hiveContext.sql("drop table if exists sales"); hiveContext.sql("create table if not exists sales (riqi string,leibie string,jine Int) " + "row format delimited fields terminated by '\t'"); hiveContext.sql("load data local inpath '/root/test/sales' into table sales"); /** * 开窗函数格式: * 【 row_number() over (partition by XXX order by XXX DESC) as rank】 * 注意:rank 从1开始 */ /** * 以类别分组,按每种类别金额降序排序,显示 【日期,种类,金额】 结果,如: * * 1 A 100 * 2 B 200 * 3 A 300 * 4 B 400 * 5 A 500 * 6 B 600 * 排序后: * 5 A 500 --rank 1 * 3 A 300 --rank 2 * 1 A 100 --rank 3 * 6 B 600 --rank 1 * 4 B 400 --rank 2 * 2 B 200 --rank 3 * */ DataFrame result = hiveContext.sql("select riqi,leibie,jine " + "from (" + "select riqi,leibie,jine," + "row_number() over (partition by leibie order by jine desc) rank " + "from sales) t " + "where t.rank<=3"); result.show(100); /** * 将结果保存到hive表sales_result */ result.write().mode(SaveMode.Overwrite).saveAsTable("sales_result"); sc.stop(); } }
Scala:
package com.wjy.df import org.apache.spark.SparkConf import org.apache.spark.SparkContext import org.apache.spark.sql.hive.HiveContext object RowNumberWindowFun { val conf = new SparkConf() conf.setAppName("windowfun") val sc = new SparkContext(conf) val hiveContext = new HiveContext(sc) hiveContext.sql("use spark"); hiveContext.sql("drop table if exists sales"); hiveContext.sql("create table if not exists sales (riqi string,leibie string,jine Int) " + "row format delimited fields terminated by '\t'"); hiveContext.sql("load data local inpath '/root/test/sales' into table sales"); /** * 开窗函数格式: * 【 rou_number() over (partitin by XXX order by XXX) 】 */ val result = hiveContext.sql("select riqi,leibie,jine " + "from (" + "select riqi,leibie,jine," + "row_number() over (partition by leibie order by jine desc) rank " + "from sales) t " + "where t.rank<=3"); result.show(); sc.stop() }
参考:
Spark
学习技术不是用来写HelloWorld和Demo的,而是要用来解决线上系统的真实问题的.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号