【Spark-core学习之五】 RDD宽窄依赖 & Stage
环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk1.8
scala-2.10.4(依赖jdk1.8)
spark-1.6
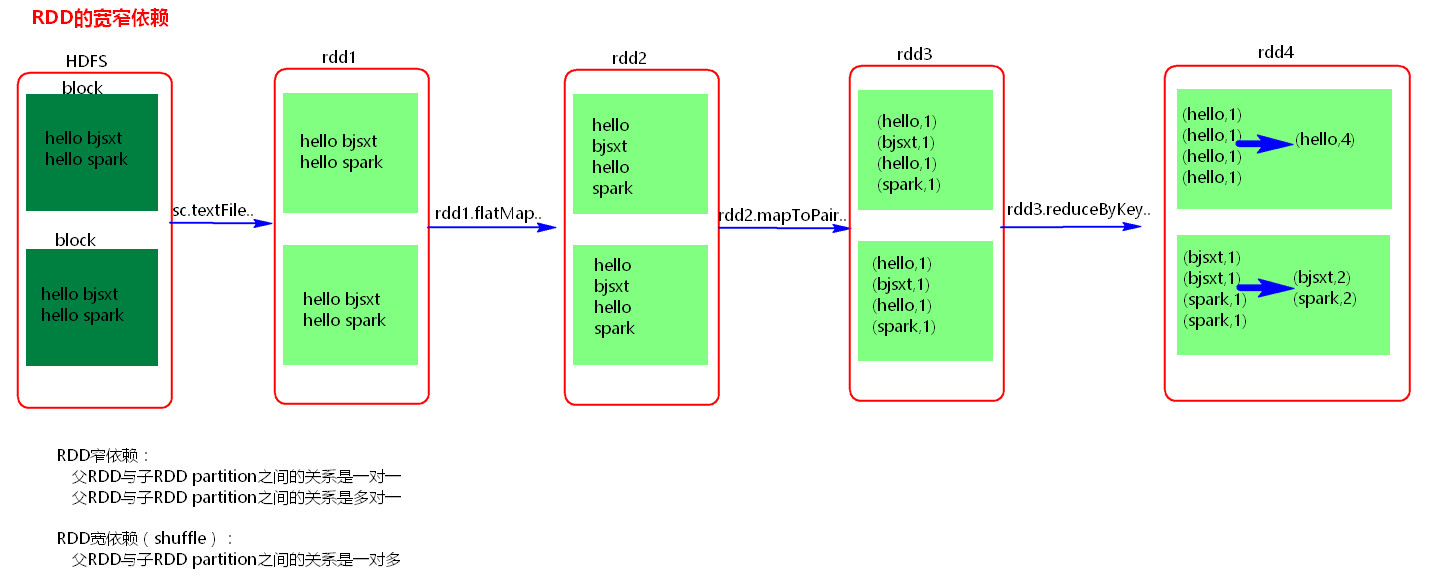
一、RDD之间有一系列的依赖关系,依赖关系又分为窄依赖和宽依赖。
示例:
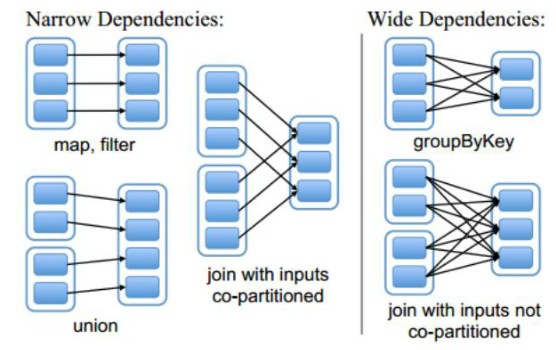
窄依赖:父RDD和子RDD partition之间的关系是一对一的;
父RDD一个partition只对应一个子RDD的partition情况下的父RDD和子RDD partition关系是多对一的。
不会有shuffle的产生。
宽依赖:父RDD与子RDD partition之间的关系是一对多。会有shuffle的产生。
宽窄依赖图:
二、Stage
Spark任务会根据RDD之间的依赖关系,形成一个DAG有向无环图,DAG会提交给DAGScheduler,DAGScheduler会把DAG划分相互依赖的多个stage,划分stage的依据就是RDD之间的宽窄依赖。遇到宽依赖就划分stage,每个stage包含一个或多个task任务。然后将这些task以taskSet的形式提交给TaskScheduler运行。
stage是由一组并行的task组成。
1、stage切割规则:从后往前,遇到宽依赖就切割stage。
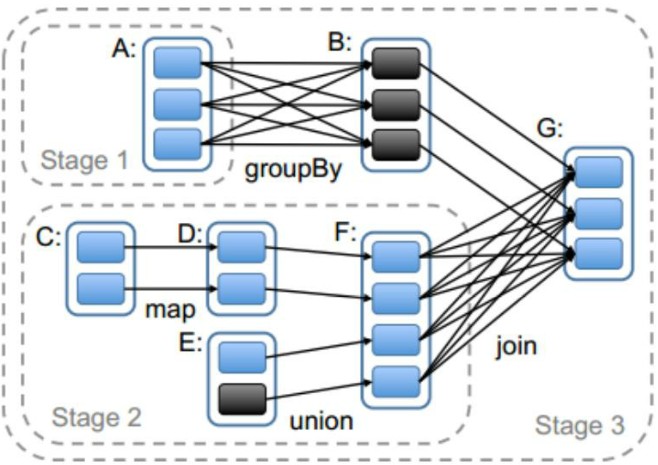
2、stage计算模式:pipeline管道计算模式,pipeline只是一种计算思想,模式

3、数据一直在管道里面什么时候数据会落地?
(1)对RDD进行持久化。
(2)shuffle write的时候。
4、Stage的task并行度是由stage的最后一个RDD的分区数来决定的 。
5、如何改变RDD的分区数?例如:reduceByKey(XXX,3),GroupByKey(4)
参考:
Spark

 浙公网安备 33010602011771号
浙公网安备 33010602011771号