【Redis学习之六】Redis数据类型:集合和有序集合
环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk8
redis-2.8.18
一、集合 Set
无序的、去重的
元素是字符串类型
最多包含2^32-1元素
(1)添加
增加一个或多个元素
SADD key member [member ...]
如果元素已经存在,则自动忽略
(2)删除
移除一个或者多个元素
SREM key member [member ...]
元素不存在,自动忽略
随机从集合中移除并返回这个被移除的元素
SPOP key
把元素从源集合移动到目标集合
SMOVE source destination member
(3)获取
返回集合包含的所有元素
SMEMBERS key
如果集合元素过多,例如百万个,需要遍历,可能会造成服务器阻塞,生产环境应避免使用
注意, SMEMBERS 有可能返回不同的结果,所以,如果需要存储有序且不重复的数据使用有序集合,存储有序可重复的使用列表
检查给定元素是否存在于集合中
SISMEMBER key member
(4)随机获取指定个数的元素
随机返回集合中指定个数的
SRANDMEMBER key [count]
如果 count 为正数,且小于集合基数,那么命令返回一个包含 count 个元素的数组,数组中的元素各不相同。如果 count 大于等于集合基数,那么返回整个集合 最多返回整个集合 conut>=0
如果 count 为负数,那么命令返回一个数组,数组中的元素可能会重复出现多次,而数组的长度为 count 的绝对值 count < 0 长度为count绝对值,元素可能重复
如果 count 为 0,返回空
如果 count 不指定,随机返回一个元素
(5)个数
返回集合中元素的个数
SCARD key
键的结果会保存信息,集合长度就记录在里面,所以不需要遍历
(6)集合操作
差集
SDIFF key [key ...],从第一个key的集合中去除其他集合和自己的交集部分
SDIFFSTORE destination key [key ...],将差集结果存储在目标key中
交集
SINTER key [key ...],取所有集合交集部分
SINTERSTORE destination key [key ...],将交集结果存储在目标key中
并集
SUNION key [key ...],取所有集合并集
SUNIONSTORE destination key [key ...],将并集结果存储在目标key中
案例:
新浪微博的共同关注
需求:当用户访问另一个用户的时候,会显示出两个用户共同关注哪些相同的用户
设计:将每个用户关注的用户放在集合中,求交集即可
二、SortedSet有序集合
类似Set集合
有序的、去重的
元素是字符串类型
每一个元素都关联着一个浮点数分值(Score),并按照分值从小到大的顺序排列集合中的元素。分值可以相同
最多包含2^32-1元素
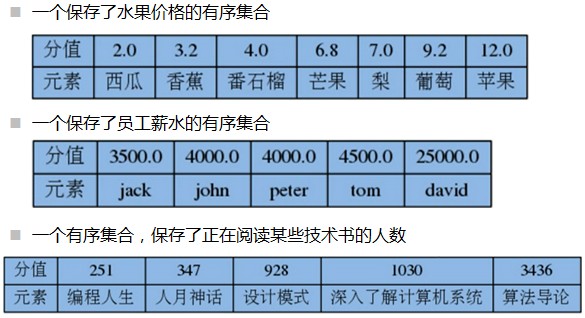
(1)增加
增加一个或多个元素
ZADD key score member [score member ...]
如果元素已经存在,则使用新的score
举例
ZADD fruits 3.2 香蕉
ZADD fruits 2.0 西瓜
ZADD fruits 4.0 番石榴 7.0 梨 6.8 芒果
(2)删除
移除一个或者多个元素
ZREM key member [member ...]
元素不存在,自动忽略
举例
ZREM fruits 番石榴 梨 芒果
ZREM fruits 西瓜
(3)获取元素
显示分值
ZSCORE key member
(4)增加或者减少分值
ZINCRBY key increment member
increment为负数就是减少
举例
ZINCRBY fruits 1.5 西瓜
ZINCRBY fruits -0.8 香蕉
(5)返回元素的排名(索引)
ZRANK key member
举例
ZRANK fruits 西瓜
ZRANK fruits 番石榴
ZRANK fruits 芒果

返回元素的逆序排名
ZREVRANK key member
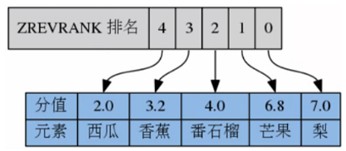
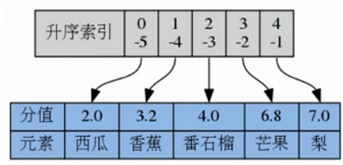
(6)返回指定索引区间元素
ZRANGE key start stop [WITHSCORES]
如果score相同,则按照字典序lexicographical order 排列
默认按照score从小到大,如果需要score从大到小排列,使用ZREVRANGE
举例
ZRANGE fruits 0 2
ZRANGE fruits -5 -4
返回指定索引区间元素
ZREVRANGE key start stop [WITHSCORES]
如果score相同,则按照字典序lexicographical order 的 逆序 排列
默认按照score从大到小,如果需要score从小到大排列,使用ZRANGE
(7)返回指定分值区间元素
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
返回score默认属于[min,max]之间,元素按照score升序排列,score相同字典序
LIMIT中offset代表跳过多少个元素,count是返回几个。类似于Mysql
使用小括号,修改区间为开区间,例如(5、(10、5)
-inf和+inf表示负无穷和正无穷
举例
ZRANGEBYSCORE fruits 4.0 7.0
ZRANGEBYSCORE fruits (4 7
ZRANGEBYSCORE fruits -inf +inf
返回指定分值区间元素
ZREVRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
返回score默认属于[min,max]之间,元素按照score降序排列,score相同字典降序
LIMIT中offset代表跳过多少个元素,count是返回几个。类似于Mysql
使用小括号,修改区间为开区间,例如(5、(10、5)
-inf和+inf表示负无穷和正无穷
(8)移除指定排名范围的元素
ZREMRANGEBYRANK key start stop
举例
ZREMRANGEBYRANK fruits 0 2
ZRANGE fruits 0 -1
移除指定分值范围的元素
ZREMRANGEBYSCORE key min max
举例
ZREMRANGEBYSCORE fruits 3.0 5.0
ZRANGE fruits 0 -1
(9)返回集合中元素个数
ZCARD key
返回指定范围中元素的个数
ZCOUNT key min max
ZCOUNT fruits 4 7
ZCOUNT fruits (4 7
(10)并集
ZUNIONSTORE destination numkeys key [key ...] [WEIGHTS weight] [AGGREGATE SUM|MIN|MAX]
numkeys指定key的数量,必须
WEIGHTS选项,与前面设定的key对应,对应key中每一个score都要乘以这个权重
AGGREGATE选项,指定并集结果的聚合方式
SUM:将所有集合中某一个元素的score值之和作为结果集中该成员的score值
MIN:将所有集合中某一个元素的score值中最小值作为结果集中该成员的score值
MAX:将所有集合中某一个元素的score值中最大值作为结果集中该成员的score值
交集
ZINTERSTORE destination numkeys key [key ...] [WEIGHTS weight] [AGGREGATE SUM|MIN|MAX]
numkeys指定key的数量,必须
WEIGHTS选项,与前面设定的key对应,对应key中每一个score都要乘以这个权重
AGGREGATE选项,指定并集结果的聚合方式
SUM:将所有集合中某一个元素的score值之和作为结果集中该成员的score值
MIN:将所有集合中某一个元素的score值中最小值作为结果集中该成员的score值
MAX:将所有集合中某一个元素的score值中最大值作为结果集中该成员的score值

 浙公网安备 33010602011771号
浙公网安备 33010602011771号