【Elasticsearch学习之三】Elasticsearch 搜索引擎案例
环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk8
elasticsearch-2.2.0
第一步:获取数据
主流搜索引擎,会使用爬虫,来获取网站的html数据,常用的工具有nutch,Python(主流),wget(c语言)
这里使用wget模拟
#安装wget
yum install wget
#使用wget从文件wget.log爬取数据
#参数:
#-o 指定爬取内容输出日志名
#-P 爬取生成文件目录父目录
#-m 拷贝
#-D 列举爬取域名清单
#-N 不重新检索文件, 除非更新文件时间晚于本地时间
#--convert-links 根据路径转换成目录
#--random-wait 随机等待 间隔性爬取 以防止被禁止访问
#-A 指定文档类型
#最后指定爬取网站地址
[cluster@PCS101 /] wget -o /tmp/wget.log -P /root/data --no-parent --no-verbose -m -D news.cctv.com -N --convert-links --random-wait -A html,HTML,shtml,SHTML http://news.cctv.com
第二步:ES集群安装分词器IK
注意:必选选择与ES对应的IK版本 https://github.com/medcl/elasticsearch-analysis-ik
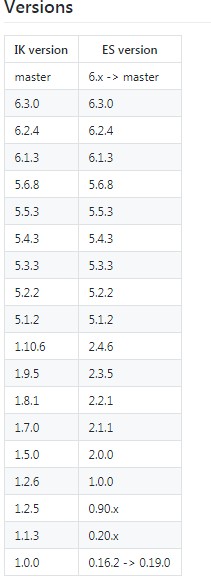
#将ik目录直接ftp上传到目录下/opt/cluster/es/elasticsearch-2.2.1/plugins
#更改目录所有者
[cluster@PCS101 plugins]$ chown -R cluster:cluster ik
修改配置 plugin-descriptor.properties
elasticsearch.version=2.2.1
分发至102、103:
[cluster@PCS101 plugins]$ scp -r ik/ cluster@PCS102:`pwd`
[cluster@PCS101 plugins]$ scp -r ik/ cluster@PCS103:`pwd`
第三步:数据抽取:从网页中抽取数据
HtmlTool.java
package com.sxt.util; import java.io.File; import com.sxt.es.HtmlBean; import com.sxt.es.IndexService; import net.htmlparser.jericho.CharacterReference; import net.htmlparser.jericho.Element; import net.htmlparser.jericho.HTMLElementName; import net.htmlparser.jericho.Source; public class HtmlTool { /** * 数据过滤清洗 将网页转换成javabean * @param path html 文件路径 */ public static HtmlBean parserHtml(String path)throws Throwable{ HtmlBean bean =new HtmlBean(); Source source=new Source(new File(path)); source.fullSequentialParse(); Element titleElement=source.getFirstElement(HTMLElementName.TITLE); if(titleElement==null){ return null; }else{ String title=CharacterReference.decodeCollapseWhiteSpace(titleElement.getContent()); bean.setTitle(title); } String content =source.getTextExtractor().setIncludeAttributes(true).toString(); String url =path.substring(IndexService.DATA_DIR.length()); bean.setContent(content); bean.setUrl(url); return bean; } /** * @param args */ public static void main(String[] args) { try { System.out.println(parserHtml("e:\\data\\news.cctv.com\\2017\\05\\01\\ARTI0k5MFLx2cvzQZffwQcUp170501.shtml").getContent()); } catch (Throwable e) { e.printStackTrace(); } } }
HtmlBean.java
package com.sxt.es; public class HtmlBean { private int id; private String title; private String content; private String url; public int getId() { return id; } public void setId(int id) { this.id = id; } public String getTitle() { return title; } public void setTitle(String title) { this.title = title; } public String getContent() { return content; } public void setContent(String content) { this.content = content; } public String getUrl() { return url; } public void setUrl(String url) { this.url = url; } }
第四步:把抽取出来的数据同ES建立索引
#创建索引库
IndexService.java::createIndex
#数据同ES建立索引
IndexService.java::addHtmlToES
package com.sxt.es; import java.io.File; import java.net.InetAddress; import java.util.HashMap; import java.util.Map; import org.elasticsearch.action.admin.indices.exists.indices.IndicesExistsResponse; import org.elasticsearch.action.admin.indices.mapping.put.PutMappingRequest; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.client.Client; import org.elasticsearch.client.Requests; import org.elasticsearch.client.transport.TransportClient; import org.elasticsearch.common.settings.Settings; import org.elasticsearch.common.text.Text; import org.elasticsearch.common.transport.InetSocketTransportAddress; import org.elasticsearch.common.xcontent.XContentBuilder; import org.elasticsearch.common.xcontent.XContentFactory; import org.elasticsearch.index.query.BoolQueryBuilder; import org.elasticsearch.index.query.MatchQueryBuilder; import org.elasticsearch.index.query.MultiMatchQueryBuilder; import org.elasticsearch.index.query.MultiMatchQueryParser; import org.elasticsearch.index.query.RangeQueryBuilder; import org.elasticsearch.search.SearchHit; import org.elasticsearch.search.SearchHits; import org.junit.Test; import org.springframework.stereotype.Service; import com.sxt.util.HtmlTool; @Service public class IndexService { //存放html文件的目录 public static String DATA_DIR="e:\\data\\"; //定义客户端 public static Client client; static { //设置连接集群名 Settings settings = Settings.settingsBuilder().put("cluster.name", "wjy-es").build(); try { //创建连接集群客户端 client = TransportClient .builder() .settings(settings) .build() .addTransportAddress( new InetSocketTransportAddress(InetAddress .getByName("134.32.123.101"), 9300)) .addTransportAddress( new InetSocketTransportAddress(InetAddress .getByName("134.32.123.102"), 9300)) .addTransportAddress( new InetSocketTransportAddress(InetAddress .getByName("134.32.123.103"), 9300)); } catch (Exception e) { e.printStackTrace(); } } /** * 创建索引库 * admin():管理索引库的。client.admin().indices() * 索引数据的管理:client.prepare */ @Test public void createIndex() throws Exception { IndicesExistsResponse resp = client.admin().indices().prepareExists("testes").execute().actionGet(); //存在删除旧的 if(resp.isExists()){ client.admin().indices().prepareDelete("testes").execute().actionGet(); } //创建 client.admin().indices().prepareCreate("testes").execute().actionGet(); new XContentFactory(); XContentBuilder builder = XContentFactory.jsonBuilder() .startObject() .startObject("htmlbean") .startObject("properties")//type .startObject("title") .field("type", "string")//字符串类型 .field("store", "yes")//是否保存 .field("analyzer", "ik_max_word")//指定分词器 .field("search_analyzer", "ik_max_word")//指定搜索依赖的分词器 .endObject() .startObject("content") .field("type", "string") .field("store", "yes") .field("analyzer", "ik_max_word") .field("search_analyzer", "ik_max_word") .endObject() .startObject("url") .field("type", "string") .field("store", "yes") .field("analyzer", "ik_max_word") .field("search_analyzer", "ik_max_word") .endObject() .endObject() .endObject() .endObject(); //创建type PutMappingRequest mapping = Requests.putMappingRequest("testes").type("htmlbean").source(builder); client.admin().indices().putMapping(mapping).actionGet(); } /** * 把源数据html文件添加到索引库中(构建索引文件) */ @Test public void addHtmlToES(){ readHtml(new File(DATA_DIR)); } /** * 遍历数据文件目录d:/data ,递归方法 * @param file */ public void readHtml(File file){ if(file.isDirectory()){ File[] fs =file.listFiles(); for (int i = 0; i < fs.length; i++) { File f = fs[i]; readHtml(f); } }else{ HtmlBean bean; try { bean = HtmlTool.parserHtml(file.getPath()); if(bean!=null){ Map<String, String> dataMap =new HashMap<String, String>(); dataMap.put("title", bean.getTitle()); dataMap.put("content", bean.getContent()); dataMap.put("url", bean.getUrl()); //写索引 client.prepareIndex("testes", "htmlbean").setSource(dataMap).execute().actionGet(); } } catch (Throwable e) { e.printStackTrace(); } } } /** * 搜索 * @param kw * @param num * @return */ public PageBean<HtmlBean> search(String kw,int num,int count){ PageBean<HtmlBean> wr =new PageBean<HtmlBean>(); wr.setIndex(num); // //构建查询条件 // MatchQueryBuilder q1 =new MatchQueryBuilder("title", kw); // MatchQueryBuilder q2 =new MatchQueryBuilder("content", kw); // // //构建一个多条件查询对象 // BoolQueryBuilder q =new BoolQueryBuilder(); //组合查询条件对象 // q.should(q1); // q.should(q2); // RangeQueryBuilder q1 =new RangeQueryBuilder("age"); // q1.from(18); // q1.to(40); MultiMatchQueryBuilder q =new MultiMatchQueryBuilder(kw, new String[]{"title","content"}); SearchResponse resp=null; if(wr.getIndex()==1){//第一页 resp = client.prepareSearch("testes") .setTypes("htmlbean") .setQuery(q) .addHighlightedField("title") .addHighlightedField("content") .setHighlighterPreTags("<font color=\"red\">") .setHighlighterPostTags("</font>") .setHighlighterFragmentSize(40)//设置显示结果中一个碎片段的长度 .setHighlighterNumOfFragments(5)//设置显示结果中每个结果最多显示碎片段,每个碎片段之间用...隔开 .setFrom(0)//从第几个开始 .setSize(10)//第一页数量 .execute() .actionGet(); }else{ wr.setTotalCount(count); resp = client.prepareSearch("testes") .setTypes("htmlbean") .setQuery(q) .addHighlightedField("title")//高亮显示 .addHighlightedField("content") .setHighlighterPreTags("<font color=\"red\">")//红色显示 .setHighlighterPostTags("</font>") .setHighlighterFragmentSize(40) .setHighlighterNumOfFragments(5) .setFrom(wr.getStartRow()) .setSize(10) .execute() .actionGet(); } SearchHits hits= resp.getHits(); wr.setTotalCount((int)hits.getTotalHits()); for(SearchHit hit : hits.getHits()) { HtmlBean bean =new HtmlBean(); if(hit.getHighlightFields().get("title")==null) {//title中没有包含关键字 bean.setTitle(hit.getSource().get("title").toString());//获取原来的title(没有高亮的title) } else { bean.setTitle(hit.getHighlightFields().get("title").getFragments()[0].toString()); } if(hit.getHighlightFields().get("content")==null) {//content中没有包含关键字 bean.setContent(hit.getSource().get("content").toString());//获取原来的content(没有高亮的content) } else { StringBuilder sb =new StringBuilder(); for(Text text: hit.getHighlightFields().get("content").getFragments()) { sb.append(text.toString()+"..."); } bean.setContent(sb.toString()); } bean.setUrl("http://"+hit.getSource().get("url").toString()); wr.setBean(bean); } return wr; } // @Test // public void del(){ //// client.admin().indices().prepareDelete("testes").execute().actionGet(); // client.admin().indices().prepareDelete("testes").execute().actionGet(); // } }
第五步:搜索数据
IndexService.java::search 见上面代码
PageBean.java
package com.sxt.es; import java.util.ArrayList; import java.util.List; public class PageBean<T> { private int size = 10;//每页显示记录 private int index = 1;// 当前页号 private int totalCount = 0;// 记录总数 private int totalPageCount = 1;// 总页 private int[] numbers;//展示页数集合 protected List<T> list;//要显示到页面的数据集 /** * 得到 * @return */ public int getStartRow() { return (index - 1) * size; } /** * 得到结束记录 * @return */ public int getEndRow() { return index * size; } /** * @return Returns the size. */ public int getSize() { return size; } /** * @param size * The size to set. */ public void setSize(int size) { if (size > 0) { this.size = size; } } /** * @return Returns the currentPageNo. */ public int getIndex() { if (totalPageCount == 0) { return 0; } return index; } /** * @param currentPageNo * The currentPageNo to set. */ public void setIndex(int index) { if (index > 0) { this.index = index; } } /** * @return Returns the totalCount. */ public int getTotalCount() { return totalCount; } /** * @param totalCount * The totalCount to set. */ public void setTotalCount(int totalCount) { if (totalCount >= 0) { this.totalCount = totalCount; setTotalPageCountByRs();//根据总记录数计算总页 } } public int getTotalPageCount() { return this.totalPageCount; } /** * 根据总记录数计算总页 */ private void setTotalPageCountByRs() { if (this.size > 0 && this.totalCount > 0 && this.totalCount % this.size == 0) { this.totalPageCount = this.totalCount / this.size; } else if (this.size > 0 && this.totalCount > 0 && this.totalCount % this.size > 0) { this.totalPageCount = (this.totalCount / this.size) + 1; } else { this.totalPageCount = 0; } setNumbers(totalPageCount);//获取展示页数集合 } public int[] getNumbers() { return numbers; } /** * 设置显示页数集合 * @param totalPageCount */ public void setNumbers(int totalPageCount) { if(totalPageCount>0){ //!.当前数组的长度 int[] numbers = new int[totalPageCount>10?10:totalPageCount];//页面要显示的页数集合 int k =0; // //1.数组长度<10 1 2 3 4 .... 7 //2.数组长度>=10 // 当前页<=6 1 2 3 4 10 // 当前页>=总页数-5 ......12 13 14 15 // 其他 5 6 7 8 当前页(10) 10 11 12 13 for(int i = 0;i < totalPageCount;i++){ //保证当前页为集合的中�? if((i>=index- (numbers.length/2+1) || i >= totalPageCount-numbers.length) && k<numbers.length){ numbers[k] = i+1; k++; }else if(k>=numbers.length){ break; } } this.numbers = numbers; } } public void setNumbers(int[] numbers) { this.numbers = numbers; } public List<T> getList() { return list; } public void setList(List<T> list) { this.list = list; } public void setBean(T bean){ if(this.list==null){ list =new ArrayList<T>(); } list.add(bean); } /* public static int getTotalPageCount(int iTotalRecordCount, int iPageSize) { if (iPageSize == 0) { return 0; } else { return (iTotalRecordCount % iPageSize) == 0 ? (iTotalRecordCount / iPageSize) : (iTotalRecordCount / iPageSize) + 1; } }*/ }
启动ES_SEARCH web,访问 http://localhost:8080/ES_SEARCH
输入关键词 搜索:
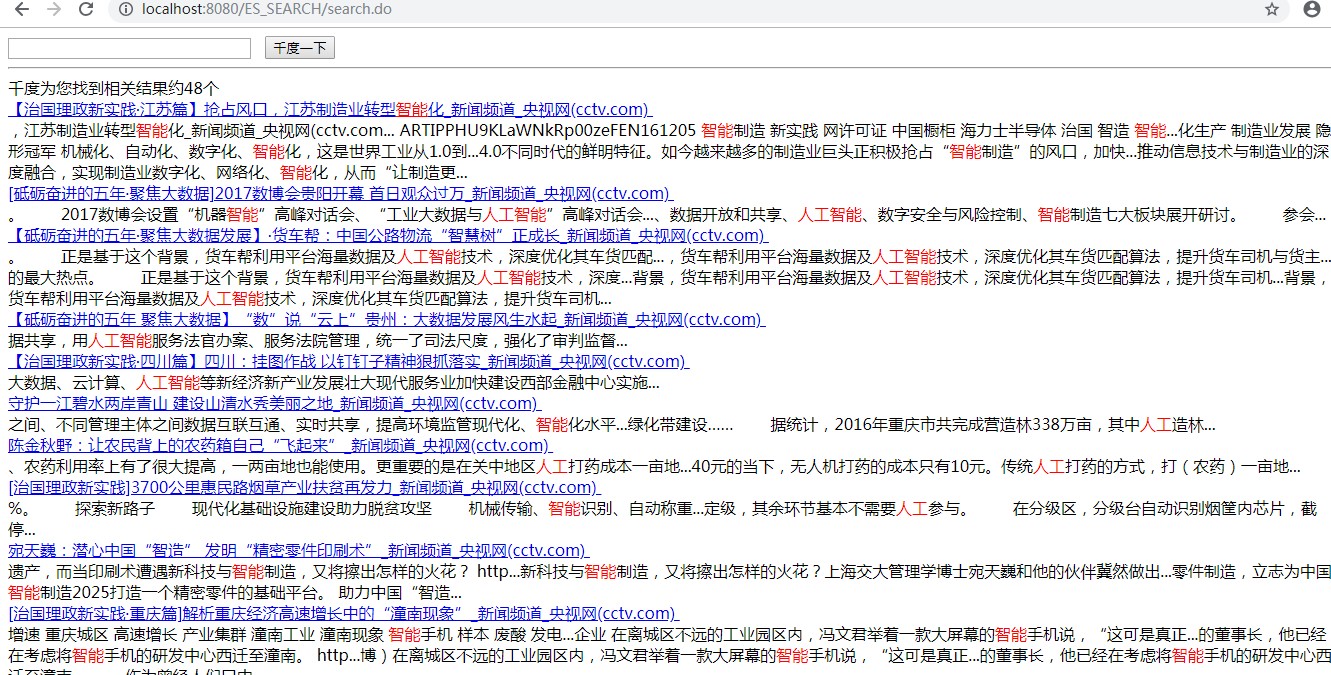
项目代码下载连接:https://download.csdn.net/download/cac2020/11015439

 浙公网安备 33010602011771号
浙公网安备 33010602011771号