【Hadoop学习之十】MapReduce案例分析二-好友推荐
环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk8
hadoop-3.1.1
最应该推荐的好友TopN,如何排名?
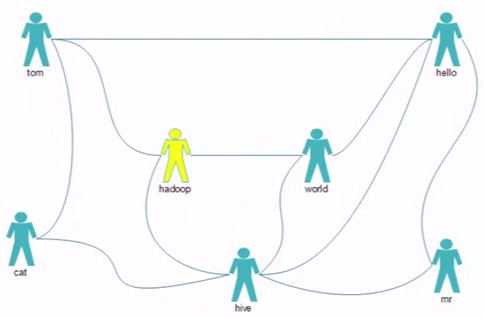

tom hello hadoop cat
world hadoop hello hive
cat tom hive
mr hive hello
hive cat hadoop world hello mr
hadoop tom hive world
hello tom world hive mr
package test.mr.fof; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class MyFOF { /** * 最应该推荐的好友TopN,如何排名? * @param args * @throws Exception */ public static void main(String[] args) throws Exception { Configuration conf = new Configuration(true); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); conf.set("sleep", otherArgs[2]); Job job = Job.getInstance(conf,"FOF"); job.setJarByClass(MyFOF.class); //Map job.setMapperClass(FMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //Reduce job.setReducerClass(FReducer.class); //HDFS 输入路径 Path input = new Path(otherArgs[0]); FileInputFormat.addInputPath(job, input ); //HDFS 输出路径 Path output = new Path(otherArgs[1]); if(output.getFileSystem(conf).exists(output)){ output.getFileSystem(conf).delete(output,true); } FileOutputFormat.setOutputPath(job, output ); System.exit(job.waitForCompletion(true) ? 0 :1); } // tom hello hadoop cat // world hadoop hello hive // cat tom hive // mr hive hello // hive cat hadoop world hello mr // hadoop tom hive world // hello tom world hive mr }
package test.mr.fof; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.util.StringUtils; public class FMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ Text mkey= new Text(); IntWritable mval = new IntWritable(); @Override protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException { //value: 0-直接关系 1-间接关系 //tom hello hadoop cat : hello:hello 1 //hello tom world hive mr hello:hello 0 String[] strs = StringUtils.split(value.toString(), ' '); String user=strs[0]; String user01=null; for(int i=1;i<strs.length;i++){ //与好友清单中好友属于直接关系 mkey.set(fof(strs[0],strs[i])); mval.set(0); context.write(mkey, mval); for (int j = i+1; j < strs.length; j++) { Thread.sleep(context.getConfiguration().getInt("sleep", 0)); //好友列表内 成员之间是间接关系 mkey.set(fof(strs[i],strs[j])); mval.set(1); context.write(mkey, mval); } } } public static String fof(String str1 , String str2){ if(str1.compareTo(str2) > 0){ //hello,hadoop return str2+":"+str1; } //hadoop,hello return str1+":"+str2; } }
package test.mr.fof; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class FReducer extends Reducer<Text, IntWritable, Text, Text> { Text rval = new Text(); @Override protected void reduce(Text key, Iterable<IntWritable> vals, Context context) throws IOException, InterruptedException { //是简单的好友列表的差集吗? //最应该推荐的好友TopN,如何排名? //hadoop:hello 1 //hadoop:hello 0 //hadoop:hello 1 //hadoop:hello 1 int sum=0; int flg=0; for (IntWritable v : vals) { //0为直接关系 if(v.get()==0){ //hadoop:hello 0 flg=1; } sum += v.get(); } //只有间接关系才会被输出 if(flg==0){ rval.set(sum+""); context.write(key, rval); } } }
学习技术不是用来写HelloWorld和Demo的,而是要用来解决线上系统的真实问题的.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号