【Hadoop学习之八】MapReduce开发
环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk8
hadoop-3.1.1
伪分布式:HDFS和YARN 伪分布式搭建,事先启动HDFS和YARN
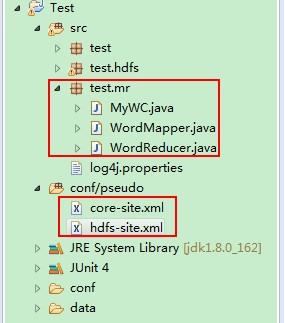
第一步:开发WordCount示例
package test.mr; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class MyWC { public static void main(String[] args) { Configuration conf = new Configuration(); try { Job job = Job.getInstance(conf,"word count"); job.setJarByClass(MyWC.class); job.setMapperClass(WordMapper.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setReducerClass(WordReducer.class); job.setNumReduceTasks(1); // FileInputFormat.addInputPath(job, new Path("hdfs://node1:9820/wjy/input/text.txt")); // Path output = new Path("hdfs://node1:9820/wjy/output/"); //注意这里设置的目录是从 HDFS根目录开始的 FileInputFormat.addInputPath(job, new Path("/wjy/input/text.txt")); Path output = new Path("/wjy/output/"); if (output.getFileSystem(conf).exists(output)) { output.getFileSystem(conf).delete(output,true); } FileOutputFormat.setOutputPath(job, output); System.exit(job.waitForCompletion(true) ? 0 : 1); } catch (Exception e) { e.printStackTrace(); } } }
package test.mr; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class WordMapper extends Mapper<LongWritable, Text, Text, IntWritable> { // 写在外面 map循环创建会造成内存溢出 private final static IntWritable one = new IntWritable(1); // map写出的数据放到buffer字节数组里 这样word可以继续使用 没有影响 private Text word = new Text(); @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { //StringTokenizer 默认按照空格 制表符 回车等空白符作为分隔符来切分传入的数据 StringTokenizer st = new StringTokenizer(value.toString()); while (st.hasMoreTokens()) { word.set(st.nextToken()); context.write(word, one); } } }
package test.mr; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class WordReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { //key:hello //values:(1,1,1,1,1,1) int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } }
第二步:程序打jar包:MyWC.jar,上传jar和测试文件
[root@node1 ~]# ls MyWC.jar text.txt [root@node1 ~]# hdfs dfs -mkdir /wjy/input [root@node1 ~]# hdfs dfs -mkdir /wjy/output [root@node1 ~]# hdfs dfs -put /root/text.txt /wjy/input
text.txt文件里面是测试数据:
hello sxt 1
hello sxt 2
hello sxt 3
...
hello sxt 1000000
第三步:运行jar:MyWC.jar
[root@node1 ~]# hadoop jar MyWC.jar test.mr.MyWC 2019-01-15 19:06:04,326 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 2019-01-15 19:06:07,698 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032 2019-01-15 19:06:09,247 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 2019-01-15 19:06:09,294 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1547546637762_0003 2019-01-15 19:06:10,518 INFO input.FileInputFormat: Total input files to process : 1 2019-01-15 19:06:11,078 INFO mapreduce.JobSubmitter: number of splits:1 2019-01-15 19:06:11,490 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled 2019-01-15 19:06:14,280 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1547546637762_0003 2019-01-15 19:06:14,287 INFO mapreduce.JobSubmitter: Executing with tokens: [] 2019-01-15 19:06:15,163 INFO conf.Configuration: resource-types.xml not found 2019-01-15 19:06:15,163 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'. 2019-01-15 19:06:15,934 INFO impl.YarnClientImpl: Submitted application application_1547546637762_0003 2019-01-15 19:06:16,436 INFO mapreduce.Job: The url to track the job: http://node1:8088/proxy/application_1547546637762_0003/ 2019-01-15 19:06:16,438 INFO mapreduce.Job: Running job: job_1547546637762_0003 2019-01-15 19:07:48,824 INFO mapreduce.Job: Job job_1547546637762_0003 running in uber mode : false 2019-01-15 19:07:49,614 INFO mapreduce.Job: map 0% reduce 0% 2019-01-15 19:09:10,176 INFO mapreduce.Job: map 67% reduce 0% 2019-01-15 19:09:21,123 INFO mapreduce.Job: map 100% reduce 0% 2019-01-15 19:13:43,544 INFO mapreduce.Job: map 100% reduce 73% 2019-01-15 19:13:49,599 INFO mapreduce.Job: map 100% reduce 100% 2019-01-15 19:14:04,717 INFO mapreduce.Job: Job job_1547546637762_0003 completed successfully 2019-01-15 19:14:08,754 INFO mapreduce.Job: Counters: 53 File System Counters FILE: Number of bytes read=34888902 FILE: Number of bytes written=70205331 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=17888997 HDFS: Number of bytes written=8888922 HDFS: Number of read operations=8 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Launched reduce tasks=1 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=73564 Total time spent by all reduces in occupied slots (ms)=167987 Total time spent by all map tasks (ms)=73564 Total time spent by all reduce tasks (ms)=167987 Total vcore-milliseconds taken by all map tasks=73564 Total vcore-milliseconds taken by all reduce tasks=167987 Total megabyte-milliseconds taken by all map tasks=75329536 Total megabyte-milliseconds taken by all reduce tasks=172018688 Map-Reduce Framework Map input records=1000000 Map output records=3000000 Map output bytes=28888896 Map output materialized bytes=34888902 Input split bytes=101 Combine input records=0 Combine output records=0 Reduce input groups=1000002 Reduce shuffle bytes=34888902 Reduce input records=3000000 Reduce output records=1000002 Spilled Records=6000000 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=1134 CPU time spent (ms)=23710 Physical memory (bytes) snapshot=381153280 Virtual memory (bytes) snapshot=5039456256 Total committed heap usage (bytes)=189894656 Peak Map Physical memory (bytes)=229081088 Peak Map Virtual memory (bytes)=2516492288 Peak Reduce Physical memory (bytes)=152334336 Peak Reduce Virtual memory (bytes)=2522963968 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=17888896 File Output Format Counters Bytes Written=8888922
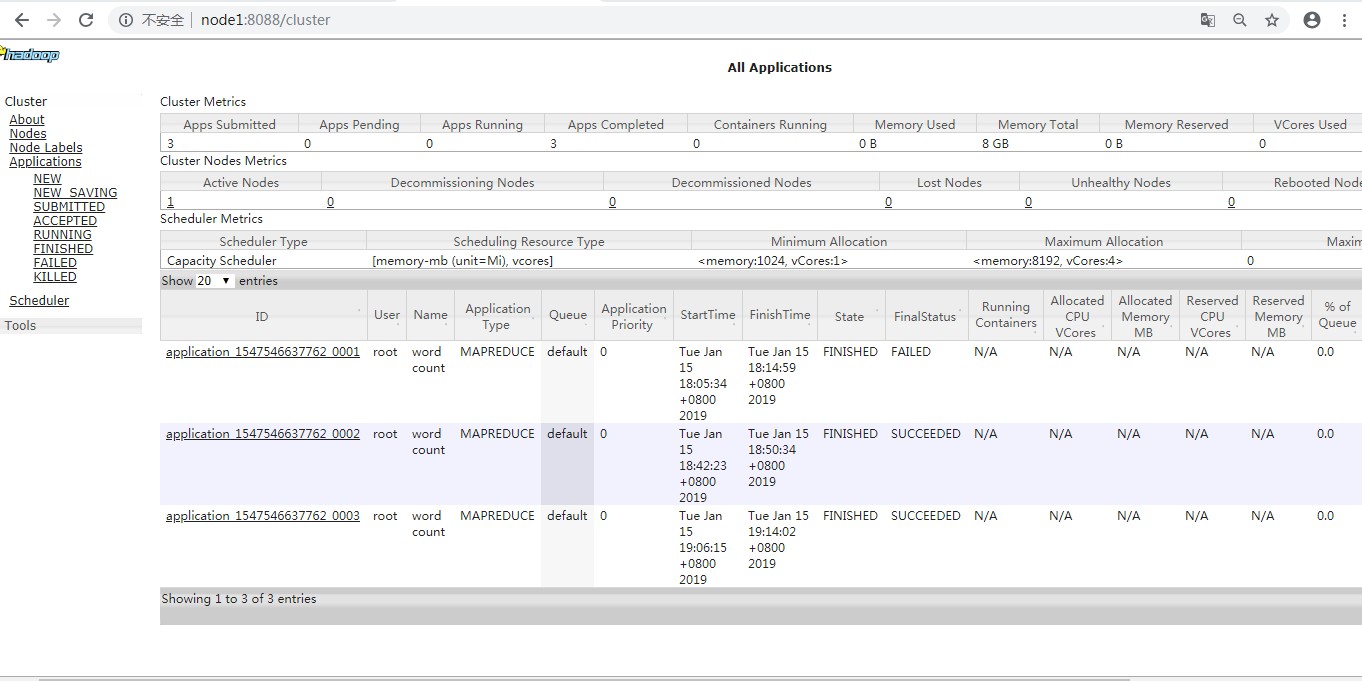
第四步:查看下载处理结果
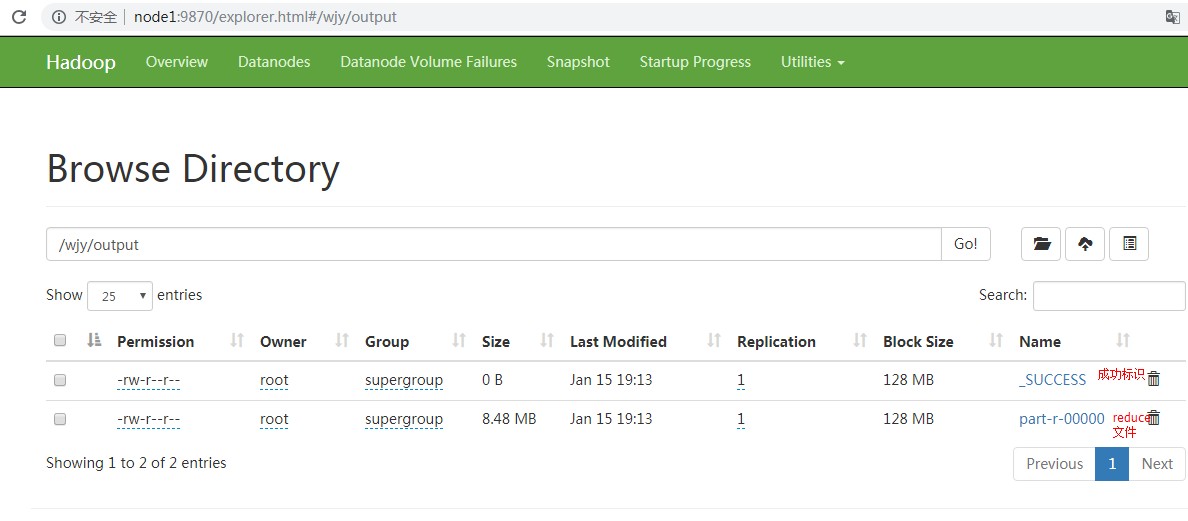
[root@node1 sbin]# hdfs dfs -ls /wjy/output 2019-01-16 00:32:54,137 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Found 2 items -rw-r--r-- 1 root supergroup 0 2019-01-15 19:13 /wjy/output/_SUCCESS -rw-r--r-- 1 root supergroup 8888922 2019-01-15 19:13 /wjy/output/part-r-00000 [root@node1 ~]# hdfs dfs -get /wjy/output/part-r-00000 ./ [root@node1 ~]# vi part-r-00000 999980 1 999981 1 999982 1 999983 1 999984 1 999985 1 999986 1 999987 1 999988 1 999989 1 99999 1 999990 1 999991 1 999992 1 999993 1 999994 1 999995 1 999996 1 999997 1 999998 1 999999 1 hello 1000000 sxt 1000000
问题1:
[2019-01-15 17:08:05.159]Container killed on request. Exit code is 143
[2019-01-15 17:08:05.182]Container exited with a non-zero exit code 143.
2019-01-15 17:08:20,957 INFO mapreduce.Job: Task Id : attempt_1547542193692_0003_m_000000_2, Status : FAILED
[2019-01-15 17:08:18.963]Container [pid=4064,containerID=container_1547542193692_0003_01_000004] is running 210352640B beyond the 'VIRTUAL' memory limit. Current usage: 26.0 MB of 1 GB physical memory used; 2.3 GB of 2.1 GB virtual memory used. Killing container.
原因:申请内存过大而被终止
解决措施:取消内存检查
配置:yarn-site.xml
<property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> <description>Whether virtual memory limits will be enforced for containers</description> </property>
问题2:
2019-01-15 18:51:11,229 INFO mapred.ClientServiceDelegate: Application state is completed. FinalApplicationStatus=SUCCEEDED. Redirecting to job history server
2019-01-15 18:51:12,237 INFO ipc.Client: Retrying connect to server: 0.0.0.0/0.0.0.0:10020. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
java.io.IOException: java.net.ConnectException: Your endpoint configuration is wrong; For more details see: http://wiki.apache.org/hadoop/UnsetHostnameOrPort
原因:由于没有启动historyserver引起的
解决办法:
在mapred-site.xml配置文件中添加
<property> <name>mapreduce.jobhistory.address</name> <value>node1:10020</value> </property>
在namenode上执行命令:mr-jobhistory-daemon.sh start historyserver
这样在,namenode上会启动JobHistoryServer服务,可以在historyserver的日志中查看运行情况
问题3:
2019-01-21 12:33:59,450 WARN hdfs.DataStreamer: Caught exception java.lang.InterruptedException at java.lang.Object.wait(Native Method) at java.lang.Thread.join(Thread.java:1245) at java.lang.Thread.join(Thread.java:1319) at org.apache.hadoop.hdfs.DataStreamer.closeResponder(DataStreamer.java:986) at org.apache.hadoop.hdfs.DataStreamer.endBlock(DataStreamer.java:640) at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:810)
这个网上有说是BUG,也有说是没有按照hadoop约定的规则创建HDFS目录,
对于上传块目录:
格式:hdfs dfs -mkdir -p /user/input
比如使用root用户登录,则创建目录应为:hdfs dfs -mkdir -p /root/input

 浙公网安备 33010602011771号
浙公网安备 33010602011771号