
作业3
gitee链接:https://gitee.com/chen-gaofei/crawl_projects/tree/master/作业3
作业①:
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
Gitee文件夹链接:https://gitee.com/chen-gaofei/crawl_projects/blob/master/作业3/image_scraper (2).zip
https://gitee.com/chen-gaofei/crawl_projects/blob/master/作业3/image_scraper duo.zip
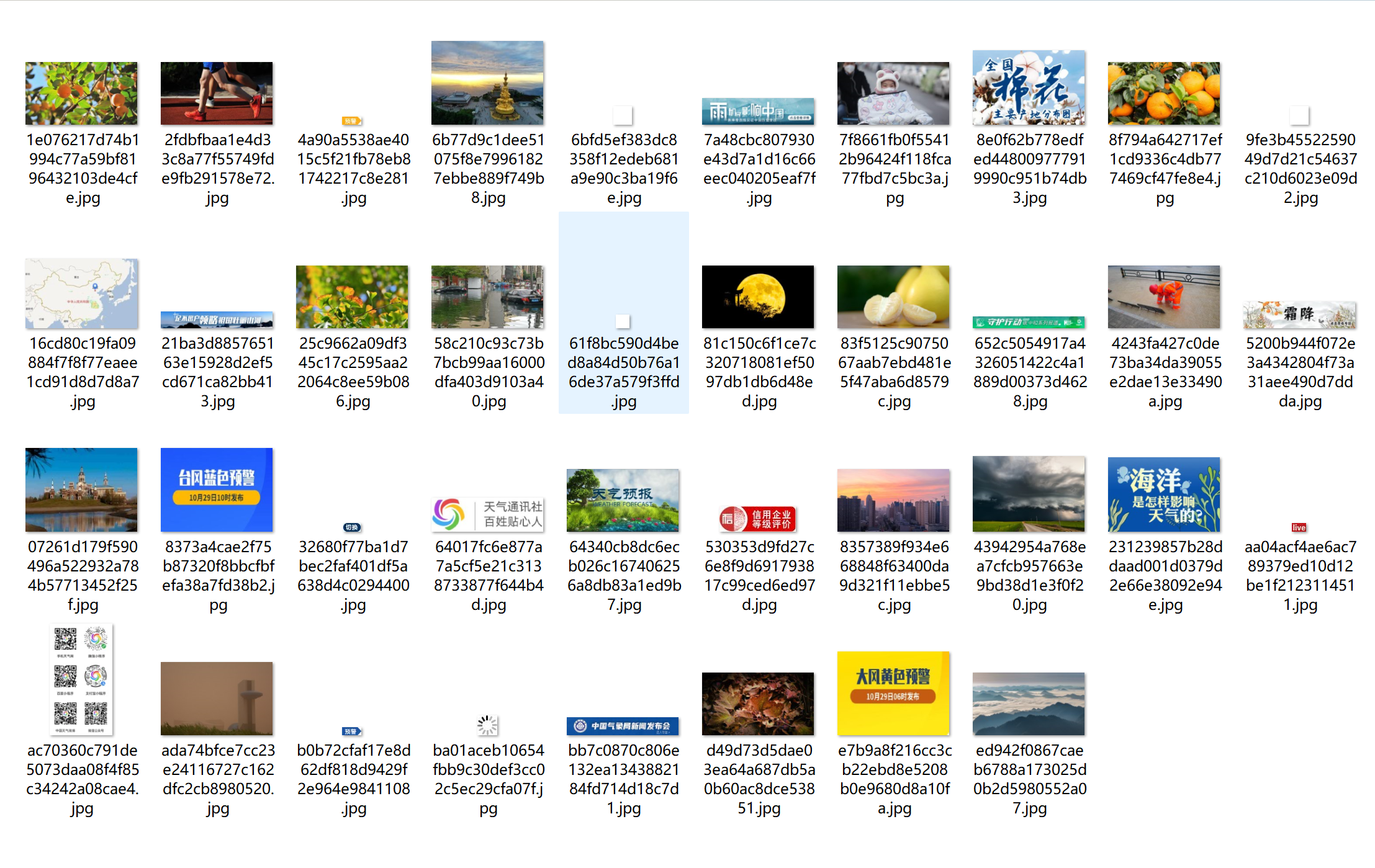
心得体会
幸好学号是01结尾不要翻页。能爬的图片太少了翻不了页。
1、精准定位图片元素:在爬取图片时,首先要明确图片元素在 HTML 页面中的具体位置,通过分析页面结构,使用适当的选择器(如 XPath 或 CSS 选择器)来定位图片的 URL。这个过程中,我学习到如何在复杂的 HTML 结构中快速找到目标元素,并确保每个选择器的准确性,这为爬取高质量的图片数据打下了基础。
2、处理图片下载与存储:图片数据的存储与普通文本不同,涉及文件格式、命名规范以及文件夹的组织结构。为避免文件名冲突和保持图片的有序管理,我在代码中加入了自动命名功能,并设计了合理的文件夹结构,确保每一张图片都能正确下载和保存。通过这一步,我认识到文件管理和命名规范在批量数据处理中的重要性。
3、异常处理与调试:在爬取图片的过程中,不可避免地会遇到一些链接失效、图片加载失败等问题。因此,我在代码中加入了异常处理机制,确保即使部分图片无法下载,爬虫依然可以顺利运行。此外,调试工具和日志记录也帮助我迅速定位并解决了多处小问题,让整个爬虫运行更加稳定。
作业②
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
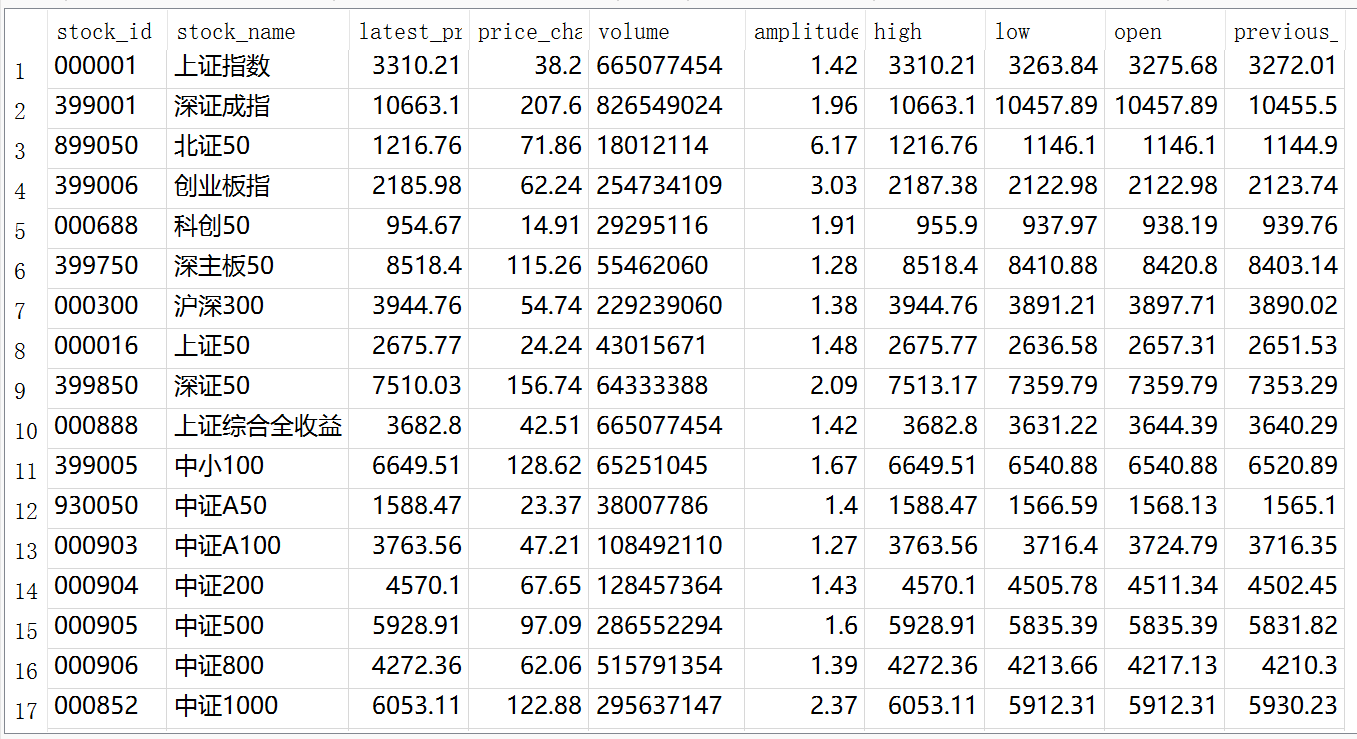
输出信息:MySQL数据库存储和输出格式如下:
表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计
Gitee文件夹链接:https://gitee.com/chen-gaofei/crawl_projects/blob/master/作业3/stock_spider.zip
心得体会
1、页面结构的深入分析:在开始编写爬虫之前,对页面结构进行分析是关键的一步。exchange_rate_scraper 目标页面包含表格形式的汇率信息,为了精准提取数据,我仔细检查了 HTML 结构,确定了各个字段的位置,选择了适合的 XPath 路径来匹配汇率数据。通过这个过程,我加深了对 XPath 选择器的理解,体会到它在复杂页面中提取数据的灵活性和高效性。
2、数据存储与字段一致性:在将数据存入 SQLite 数据库时,确保 Scrapy Item 中字段名称与数据库表结构一致,是顺利存储数据的前提。创建数据库时,提前规划字段的数据类型,并在爬取过程中保持字段数据的完整性,使数据流从网页提取到数据库存储的每一步都顺利衔接。这种一致性管理能力在爬虫开发中尤为重要。
3、处理动态内容的技术挑战:虽然汇率数据通常是静态的,但在实际开发中,我也需要关注是否存在动态加载内容的情况。在分析页面时,检查了浏览器网络请求,确认数据是否在页面加载后由 API 动态填充。这种对动态内容的关注让我进一步认识到,抓包和分析工具在爬虫开发中的重要性。
总体而言,exchange_rate_scraper 的开发让我更加深刻地理解了爬虫项目的整体流程,从分析页面到提取数据,再到数据的存储与管理。通过这一项目,我不仅提高了技术能力,也培养了细致分析、耐心调试和系统思考的能力。这段经历让我对爬虫开发充满了信心,同时也期待在未来的项目中应用和提升这些技能。
作业③:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
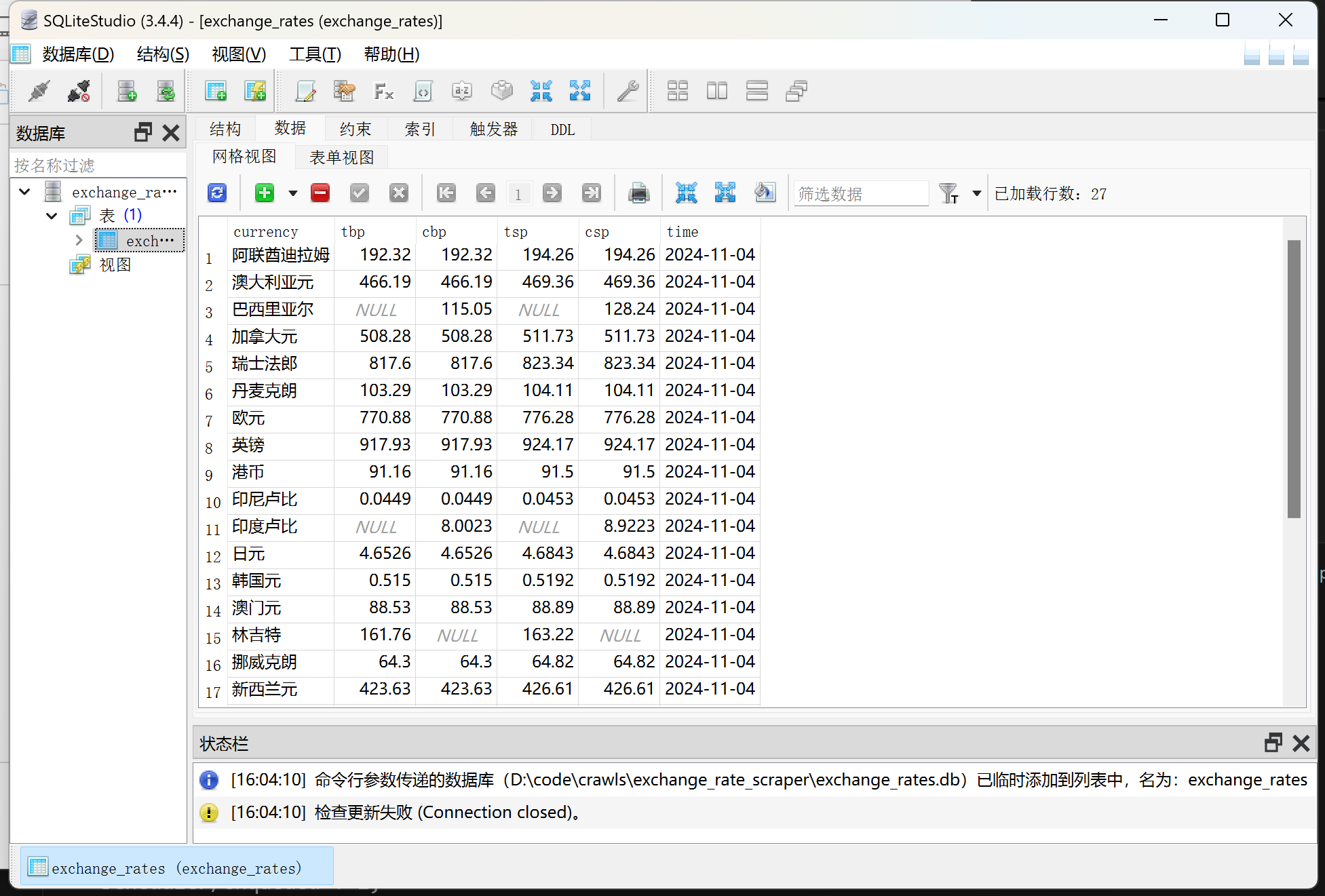
输出信息:
Gitee文件夹链接:https://gitee.com/chen-gaofei/crawl_projects/blob/master/作业3/stock_spider.zip
心得体会
1、理解数据结构和需求:在编写爬虫之前,深入理解目标数据结构和需求是非常重要的,特别是对于动态加载的网站,特别是要确保字段名称一致,这样可以避免后期出现字段不匹配的问题。
2、数据库的设计与一致性:在设计数据库时,字段名称和数据类型要与爬取的数据相匹配,否则在存储数据时会遇到错误。在 pipelines.py 中,确保 SQL 语句中的字段和数据表中的字段保持一致,这样才能顺利地将数据存储到 SQLite 数据库中。
3、调试与日志记录:调试是爬虫开发中不可避免的一部分。在运行爬虫时,Scrapy 的日志功能帮助我快速定位错误,比如字段不匹配、数据缺失等问题。善于利用日志输出信息是提升调试效率的好方法。
总的来说,stock_spider 让我加深了对 Scrapy 框架和数据存储的理解,同时提高了处理实际问题的能力。这段经历不仅帮助我积累了技术经验,也让我更加了解爬虫开发的精细与复杂。
