
数据采集第二次作业
gitee:https://gitee.com/chen-gaofei/crawl_projects
一、作业内容
(1)作业①:
要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
运行结果截图: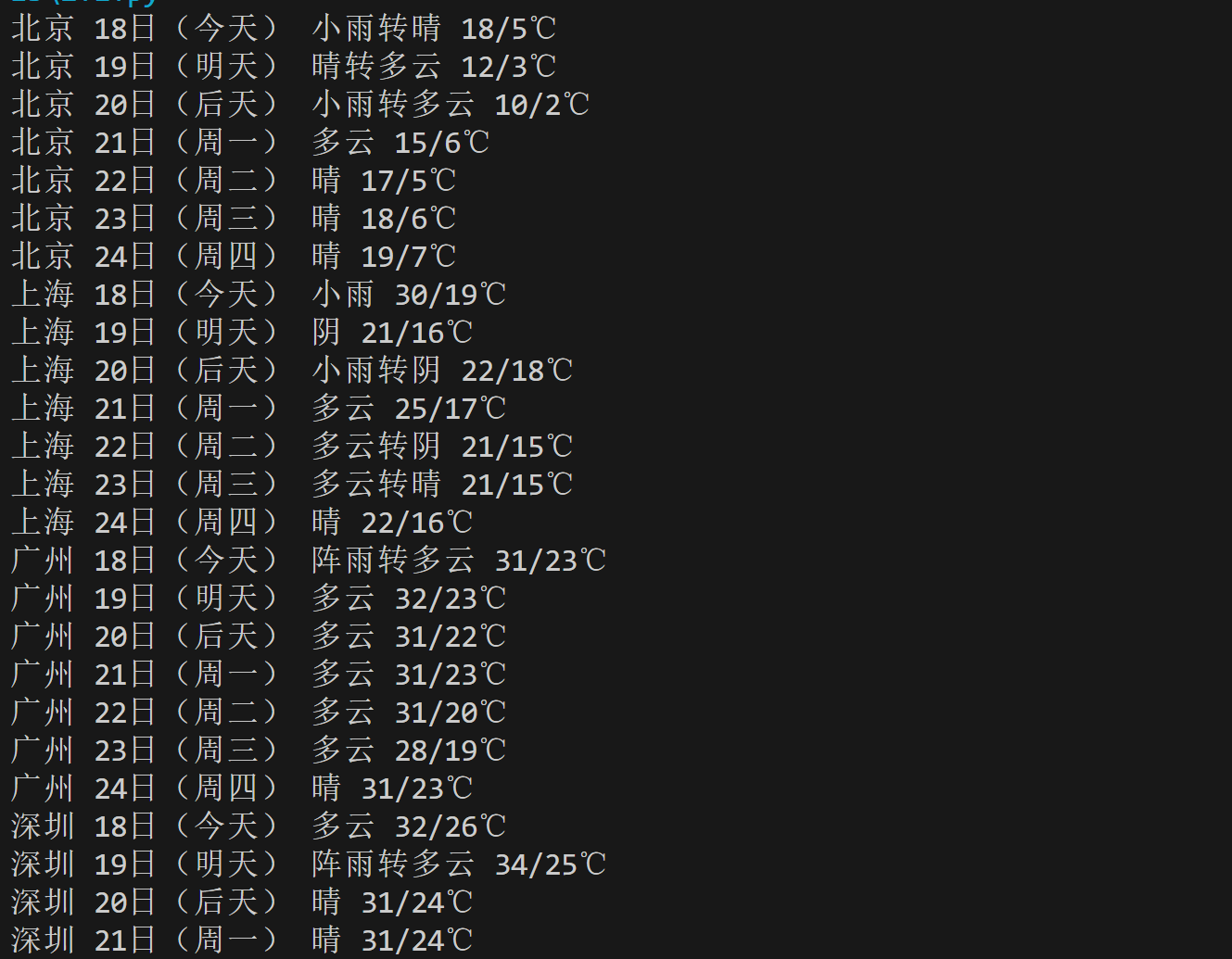
输出信息:https://gitee.com/chen-gaofei/crawl_projects/blob/master/作业2/2.1.py
(2)心得体会:
- 代码分为两个部分:存储到数据库部分和爬取数据部分。
- 数据存储到数据库部分:
- 定义 WeatherDB 类:这个类用于操作SQLite数据库,包括创建表、插入数据、显示数据等。创建一个名为 weathers 的表,包含城市、日期、天气和温度字段,并设置主键为城市和日期的组合
- 方法 insert:向 weathers 表中插入一条记录。如果插入失败,打印错误信息。
- 方法show:从 weathers 表中查询所有记录。打印表头和每条记录。
- 方法process:创建 WeatherDB 对象并打开数据库。遍历城市列表,调用 forecastCity 方法获取每个城市的天气预报信息。关闭数据库连接。
- 爬取数据部分:
- 定义 WeatherForecast 类:这个类用于获取天气预报信息。设置HTTP请求头,模拟浏览器访问。定义城市名称和对应的代码。
- 方法 forecastCity:检查城市代码是否存在。构造天气预报页面的URL。发送HTTP请求并获取页面内容。解析页面内容,提取日期、天气和温度信息。将提取的信息插入数据库。
(1)作业②
要求:用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。
候选网站:东方财富网:https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/
技巧:在谷歌浏览器中进入F12调试模式进行抓包,查找股票列表加载使用的url,并分析api返回的值,并根据所要求的参数可适当更改api的请求参数。根据URL可观察请求的参数f1、f2可获取不同的数值,根据情况可删减请求的参数。
参考链接:https://zhuanlan.zhihu.com/p/50099084
运行结果截图:

输出信息:https://gitee.com/chen-gaofei/crawl_projects/blob/master/作业2/2.2new.py
(2)心得体会:
- getData函数接收两个参数:url和gupiao(股票类型)。
- 使用requests.get发送HTTP GET请求获取数据。
- 使用正则表达式从返回的JSON数据中提取所需的信息。
- 将提取的信息存储在database列表中。
- 使用pandas将数据转换为DataFrame,并保存为Excel文件。
(1)作业③:
要求:爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
技巧:分析该网站的发包情况,分析获取数据的api
运行结果截图: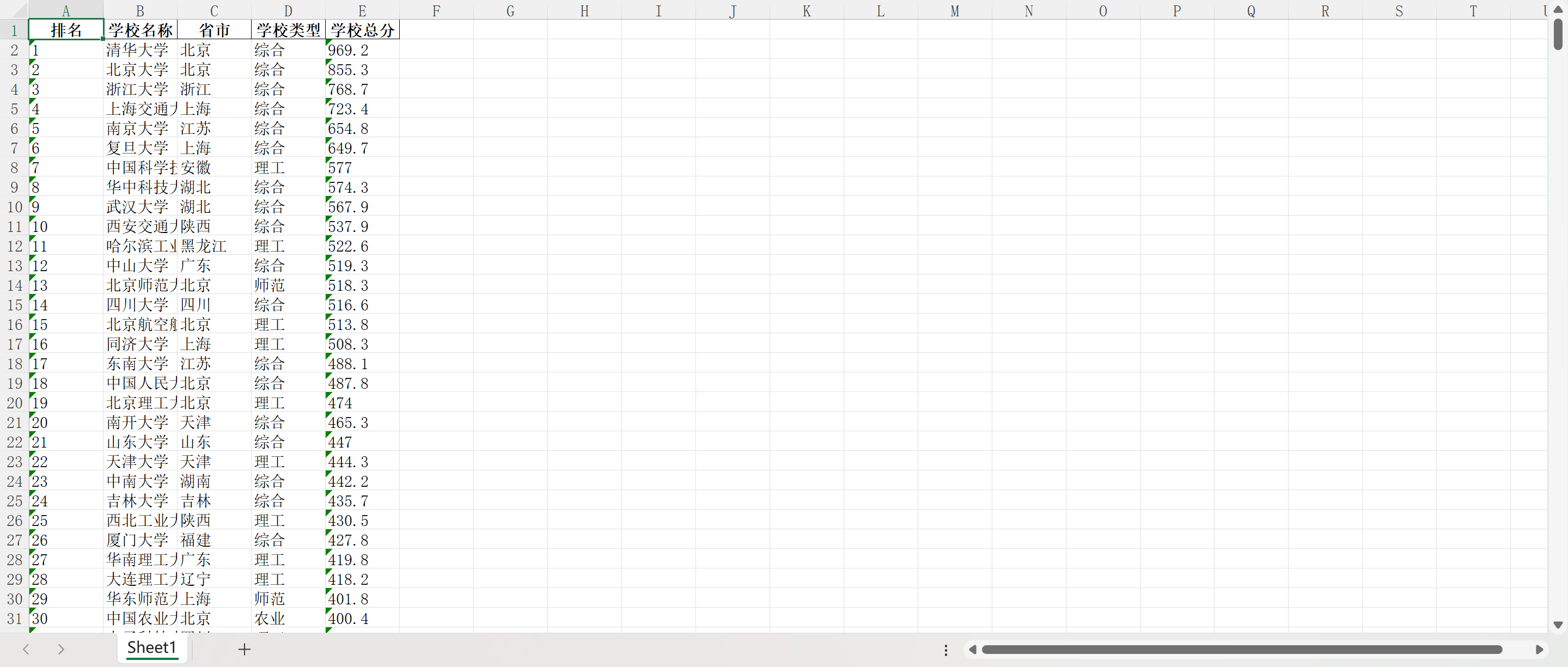
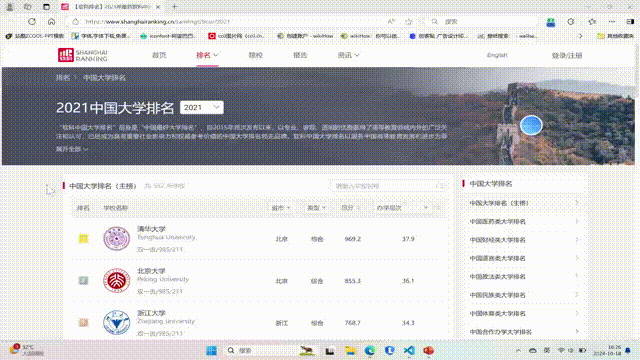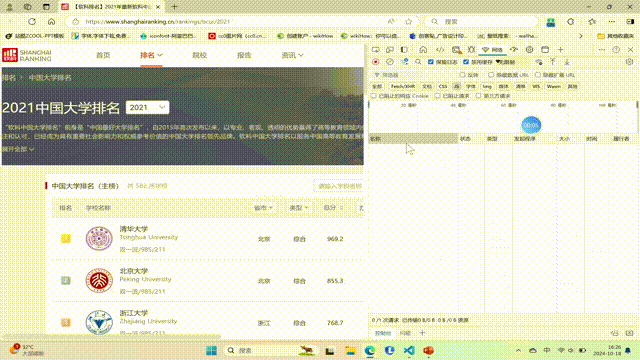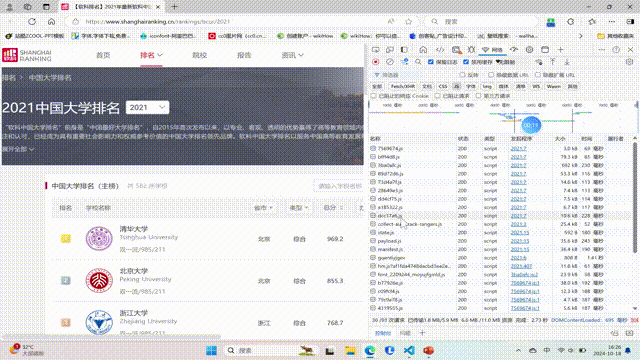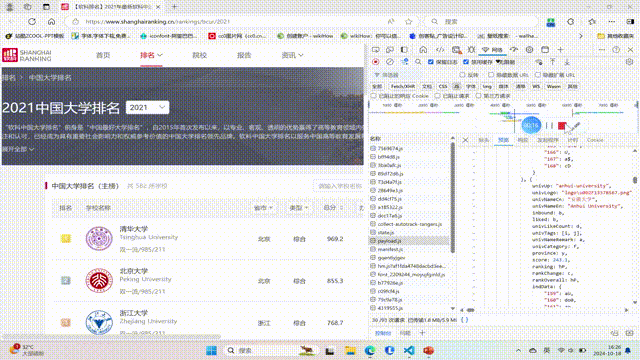
输出信息:https://gitee.com/chen-gaofei/crawl_projects/blob/master/作业2/2.3.py
(2)心得体会
- 定义省份和学校类型的映射
- 定义获取数据的函数:
- getData(url):接收一个URL参数,发送HTTP请求获取网页内容。
- 使用正则表达式从网页内容中提取大学名称、分数、省份和类型。
- 将提取的数据进行映射和整理,形成一个新的数据列表。
- 使用pandas将数据保存到Excel文件中。
- 调用函数并传入URL

