
数据采集第一次作业
作业已上传gitee:https://gitee.com/chen-gaofei/crawl_projects
作业第一题
要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020) 的数据,屏幕打印爬取的大学排名信息。
代码:https://gitee.com/chen-gaofei/crawl_projects/blob/master/作业1/.爬取大学排名.py
运行结果截图: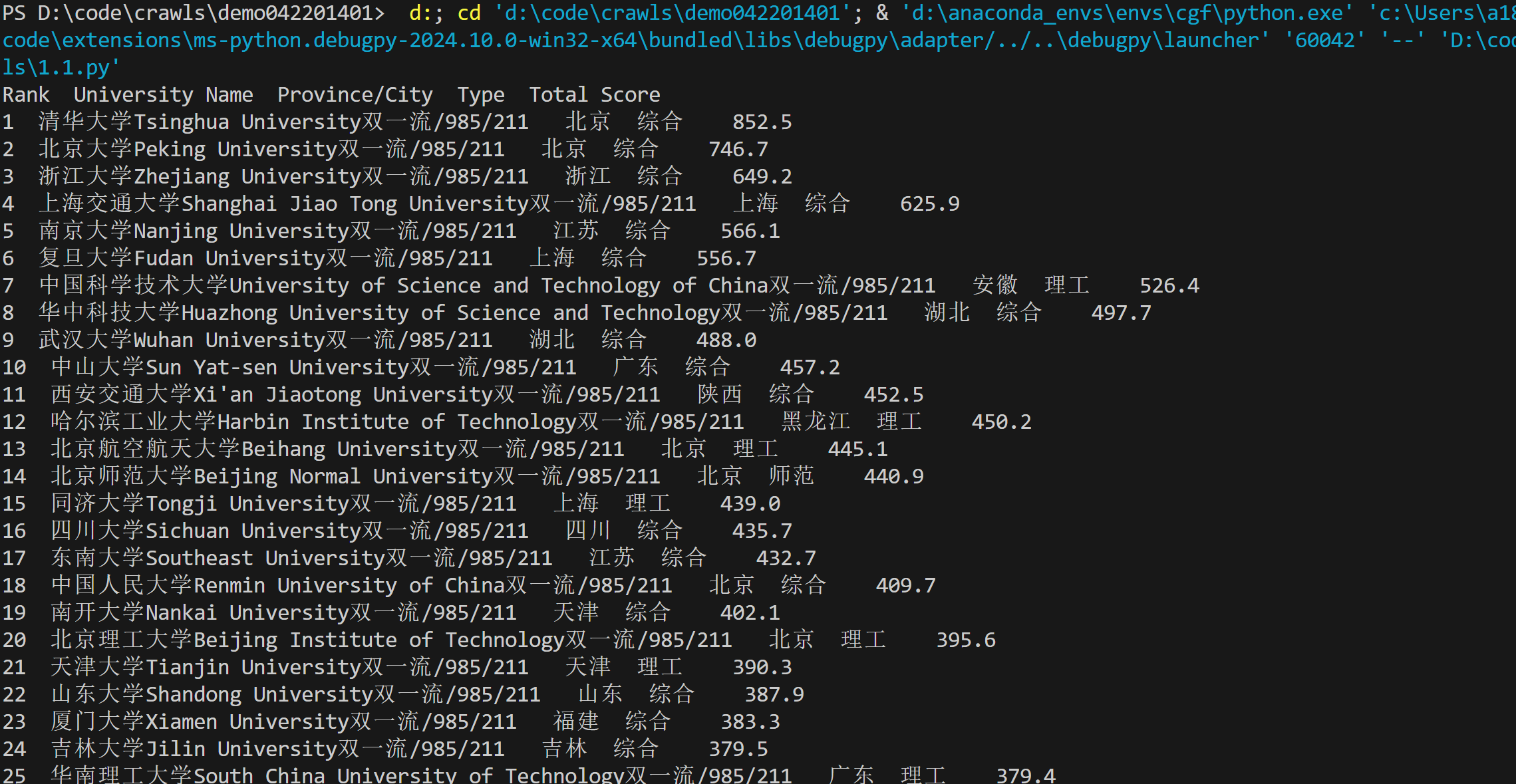
心得体会:这题是之前作业里做过的,相对简单。做这道题的过程中对html的结构有了更深刻的理解。
- 发送HTTP请求并获取网页内容:
- 使用urllib.request.urlopen(url)发送HTTP请求,并使用response.read()读取网页内容。
- 使用BeautifulSoup解析网页内容:
- 查找包含表格数据的元素:
- table = soup.find('table'):在解析后的HTML中查找第一个标签,即包含表格数据的元素。
- 获取所有表格行:
- table_rows = table.find_all('tr'):获取表格中的所有
标签,即表格的每一行。 - 遍历表格行并提取数据:
- for row in table_rows[1:]:跳过第一行(通常是表头),遍历剩余的每一行。
- columns = row.find_all('td'):获取当前行的所有
<td>标签,即单元格。 - ‘’‘rank = columns[0].get_text(strip=True)等:从每个单元格中提取文本内容,并去除多余的空格。
- 完成这个作业的过程中能更好地掌握正则表达式的运用,并且在这个过程中需要对html结构有一定了解,才能更快地完成作业。
- 设置关键词并构造搜索URL:
search_url = f"http://search.dangdang.com/?key={urllib.parse.quote(search_term)}&act=input&page_index=1" - 发送请求并获取网页响应:
req = urllib.request.Request(search_url)
resp = urllib.request.urlopen(req)
web_content = resp.read() - 使用正则表达式来匹配商品标题和价格:
regex = re.compile(r'<a[^>]*title="([^"]*)".*?<span class="price_n">([^<]+)</span>', re.S) - 这个作业主要是熟悉html中的标签及其运用。
- 定义网页URL和下载目录:
url = "https://news.fzu.edu.cn/yxfd.htm"
download_directory = "D:\code\crawls\pictures" - 创建下载目录(如果不存在)
if not os.path.exists(download_directory):
os.makedirs(download_directory) - 发送请求并获取网页内容
response = urllib.request.urlopen(url)
html_content = response.read()- 使用urllib.request发送HTTP请求,获取网页内容。
- 使用BeautifulSoup解析网页内容
soup = BeautifulSoup(html_content, 'html.parser')- 使用BeautifulSoup解析网页内容,以便进一步提取信息。
- 查找所有的
标签
`- img_tags = soup.find_all('img') - 提取所有的JPEG和JPG格式的图片链接
作业第二题
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
代码:https://gitee.com/chen-gaofei/crawl_projects/blob/master/作业1/爬取商品名称和价格.py
运行结果截图:
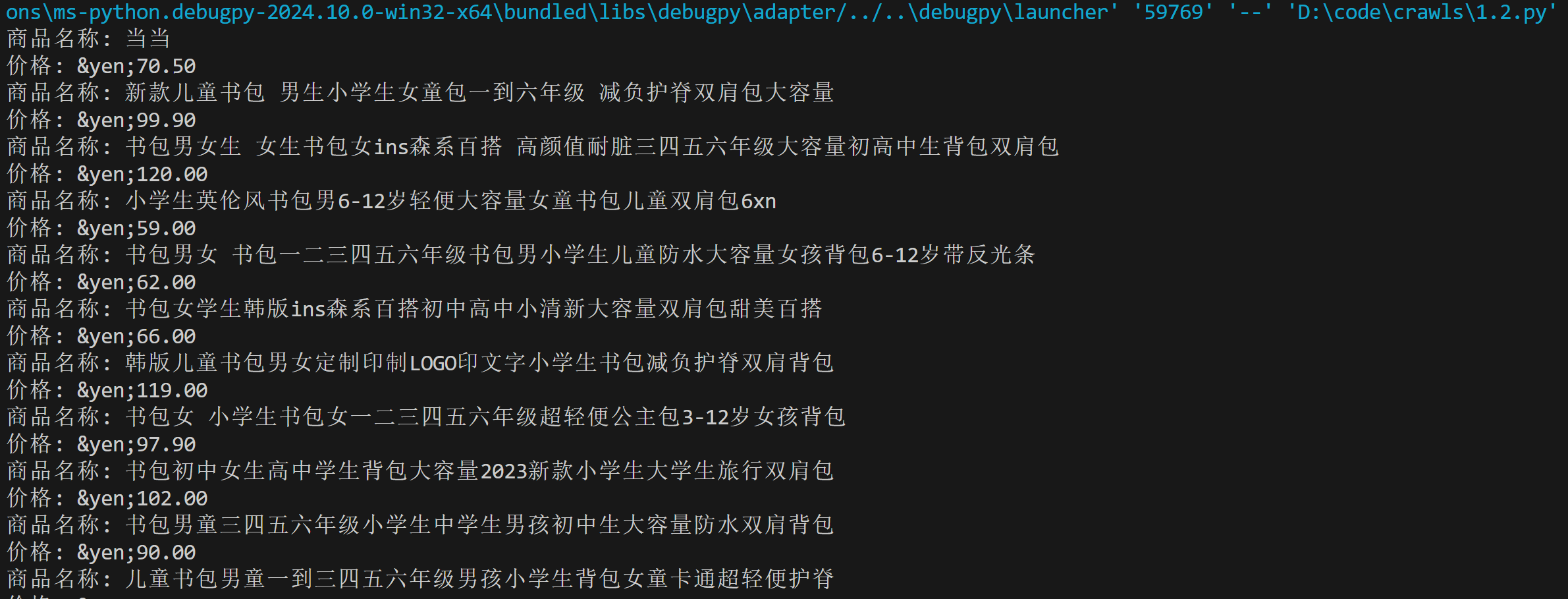
心得体会:
作业第三题
要求:爬取一个给定网页( https://news.fzu.edu.cn/yxfd.htm)或者自选网页的所有JPEG和JPG格式文件
代码:https://gitee.com/chen-gaofei/crawl_projects/blob/master/作业1/爬取指定网址指定格式图片.py
运行结果截图:
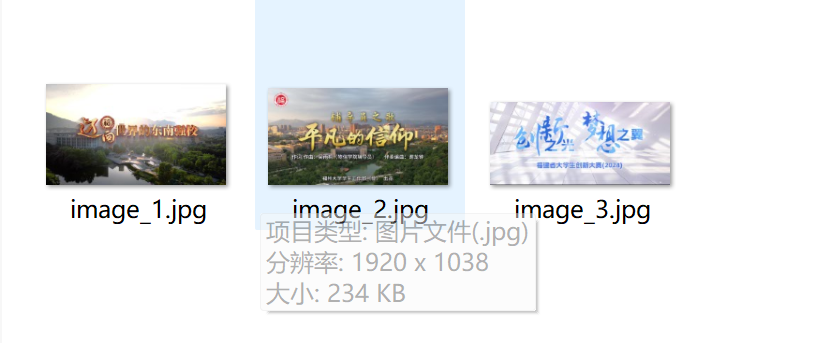
心得体会:
for img_tag in img_tags: img_url = img_tag.get('src') if img_url and (img_url.lower().endswith('.jpg') or img_url.lower().endswith('.jpeg')): if not img_url.startswith('http'): img_url = urllib.parse.urljoin(url, img_url) image_urls.append(img_url)遍历所有的
标签,提取src属性值(即图片链接)。
检查图片链接是否以.jpg或.jpeg结尾。
如果图片链接是相对路径,转换为绝对路径。
将符合条件的图片链接添加到image_urls列表中。- 下载并保存图片
img_response = requests.get(img_url) img_name = os.path.join(download_directory, f'image_{idx + 1}.jpg') with open(img_name, 'wb') as f: f.write(img_response.content) print(f"Downloaded: {img_name}")遍历image_urls列表,使用requests库发送HTTP请求,获取图片内容。
构造图片的本地文件名,并保存到指定的下载目录中。

