
运用phantomjs无头浏览器破解四种反爬虫技术
运用phantomjs无头浏览器破解四种反爬虫技术
在与反爬虫的对抗中,我们爬虫的大招有两个,其一是多种ip跟换方式(例如adsl|代理|tor等请参看之前的文章)。其二是无头浏览器,使用自动化的技术来进行自动数据抓取,模拟鼠标与键盘事件,可以用于破解验证码,js解析,诡异的模糊数据这类型的反爬虫技术。
1 phantomjs原理说明:
无头浏览器不是什么闹鬼的东西,他也称为无界面浏览器,他本身是用来做自动化测试的,不过似乎更适合用来搞爬虫。他的官方网址是:http://phantomjs.org/quick-start.html 如果想看他的中文api的话我整理了一份资料在:这里。
下载之后会得到个一个exe文件,linux下也一样。在命令行则是在该文件的目录下输入 phantomjs 就算是用该浏览器启动你的爬虫代码。
2 牛刀小试
下列js代码就是需要运行phantomg
保存为request.js文件。然后在当前目录下命令行运行:就会返回整个网页的源码,然后爬虫你懂得的小解析一下就可以抽取出xici代理的免费ip了。
/*********************************** code:javascript system:win || linux auther: luyi mail : 543429245@qq.com github: luyishisi blog: https://www.urlteam.org date:2016.9.12 逻辑说明:使用phantomjs无界面浏览器作为操作平台,破解对方针对js解析的反爬虫辨别 ************************************/ var page = require('webpage').create(), system = require('system'), address; address = system.args[1]; //init and settings page.settings.resourceTimeout = 30000 ; page.settings.XSSAuditingEnabled = true ; //page.viewportSize = { width: 1000, height: 1000 }; page.settings.userAgent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.120 Safari/537.36'; page.customHeaders = { "Connection" : "keep-alive", "Cache-Control" : "max-age=0", "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8", "Accept-Language": "zh-CN,zh;q=0.8,en;q=0.6", }; page.open(address, function() { console.log(address); console.log('begin'); }); //加载页面完毕运行 page.onLoadFinished = function(status) { console.log('Status: ' + status); console.log(page.content); phantom.exit(); };
如图:

3 破解基础的js解析能力限制
遇到过两种其一是该网站故意用js做了延迟返回真实数据,先返回一部分,之后再进行几秒的js能力验证后加载。另外一种则检测是无js处理能力当即就给出拒绝码,这类型就是xici代理的方式,如果你用python直接发送请求,无论是scrapy还是requests,都会返回500错误。如下:

但是如果你使用上面牛刀小试的代码,在python中用系统指令调用这行命令,则相当于用phantomjs来执行请求操作,源代码就会直接返回。可以用python用下列
4 破解采用display:none来随机化网页源码
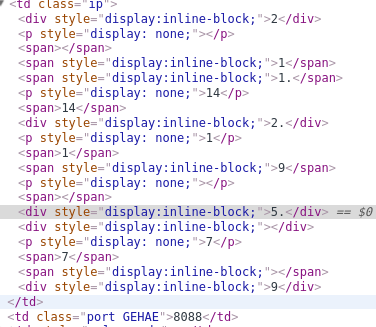
总所周知,我们在爬虫中想要选出某个需要的数据,可以使用xpath或者正则这类字符串的操作,然而必然需要对方的网站有一定规律,才能合理的抽出数据,因此也有使用nodisplay这个属性,让显示的后台代码十分混乱,但是前台呈现给用户的数据并不会混乱比如:http://proxy.goubanjia.com/
如图,我使用chrome来检测这ip部分的源代码的时候就会出现后台乱七八糟的显示情况,有网站还会随机类的名字,让更加不好捕捉。
然后破解方式也曲线救国。
破解思路:(避免查水表不发布源代码)
使用phantomjs的截图功能。(具体查官方api。并不困难,其样例代码中rasterize.js 这一篇也是实现截图的功能)例如:
page.evaluate(function() { document.body.bgColor = 'white';});//背景色设定为白。方便二值化处理 page.clipRect = { top: 441, left: 364, width: 300, height: 210 };//指定截图区域。坐标使用第四象限
然后单独取出ip和port部分的图片。使用python进行图文转换。大致如下:
- 安装PIL中image库
- 遍历每一个像素点,做一个锐化加强对比去除杂色和二值化,保存改良过的图片。
- 调用pytesseract 运行函数:print pytesseract.image_to_string(Image.open(‘end.png’))
- 如果你的图像处理的比较清晰就可以轻松识别出图文。
注意好切割图片,不要整个图片一次性的识别,最好能单独切出一个ip。然后进行识别,准确性高。主要的难度其实是安装环境和图片优化比较麻烦。
5 破解简单的图片文字相互替代
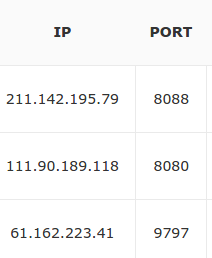
这部分和上个问题也相当重合:相当于是对方把一些数据变成图片,而我们则是下载这些图片然后进行图片优化,然后解析比如:http://ip.zdaye.com/
当抓取他的页面的时候,ip好抓,但是端口号是图片的。下载图片之后还是需要做好上诉转换。识别起来准确性也是95%+
这方面给三个传送门自行学习:
- 简单数字去噪二值化识别:http://www.verydemo.com/demo_c122_i2907.html
- 验证码破解原理:http://udn.yyuap.com/doc/ae/920457.html
- 机器学习式破解:https://www.91ri.org/13043.html
6 破解拖动验证码
破解只是兴趣而已,总不能砸别人饭碗。只是提一下思路:
- 截取触发前后的验证码图片。运用变化点作为二值化可以得出需要偏移的像素点
- phantomjs控制鼠标进行拖动
- 唯一困难的就是拖动的轨迹不能是太机器化,否则你的验证码会被吃掉。
- 还有别人使用ajax等跳过请求,也是一种方式不过也挺难的。
- 请勿私信问代码。没留。

7 总结:
与反爬虫进行斗争,如果你能熟练使用上诉的技巧就基本无往而不利了。
使用adsl | tor | 代理 | 可以让对方无法针对ip封禁,使用header的字段伪造,算是入门防止对方识别并返回假数据。使用phantoms则基本对方不能阻止你的访问。毕竟是真实的浏览器发起的请求。现在还能存在的漏洞就是可以通过一些特性检测识别出你使用的是phantoms浏览器然后阻止,能实现这个的网站也不多。另外还有困难的就是复杂的验证码破解的,只有机器学习一条路了。
本文仅作技术分享,不公布破解源代码,希望读者可以互相学习,增长技艺。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号