
财政收入影响因素分析及预测
#描述性统计分析和相关系数矩阵
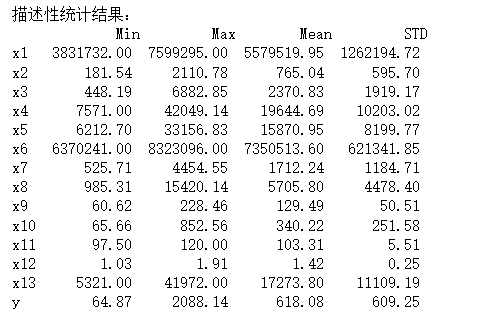
import pandas as pd import numpy as np inputfile='D:\大三下\大数据实验课\demo\data.csv'#输入数据的文件 data=pd.read_csv(inputfile)#读取数据 description=[data.min(),data.max(),data.mean(),data.std()] description=pd.DataFrame(description,index=['Min','Max','Mean','STD']).T#对变量取名字 print('描述性统计结果:\n',np.round(description,2))#保留两位小数
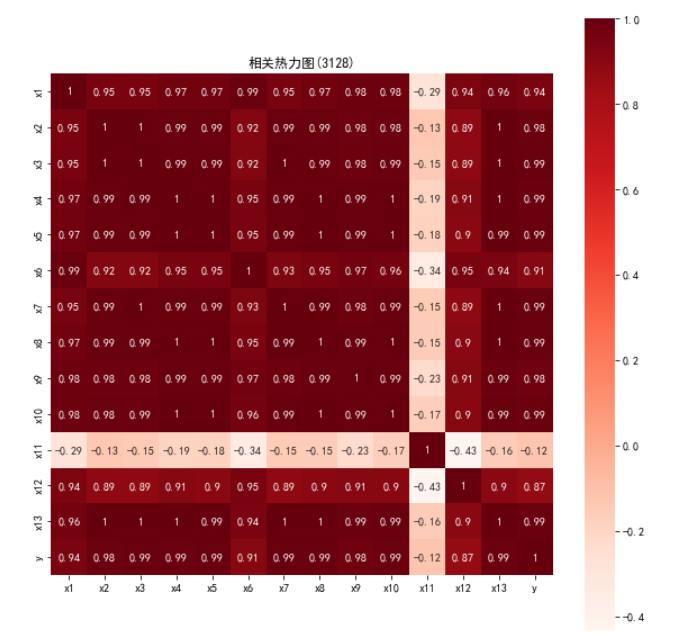
corr=data.corr(method='pearson')
print('相关系数矩阵为:\n',np.round(corr,2))

#相关性热力图
import matplotlib.pyplot as plt
import seaborn as sns
plt.subplots(figsize=(10,10))#设置画布大小
sns.heatmap(corr,annot=True,vmax=1,square=True,cmap='Reds')
plt.title('相关热力图(3128)')
plt.show()
plt.close
#读取相关系数数据
import numpy as np import pandas as pd from sklearn.linear_model import Lasso inputfile='D:\大三下\大数据实验课\demo\data.csv'#输入数据的文件 lasso=Lasso(1000)#调节Lass()函数,设置λ的值为1000 data=pd.read_csv(inputfile)#读取数据 lasso.fit(data.iloc[:,0:13],data['y']) print('相关系数:',np.round(lasso.coef_,5))#输出结果,保留五位小数 print('相关系数非零个数为:',np.sum(lasso.coef_!=0))#计算相关系数非零的个数 mask=lasso.coef_!=0#返回一个相关系数是否为零的布尔数组 mask=np.append(mask,True)#将mask的数补齐到14个(补充) print('相关系数是否为零:',mask) outputfile='D:\大三下\大数据实验课\demo\new_reg_data23.csv'#输出的数据文件 new_reg_data=data.iloc[:,mask]#返回相关系数非零的数据 #new_reg_data.to_csv(outputfile)#存储数据 print('输出数据的维度为:',new_reg_data.shape)#查看输出数据的维度

#灰色预测
import sys
sys.path.append('D:\大三下\大数据实验课\demo\code')#设置路径
##import numpy as np
##import pandas as pd
from GM11 import GM11 #引入自编的灰色预测模型
inputfile1='D:\\大三下\\大数据实验课\\demo\\new_reg_data23.csv'#导入数据的文件(地址:\\或/)
inputfile2='D:\\大三下\\大数据实验课\\demo\\data.csv'#导入数据的文件
new_reg_data=pd.read_csv(inputfile1)#读取经过属性选择后的数据
data=pd.read_csv(inputfile2)#读取总的数据
new_reg_data.index=range(1994,2014)#
new_reg_data.loc[2014]=None
new_reg_data.loc[2015]=None
cols=['x1','x3','x4','x5','x6','x7','x8','x13']
for i in cols:
f=GM11(new_reg_data.loc[range(1994,2014),i].values)[0]
new_reg_data.loc[2014,i]=f(len(new_reg_data)-1)#2014年预测结果
new_reg_data.loc[2015,i]=f(len(new_reg_data))#2015年预测结果
new_reg_data[i]=new_reg_data[i].round(2)#保留2位小数
outputfile='D:\\大三下\\大数据实验课\\demo\\new_reg_data_GM11.xls'#灰色预测后保存的路径
y=list(data['y'].values)#提取财政收入列,合并至新数据框中
y.extend([np.nan,np.nan])
new_reg_data['y']=y
new_reg_data.to_excel(outputfile)#结果输出
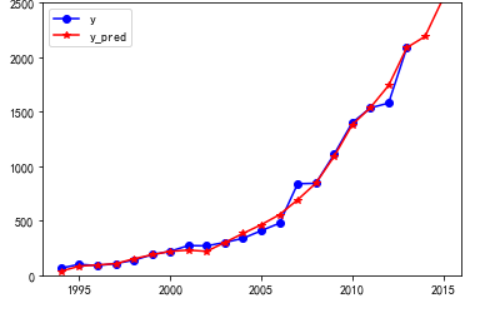
print('预测结果为:\n',new_reg_data.loc[2014:2015,:])#预测展示

#6-5 灰色预测
import sys
sys.path.append('D:\大三下\大数据实验课\demo\code')#设置路径
import numpy as np
import pandas as pd
from GM11 import GM11 #引入自编的灰色预测模型
inputfile1='D:\\大三下\\大数据实验课\\demo\\new_reg_data23.csv'#导入数据的文件(地址:\\或/)
inputfile2='D:\\大三下\\大数据实验课\\demo\\data.csv'#导入数据的文件
new_reg_data=pd.read_csv(inputfile1)#读取经过属性选择后的数据
data=pd.read_csv(inputfile2)#读取总的数据
new_reg_data.index=range(1994,2014)#
new_reg_data.loc[2014]=None
new_reg_data.loc[2015]=None
cols=['x1','x3','x4','x5','x6','x7','x8','x13']
for i in cols:
f=GM11(new_reg_data.loc[range(1994,2014),i].values)[0]
new_reg_data.loc[2014,i]=f(len(new_reg_data)-1)#2014年预测结果
new_reg_data.loc[2015,i]=f(len(new_reg_data))#2015年预测结果
new_reg_data[i]=new_reg_data[i].round(2)#保留2位小数
outputfile='D:\\大三下\\大数据实验课\\demo\\new_reg_data_GM11.xls'#灰色预测后保存的路径
y=list(data['y'].values)#提取财政收入列,合并至新数据框中
y.extend([np.nan,np.nan])
new_reg_data['y']=y
new_reg_data.to_excel(outputfile)#结果输出
print('预测结果为:\n',new_reg_data.loc[2014:2015,:])#预测展示
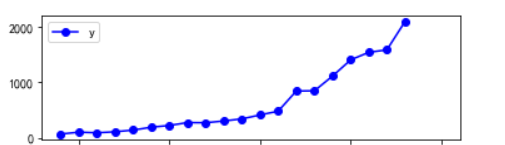
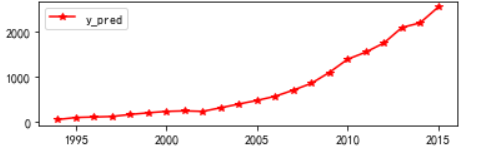
import matplotlib.pyplot as plt p = data[['y', 'y_pred']].plot(style=['b-o', 'r-*']) p.set_ylim(0, 2500) p.set_xlim(1993, 2016) plt.rcParams['font.sans-serif'] = ['SimHei'] # 添加这条可以让图形显示中文 plt.show()
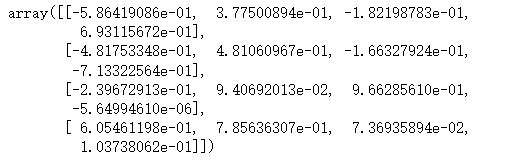
import numpy as np from sklearn.decomposition import PCA D = np.random.rand(10,4) pca = PCA() pca.fit(D) PCA(copy=True,n_components=None,whiten=False) pca.components_ #返回模型的各个特征向量
pca.explained_variance_ratio_ #返回各个成分各自的方差百分比
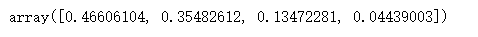
import numpy as np
import random
import matplotlib.pyplot as plt
def distance(point1, point2): # 计算距离(欧几里得距离)
return np.sqrt(np.sum((point1 - point2) ** 2))
def k_means(data, k, max_iter=10000):
centers = {} # 初始聚类中心
# 初始化,随机选k个样本作为初始聚类中心。 random.sample(): 随机不重复抽取k个值
n_data = data.shape[0] # 样本个数
for idx, i in enumerate(random.sample(range(n_data), k)):
# idx取值范围[0, k-1],代表第几个聚类中心; data[i]为随机选取的样本作为聚类中心
centers[idx] = data[i]
# 开始迭代
for i in range(max_iter): # 迭代次数
print("开始第{}次迭代".format(i+1))
clusters = {} # 聚类结果,聚类中心的索引idx -> [样本集合]
for j in range(k): # 初始化为空列表
clusters[j] = []
for sample in data: # 遍历每个样本
distances = [] # 计算该样本到每个聚类中心的距离 (只会有k个元素)
for c in centers: # 遍历每个聚类中心
# 添加该样本点到聚类中心的距离
distances.append(distance(sample, centers[c]))
idx = np.argmin(distances) # 最小距离的索引
clusters[idx].append(sample) # 将该样本添加到第idx个聚类中心
pre_centers = centers.copy() # 记录之前的聚类中心点
for c in clusters.keys():
# 重新计算中心点(计算该聚类中心的所有样本的均值)
centers[c] = np.mean(clusters[c], axis=0)
is_convergent = True
for c in centers:
if distance(pre_centers[c], centers[c]) > 1e-8: # 中心点是否变化
is_convergent = False
break
if is_convergent == True:
# 如果新旧聚类中心不变,则迭代停止
break
return centers, clusters
def predict(p_data, centers): # 预测新样本点所在的类
# 计算p_data 到每个聚类中心的距离,然后返回距离最小所在的聚类。
distances = [distance(p_data, centers[c]) for c in centers]
return np.argmin(distances)
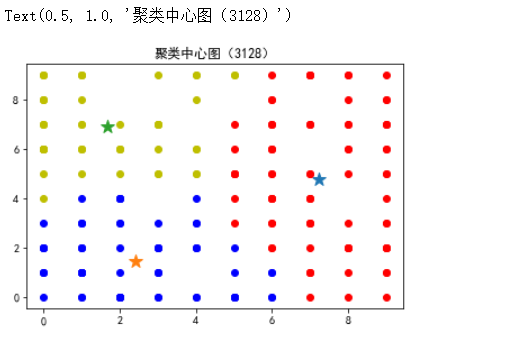
x = np.random.randint(0,high=10,size=(200,2))
centers,clusters = k_means(x,3)

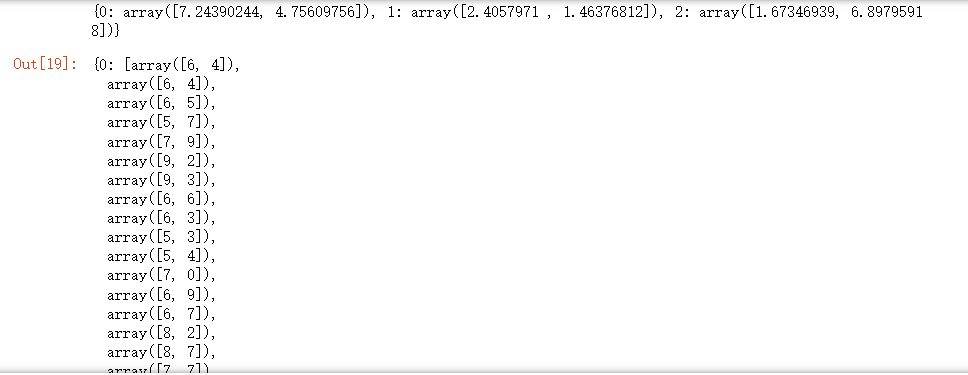
print(centers)
clusters
for center in centers:
plt.scatter(centers[center][0],centers[center][1],marker='*',s=150)
colors = ['r','b','y','m','c','g']
for c in clusters:
for point in clusters[c]:
plt.scatter(point[0],point[1],c = colors[c])
plt.rcParams['font.sans-serif'] = ['SimHei'] # 添加这条可以让图形显示中文
plt.title('聚类中心图(3128)')
import matplotlib.pyplot as plt
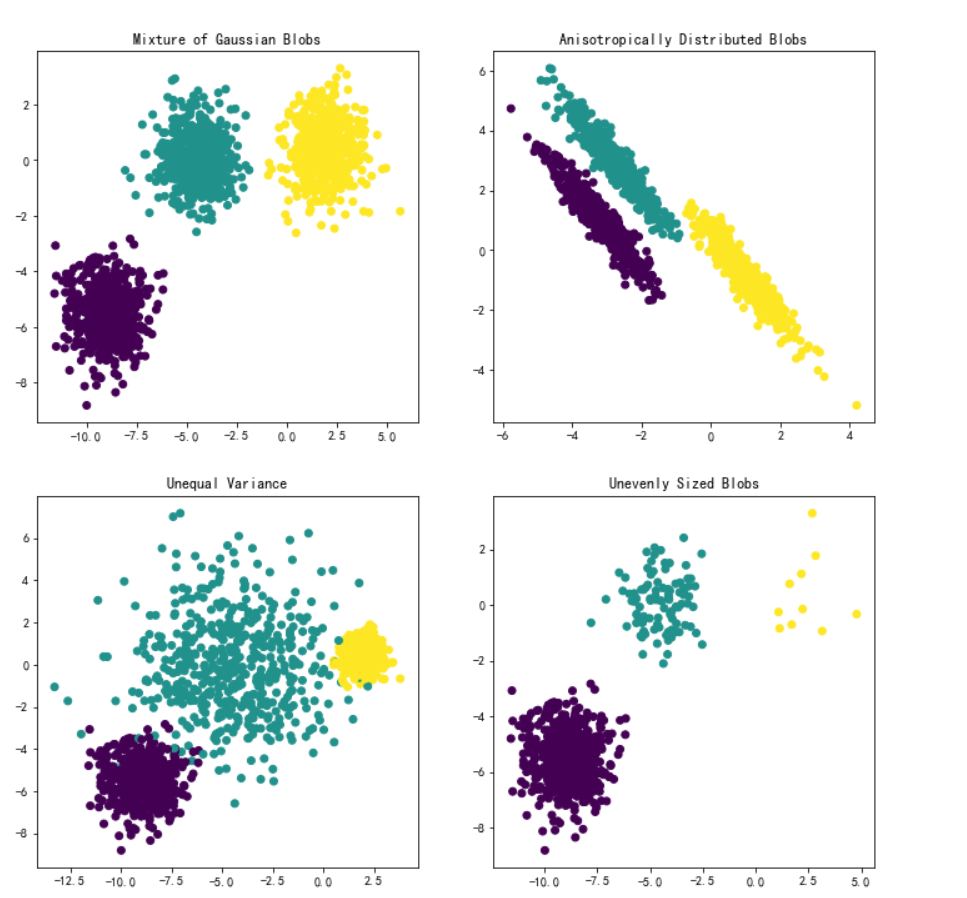
fig, axs = plt.subplots(nrows=2, ncols=2, figsize=(12, 12))
axs[0, 0].scatter(X[:, 0], X[:, 1], c=y)
axs[0, 0].set_title("Mixture of Gaussian Blobs")
axs[0, 1].scatter(X_aniso[:, 0], X_aniso[:, 1], c=y)
axs[0, 1].set_title("Anisotropically Distributed Blobs")
axs[1, 0].scatter(X_varied[:, 0], X_varied[:, 1], c=y_varied)
axs[1, 0].set_title("Unequal Variance")
axs[1, 1].scatter(X_filtered[:, 0], X_filtered[:, 1], c=y_filtered)
axs[1, 1].set_title("Unevenly Sized Blobs")
plt.rcParams['axes.unicode_minus'] = False # 添加这条可以让图形显示负号
plt.rcParams['font.sans-serif'] = ['SimHei'] # 添加这条可以让图形显示中文
plt.suptitle("Ground truth clusters(3128)").set_y(0.95)
plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号