
Sharding-jdbc(一)分库分表理解
1、什么是分库分表
所谓的分库分表就是数据的分片(Sharding)。
2、为什么需要分库分表
因为随着公司的业务越来越大,对于现成单机单个应用瓶颈问题,对数据持久化硬盘如何进行扩容。
可以从4个方面就行考虑:
1、表的设计要符合业务需求
2、sql语句的优化
3、读写分离
4、分库分表
3、什么是读写分离
将操作的sql语句到指定的库中操作,达到读写分开操作不同的数据库。
数据库的角色:主库(master,就是写库),从库(slave,就是读库)。
读写分离对insert、update、delete语句的操作走主库,select语句走从库,(所谓的crud操作)
应用:对于读多写少业务对从库的压力比较大,对于写多读少业务对主库压力比较大。
读写分离java开源框架分类:
客户端(应用层):TDDL、Sharding-jdbc
这里讲解Sharding-jdbc:
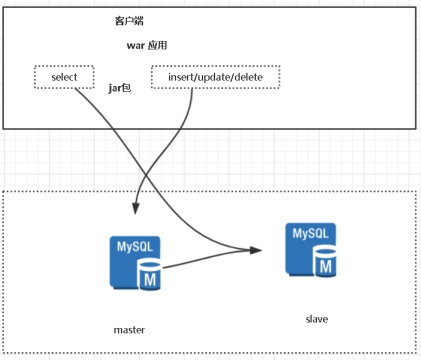
特点:
优点:1、程序自动完成,数据源方便管理;2、不需要维护、因为没有中间件;3、理论支持任何数据库(sql标准)
缺点:1、存在代码入侵性;2、加大开发成本;3、不能做到动态添加数据源,添加数据源还需要重启程序;4、程序开发完后,运维人员参与不了
中间件(代理层 proxy):mysql proxy、mycat、altas(360开发的)

特点:
优点:1、数据添加不会影响到程序;2、应用层不需管理数据库层方面,由代理层去管理;3、添加数据源不需要重启程序
缺点:1、程序依赖的中间件,提高维护工作;2、容易出现高可用问题;3、中间件导致切换数据库变的困难;2、增加了proxy,程序性能下降
4、什么是分库分表
分库分表其实是基于读写分离上面提出的方案(也就是目前关系型数据库终极解决方案)。
读写分离:当数据写很大的时候,(例如:双十一 天猫、京东下单时写的数据很大)master写的压力大的问题以及公司随着业务增大之后产生瓶颈问题,需要数据分片来解决。
分库分表:目前数据库终极解决方案:解决高并发、数据分片。
分库(表)类型:
垂直:
将一个比较多字段的表拆分成多个小表,将不同字段放到不同的小表中,降低单表(单库)大小的目的来提高性能。
通俗:大表拆小表,拆分是基于关系型数据库表的列(字段)来进行。
特点:每个表(库)的结构都不一样
每个表(库)的列数据至少有一列是一样的
每个表(库)并集是整个数据库的全量数据
每个表(库)数据量一样(不会变):例如(user-info字段 + user-basse字段 = user的全字段)
水平:
某个字段按照一定规律进行拆分,将一个表的数据分到多个表(库)中。
降低表的数据量,优化查询数据量的方式来提高性能。例如:(user1(数据) + user2 (数据) = user全部数据)
特点:每个表(库)的结构一样
每个表(库)数据量不一样。(要是一样只能说太恰好了,但是不可以存在一样的数据)
每个表(库)的并集是整个数据库(表)全量数据。
5、分库分表常见的算法:
1、Hash(取模):通过表的一列字段进行hash取出code值来区分的。
2、Range(范围):按年份、按时间、按某值等。
3、List预定义:事先定于好。
6、分库分表之后带来什么问题
1、查询数据结果集合需要查询多个库,比较麻烦。
2、sql语句需要修改,将之前没分库分表的语句需要重新修改,比较麻烦。
3、分布式事务
4、全局唯一性id,之前哪些只增的id都不管用,水平拆分后的表,多个表之间的id不能使用自增,需要一个唯一全局id。
7、如何设计一个永远都不需要迁移的方案?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号