流畅的python笔记
1.Python 对象的一个基本要求就是它得有合理的字符串表示形式,我们可
以通过 __repr__ 和 __str__ 来满足这个要求。前者方便我们调试和
记录日志,后者则是给终端用户看的。这就是数据模型中存在特殊方法
__repr__ 和 __str__ 的原因。
2.容器序列 list、tuple 和 collections.deque 这些序列能存放不同类型的数据。扁平序列str、bytes、bytearray、memoryview 和 array.array,这类序列只能容纳一种类型。
3.在进行拆包的时候,我们不总是对元组里所有的数据都感兴趣,_ 占位符能帮助处理这种情况
import os
#利用元组拆包获取文件名
#有不想要的信息用_表示如下
path="/home/cxa/.ssh/idersa.pub"
#通过元组拆包获取文件名
_,filename=os.path.split(path)
print(filename)
import os
a, b, *rest = range(5)
print(a,b,rest)
4具名元组,元组的一个功能,记录
#!/usr/bin/env python
# encoding: utf-8
from collections import namedtuple
#具名元组
# 创建一个具名元组需要两个参数,一个是类名,另一个是类的各个
# 字段的名字。后者可以是由数个字符串组成的可迭代对象,或者是由空
# 格分隔开的字段名组成的字符串。
City=namedtuple('City', 'name country population coordinates')
#上面的nametuple的第二个参数有四个空格 所以需要四个参数
tokyo=City("tokyo","JP","39.933","おはようございます")
print(City._fields) #_fields输出有哪些参数名
LatLong = namedtuple('LatLong', 'lat long')
delhi_data=('Delhi NCR', 'IN', 21.935, LatLong(28.613889, 77.208889))
#_make类似元组拆包赋值
delhi=City._make(delhi_data) #
print(delhi)
# OrderedDict([('name', 'Delhi NCR'), ('country', 'IN'), ('population',
# 21.935), ('coordinates', LatLong(lat=28.613889, long=77.208889))])
for key, value in delhi._asdict().items():
print(key + ':', value)
5.format
A.^是什么意思
这种用法属于Python的格式化输出字符:
-
{0:^30}中的0是一个序号,表示格式化输出的第0个字符,依次累加;
-
{0:^30}中的30表示输出宽度约束为30个字符;
-
{0:^30}中的^表示输出时右对齐,若宽度小于字符串的实际宽度,以实际宽度输出;
-
例如:
# -*- coding: cp936 -*-##{0}对应于"age",^右对齐输出##{1}对应于"name",左对齐输出(默认)print("{0:^30}\n{1:^30}\n{1:10}".format("age","name")
B:
format()格式化输出参数有很多,
格式:{0}{1}{2} 对应的三个值分别是:x 、x*x、x*x*x
{0:2d} {1:3d} {2:4d}是什么意思呢
{0:2d} 是说以十进制来显示x,长度为2(长度不足2则用空格补,如x=3则显示为“ 3”)
6.使用* 建立由列表组成的列表
#!/usr/bin/env python
# encoding: utf-8
#board = [['_'] * 3] * 3 含有 3 个指向同一对象的引用的列表是毫无用处的
board = [['_'] * 3 for i in range(3)]
board[1][2] = 'X'
print(board)
7.序列的增量赋值 +=,*=
+= ,实现了 __iadd__ 方法,调用这个方法,对于可变序列来说 拼接元素,不会新开辟空间,++ 就不一样了
比如:a=a+b,首先计算 a +b,得到一个新的对象,然后赋值给 a.
对不可变序列进行重复拼接操作的话,效率会很低,因为每次都有一个
新对象,而解释器需要把原来对象中的元素先复制到新的对象里,然后
再追加新的元素。
注意:str 是一个例外,因为对字符串做 += 实在是太普遍了,所以 CPython 对它做了优化。为 str
初始化内存的时候,程序会为它留出额外的可扩展空间,因此进行增量操作的时候,并不会涉
及复制原有字符串到新位置这类操作。
8.一个关于+=的谜题
在交互式窗口下运行
t = (1, 2, [30, 40])
t[2] += [50, 60]
a. t 变成 (1, 2, [30, 40, 50, 60])。
b. 因为 tuple 不支持对它的元素赋值,所以会抛出 TypeError 异常。
c. 以上两个都不是。
d. a 和 b 都是对的。
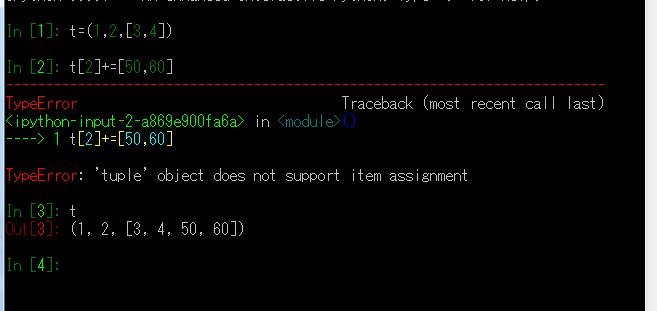
如果写成 t[2].extend([50, 60]) 就能避免这个异常。
#作者说
这其实是个非常罕见的边界情况,在 15 年的 Python 生涯中,我还没见
过谁在这个地方吃过亏。
至此我得到了 3 个教训。
【1】不要把可变对象放在元组里面。
【2】增量赋值不是一个原子操作。我们刚才也看到了,它虽然抛出了异
常,但还是完成了操作。
【3】查看 Python 的字节码并不难,而且它对我们了解代码背后的运行机
制很有帮助。
9.操作字典的时候当键值不存在的时候怎么做
# from datetime import datetime
# class getdefault(dict):
# def __getitem__(self, item):
# self[item] = datetime.now()
# return datetime.now()
# def __missing__(self, key):
# self[key]=datetime.now()
# return datetime.now()
#
# dicts= getdefault()
# print(dicts["update-date"])
'''
为什么 isinstance(key, str) 测试在下面的
__missing__ 中是必需的。
如果没有这个测试,只要 str(k) 返回的是一个存在的键,那么
__missing__ 方法是没问题的,不管是字符串键还是非字符串键,它
都能正常运行。但是如果 str(k) 不是一个存在的键,代码就会陷入无
限递归。这是因为 __missing__ 的最后一行中的 self[str(key)] 会
调用 __getitem__,而这个 str(key) 又不存在,于是 __missing__
又会被调用。
StrKeyDict0 在查询的时候把非字符串的键转换为字符
串
'''
class StrKeyDict0(dict): #StrKeyDict0继承了dict
def __missing__(self, key):
if isinstance(key, str):
raise KeyError(key)#如果找不到的键本身就是字符串,那就抛出 KeyError 异常。
return self[str(key)]
def get(self, key, default=None):
try:
return self[key] #get方法把查找工作用 self[key] 的形式委托给 __getitem__,这样在宣布查找失败之前,还能通过 __missing__ 再给某个键一个机会。
except KeyError:
return default #如果抛出 KeyError,那么说明 __missing__ 也失败了,于是返回default。
def __contains__(self, key):
#先按照传入键的原本的值来查找(我们的映射类型中可能含有非字符串的键),
# 如果没找到,再用 str() 方法把键转换成字符串再查找一次。
return key in self.keys() or str(key) in self.keys()
10.normalize清洗字符
#保存文本之前,最好使用 normalize('NFC',user_text) 清洗字符串
from unicodedata import normalize
s1="cafe\u0301"
news1=normalize("NFC",s1)
print(len(s1),s1)
print(len(news1),news1)
11.string属性casefold(大小写折叠)
对大多数应用来说,NFC 是最好的规范化形式。不区分大小写的
比较应该使用 str.casefold()。
12.
import unicodedata
import string
def shave_marks(txt):
"""去掉全部变音符号"""
norm_txt = unicodedata.normalize('NFD', txt) ➊
shaved = ''.join(c for c in norm_txt
if not unicodedata.combining(c)) ➋
return unicodedata.normalize('NFC', shaved) ➌
➊ 把所有字符分解成基字符和组合记号。
➋ 过滤掉所有组合记号。
➌ 重组所有字符。
13 函数,对象的调用
调用类时会运行类的 __new__ 方法创建一个实例,然后运行
__init__ 方法,初始化实例,最后把实例返回给调用方。因为 Python
没有 new 运算符,所以调用类相当于调用函数。
14.自定义可调用对象
不仅 Python 函数是真正的对象,任何 Python 对象都可以表现得像函
数。为此,只需实现实例方法 __call__。
15.函数注解
函数声明中的各个参数可以在 : 之后增加注解表达式。如果参数有默认
值,注解放在参数名和 = 号之间。如果想注解返回值,在 ) 和函数声明
末尾的 : 之间添加 -> 和一个表达式。那个表达式可以是任何类型。注
解中最常用的类型是类(如 str 或 int)和字符串(如 'int >
0')。在示例 5-19 中,max_len 参数的注解用的是字符串。
注解不会做任何处理,只是存储在函数的 __annotations__ 属性
def clip(text:str, max_len:'int > 0'=80) -> str: ➊
"""在max_len前面或后面的第一个空格处截断文本
"""
end = None
if len(text) > max_len:
space_before = text.rfind(' ', 0, max_len)
if space_before >= 0:
end = space_before
else:
space_after = text.rfind(' ', max_len)
if space_after >= 0:
end = space_after
if end is None: # 没找到空格
end = len(text)
return text[:end].rstrip()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号