【转】mysql基础汇总
原文:https://www.cnblogs.com/cxx8181602/p/9525950.html
连接数据库操作

/*连接mysql*/ mysql -h 地址 -P 端口 -u 用户名 -p 密码 例如: mysql -h 127.0.0.1 -P 3306 -u root -p **** /*退出mysql*/ exit;
数据库操作
#数据库操作 /*关键字:create 创建数据库(增)*/ create database 数据库名 [数据库选项]; 例如: create database test default charset utf8 collate utf8_bin; /*数据库选项:字符集和校对规则*/ 字符集:一般默认utf8; 校对规则常见: ⑴ci结尾的:不分区大小写 ⑵cs结尾的:区分大小写 ⑶bin结尾的:二进制编码进行比较 /*关键字:show 查看当前有哪些数据库(查)*/ show databases; /*查看数据库的创建语句*/ show create database 数据库名; /*关键字:alter 修改数据库的选项信息(改)*/ alter database 数据库名 [新的数据库选项]; 例如: alter database test default charset gbk; /*关键字:drop 删除数据库(删)*/ drop database 数据库名; /*关键字:use 进入指定的数据库*/ use 数据库名;
表的操作
#表的操作 /*关键字:create 创建数据表(增)*/ create table 表名( 字段1 字段1类型 [字段选项], 字段2 字段2类型 [字段选项], 字段n 字段n类型 [字段选项] )表选项信息; 例如: create table test( id int(10) unsigned not null auto_increment comment 'id', content varchar(100) not null default '' comment '内容', time int(10) not null default 0 comment '时间', primary key (id) )engine=InnoDB default charset=utf8 comment='测试表'; 语法解析(下文MySQL列属性单独解析): 如果不想字段为NULL可以设置字段的属性为NOT NUL,在操作数据库时如果输入该字段的数据为NULL,就会报错. AUTO_INCREMENT定义列为自增的属性,一般用于主键,数值会自动加1. PRIMARY KEY关键字用于定义列为主键.可以使用多列来定义主键,列间以逗号分隔. ENGINE 设置存储引擎,CHARSET 设置编码, comment 备注信息.
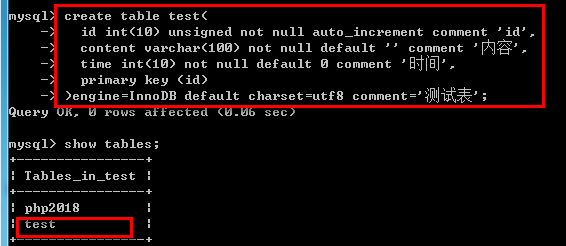
/*关键字:show 查询当前数据库下有哪些数据表(查)*/ show tables; /*关键字:like 模糊查询*/ 通配符:_可以代表任意的单个字符,%可以代表任意的字符 show tables like '模糊查询表名%'; /*查看表的创建语句*/ show create table 表名; /*查看表的结构*/ desc 表名; /*关键字:drop 删除数据表(删)*/ drop table [if exists] 表名 例如: drop table if exists test; /*关键字:alter 修改表名(改)*/ alter table 旧表名 rename to 新表名;
/*修改列定义*/ /*关键字:add 增加一列*/ alter table 表名 add 新列名 字段类型 [字段选项]; 例如: alter table test add name char(10) not null default '' comment '名字';
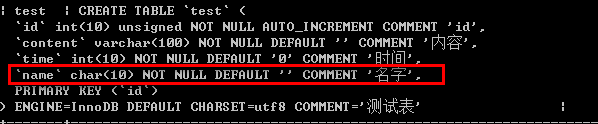
/*关键字:drop 删除一列*/ alter table 表名 drop 字段名; 例如: alter table test drop content;
/*关键字:modify 修改字段类型*/ alter table 表名 modify 字段名 新的字段类型 [新的字段选项]; 例如: alter table test modify name varchar(100) not null default 'admin' comment '修改后名字';

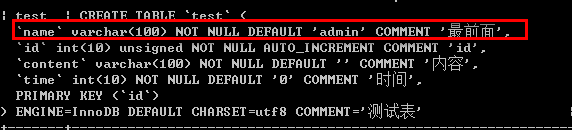
/*关键字:first 修改字段排序,把某个字段放在最前面*/ alter table 表名 modify 字段名 字段类型 [字段选项] first; 例如: alter table test modify name varchar(100) not null default 'admin' comment '最前面' first;
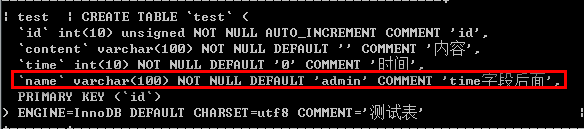
/*关键字:after 修改字段排序,字段名1放在字段名2的后面*/ alter table 表名 modify 字段名1 字段类型 [字段选项] after 字段名2; 例如: alter table test modify name varchar(100) not null default 'admin' comment 'time字段后面' after time;
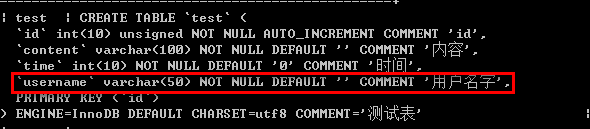
/*关键字:change 重命名字段*/ alter table 表名 change 原字段名 新字段名 新的字段类型 [新的字段选项]; 例如: alter table test change name username varchar(50) not null default '' comment '用户名字';
/*修改表选项*/ alter table 表名 表选项信息; 例如: alter table test engine Myisam default charset gbk; --修改存储引擎和修改表的字符集

数据操作
#数据操作
/*关键字:insert 插入数据(增)*/
insert into 表名(字段列表) values(值列表);
例如: create table user(
id int(10) unsigned not null auto_increment comment 'id',
name char(10) not null default '' comment '名字',
age int(3) not null default 0 comment '年龄',
primary key (id)
)engine=InnoDB default charset=utf8 comment='用户表';
--插入数据
insert into user(id,name,age) values(1,'admin_a',50);
insert into user(name) values('admin_b');
/*关键字:select 查询数据(查)*/ select *[字段列表] from 表名[查询条件]; 例如: select * from user;--查全部字段用*代替
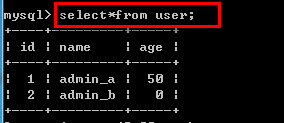
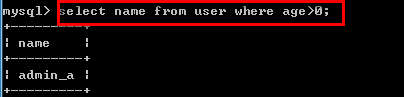
select name from user where age>0;--查name字段,age大于0
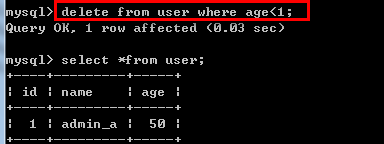
/*关键字:delete 删除数据(删)*/ delete from 表名[删除条件]; 例如: delete from user where age<1;--删除age小于1数据
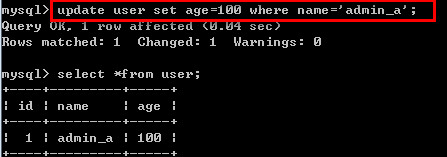
/*关键字:update 修改数据(改)*/ update 表名 set 字段1=新值1,字段n=新值n [修改条件]; 例如: update user set age=100 where name='admin_a';
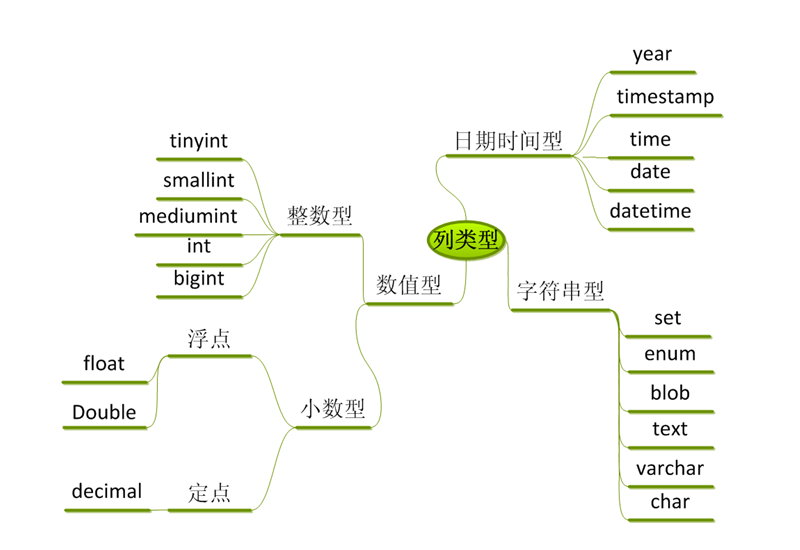
MySQL数据类型
#MySQL数据类型 /*MySQL三大数据类型:数值型、字符串型和日期时间型*/
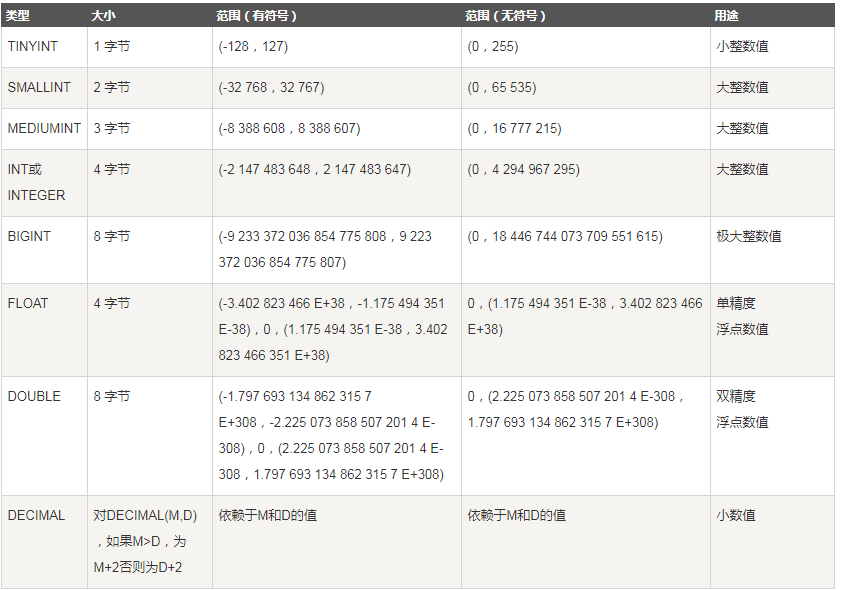
/*数值型*/
/*字符串型*/

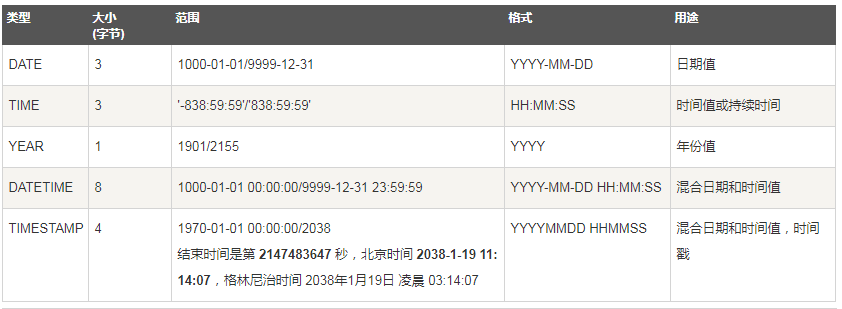
/*日期时间型*/
MySQL列属性
#MySQL列属性
/*null、not null、default、primary key、auto_increment、comment*/
MySQL真正约束字段的是数据类型,但是数据类型的约束太单一,需要有一些额外的约束,来更加保证数据的合法性.
MySQL常用列属性有:null、not null、default、primary key、auto_increment、comment.
/*空属性: null和not null*/
空属性: null(空,默认) 和 not null(不为空). mysql数据库默认字段都是为null的,实际开发过程中尽可能保证所有的数据都不应该为null,空数据没有意义.
例如: create table test(
a int not null,
b int
);
insert into test (a,b) values(10,null);
insert into test (a,b) values(null,10);--报错

/*默认值: default*/
default: 自定义默认值属性,通常配合not null一起使用.
例如: create table test1(
a int not null default 200,
b int
);
insert into test1(b) values(20);--或 insert into test1(a,b) values(default,20);

/*主键|唯一索引*/ Mysql中提供了多种索引? (下文索引更多解析) 1.主键索引:primary key 2.唯一索引:unique key 3.全文索引:fulltext index 4.普通索引:key 或 index 主键:primary key 一张表中只能有一个字段可以使用对应的主键,用来唯一的约束该字段里面的数据,不能重复和不能为null. 设置主键有两种方式: (1)在定义一个字段的时候直接在后面进行设置primary key 例如: create table test2( id int(10) unsigned not null primary key, name char(20) not null default '' );
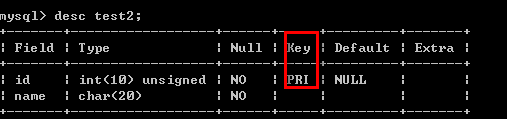
(2)定义完字段后再定义主键 例如: create table test3( id int(10) unsigned not null, name char(20) not null default '', primary key (id) );
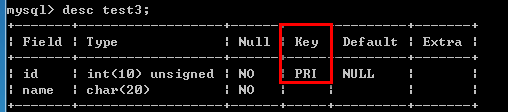
唯一键:unique key 解决表中多个字段需要唯一性约束的问题. 例如:create table test4( id int(10) unsigned not null, name char(20) not null default '', goods varchar(100) not null default '', primary key (id), unique key (name,goods) );
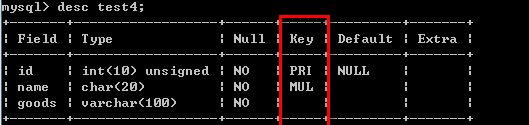
/*自动增长: auto_increment*/ 自增长属性:每次插入记录的时候,自动的为某个字段的值加1(基于上一个记录). 通常跟主键搭配. 自增长规则:(1)任何一个字段要做自增长前提必须是一个索引 (2)自增长字段必须是整型数字 例如: create table test5( id int(10) unsigned not null auto_increment, name char(20) not null default '', primary key (id) );

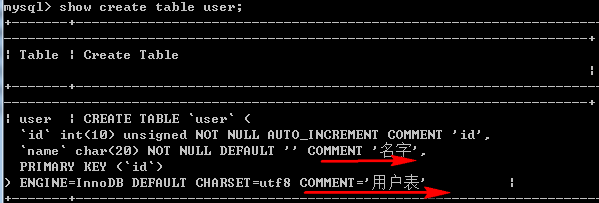
/*列描述 comment*/ 列描述(注释):comment 与其他的注释符不同之处在于,这里的注释内容属于列定义的一部分. 例如:create table user( id int(10) unsigned not null auto_increment comment 'id', name char(20) not null default '' comment '名字', primary key (id) )engine=InnoDB default charset=utf8 comment='用户表';
索引
#索引 /*索引的概述和优缺点和种类*/ 什么是索引? 索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针. 类比理解:数据库中的索引相当于书籍目录一样,能加快数据库的查询速度. 没有索引的情况,数据库会遍历全部数据后选择符合条件的选项. 创建相应的索引,数据库会直接在索引中查找符合条件的选项. 索引的性质分类: 索引分为聚集索引和非聚集索引两种,聚集索引是索引中键值的逻辑顺序决定了表中相应行的物理顺序,而非聚集索引是不一样; 聚集索引能提高多行检索的速度,而非聚集索引对于单行的检索很快. 索引的优点: (1)加快数据检索速度 (创建索引主要原因) (2)创建唯一性索引,保证数据库表中每一行数据的唯一性 (3)加速表和表之间的连接 (4)使用分组和排序子句对数据检索时,减少检索时间 (5)使用索引在查询的过程中,使用优化隐藏器,提高系统的性能 索引的缺点: (1)创建索引和维护索引要耗费时间,时间随着数据量的增加而增加 (2)索引需要占用物理空间和数据空间 (3)表中的数据操作插入、删除、修改, 维护数据速度下降 索引种类 (1)普通索引: 仅加速查询 (2)唯一索引: 加速查询 + 列值唯一(可以有null) (3)主键索引: 加速查询 + 列值唯一(不可以有null)+ 表中只有一个 (4)组合索引: 多列值组成一个索引,专门用于组合搜索,其效率大于索引合并 (5)全文索引: 对文本的内容进行分词,进行搜索 (注意:目前仅有MyISAM引擎支持)
/*创建表时直接指定索引*/ --创建主键索引 例如:create table student( id int(10) unsigned not null auto_increment comment 'id主键索引', name char(20) not null default '' comment '名字', class varchar(50) not null default '' comment '班级', seat_number smallint(5) not null default 0 comment '座位编号', primary key (id) )engine=InnoDB default charset=utf8 comment='学生表';
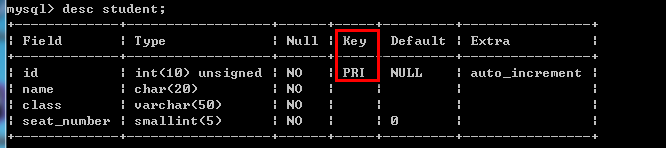
/*创建索引*/ create [unique唯一索引][clustered聚集索引] index <索引名> on <表名>(<列名称>[<排序>],<列名称>[<排序>]…); 语法解析:其中unique和clustered为可选项. 注意:基本表上最多仅仅能建立一个聚集索引. "列名称":规定需要索引的列. "排序":可选asc(升序)和desc(降序)缺省值为asc.
--创建唯一索引(unique key 简写 unique) 例如:create unique index number on student(seat_number desc);
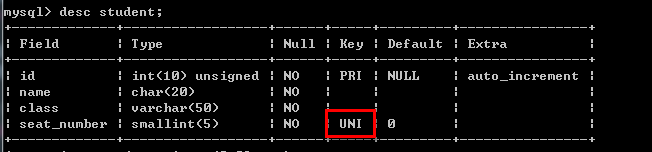
--创建普通索引 例如:create index name_class on student(name asc,class desc);
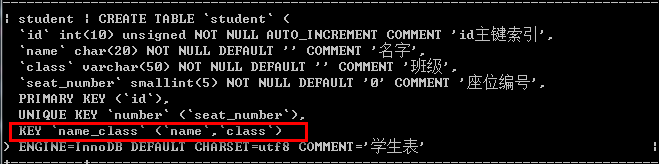
/*删除索引*/ drop index <索引名> on 表名; 例如:drop index number on student;
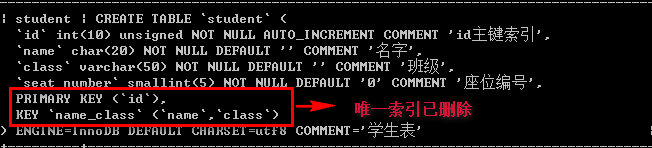
外键
/*外键约束: foreign key */ 外键约束: foreign key 被约束的表叫做副表,外键设置在副表上面,外键引用主键字段所在的表叫做主表. (作用:约束两张表的数据) 外键定义语法: constraint 外键约束名称 foreign key(外键字段) references 主表名称(引用字段) 外键数据操作: 1.当有外键约束之后,添加数据的时候,先添加主表数据,再添加副表数据 2.当有了外键约束,修改数据的时候,先改副表的数据,在修改主表的数据 3.当有了外键约束,删除数据的时候,也是先删除副表的数据,再删除主表的数据
外键注意事项: 1.外键约束只有InnoDB存储引擎才支持. 2.实际项目中往往会用到外键的设计思想,但往往不会真正的从语法上进行外键约束. 因为外键约束的级联操作可能会带来一些现实的逻辑问题. 另外使用外键会较低mysql的效率.
储存引擎
/*储存引擎: engine*/ 常见的引擎:Myisam InnoDB BDB Memory Archive 等 不同的引擎在保存表的结构和数据时采用不同的方式? MyISAM表文件含义:.frm表定义,.MYD表数据,.MYI表索引 InnoDB表文件含义:.frm表定义,表数据空间文件(存放表的数据和索引)和日志文件
注意:项目中一般用InnoDB引擎.
MySQL中innodb与myisam的区别 (1):InnoDB支持事物,MyISAM不支持事物 (2):InnoDB支持行级锁,MyISAM支持表级锁 (3):InnoDB支持快照数据(MVCC),MyISAM不支持 (4):InnoDB支持外键,MyISAM不支持 (5):InnoDB不支持全文索引,MyISAM支持 innodb使用的是行级锁:只有在增删改查时匹配的条件字段带有索引时,innodb才会使用行级锁.(行级锁:要为匹配条件字段加索引) innodb使用的是表级锁:如果增删改查时匹配的条件字段不带有索引时,innodb使用的将是表级锁.(表级锁:数据库全表查询,需要将整张表加锁,保证查询匹配的正确性) 触发读锁:就是用select命令时触发读锁. 触发写锁:就是在你使用update,delete,insert时触发写锁,并且使用rollback或commit后解除本次锁定 更好的区分:读写锁和表级锁行级锁. 将读写锁叫做权限锁(决定了加锁后用户有哪些操作权限),将表级锁行级锁叫做对象锁(决定将锁加在某一行还是整张表) MVCC多版本并发控制,也可称之为一致性非锁定读;它通过行的多版本控制方式来读取当前执行时间数据库中的行数据. 实质上使用的是快照数据. 为什么要使用MVCC? 消除锁的开销. (如果要保证数据的一致性,最简单的方式就是对操作数据进行加锁,但是加锁不可避免的会有锁开销. 所以使用MVCC能避免进行加锁的方式并提高并发.)
三范式
/*数据库三范式*/ --建表规范 - 每个表保存一个实体信息 - 每个具有一个ID字段作为主键 - ID主键 + 原子表 --第一范式 字段不能再分,确保每列保持原子性. --第二范式 满足第一范式的基础上,不能有部分依赖. 消除符合组合主键(A,B)就可以避免部分依赖. 增加单列关键字. --第三范式 满足第二范式的基础上,不能有传递依赖. 某个字段依赖于主键,而有其他字段依赖于该字段. 这就是传递依赖. 将一个实体信息的数据放在一个表内实现

 浙公网安备 33010602011771号
浙公网安备 33010602011771号