数据分析|改革春风吹满地火在哪里
数据分析|改革春风吹满地火在哪里
改革春风吹满地,中国人民真争气。

2018年年末,“改革春风吹满地”火了。这是一个来自哔哩哔哩的一个鬼畜类音乐视频。
由up主小可儿上传,目前播放量已达到1400多万,有着相当高的热度。该视频剪辑了赵本山的历年作品的经典台词,配以略带喜感的音乐(bgm由其他up主制作),每一句台词衔接的相当完美。在网易云音乐里也可以搜到同名音乐,另有别名「念诗之王」正常,网易云的一位
名为A96ccA的这样写道:
第一遍:这是啥玩意?
第二遍:嗯,还可以
第三遍:改革春风吹满地…
可以看出同样的是一首洗脑的音乐。
下面让我先来欣赏(再度洗脑)一下。
视频地址:
下面就让我们爬取b站上该视频的评论内容,并进行分析为什么这个视频会如此的火。
. 数据下载
首先我们找到视频:https://www.bilibili.com/video/av19390801.
然后找到评论部分,打开谷歌浏览器的控制台,查看network选项的请求信息。通过观察我们发现了这样的链接:https://api.bilibili.com/x/v2/reply?callback=jQuery17204794190151297566_1546432727230&jsonp=jsonp&pn=1&type=1&oid=19390801&sort=0&_=1546432740370
去掉没有用的信息最后我们得到最终的url形式为:https://api.bilibili.com/x/v2/reply?pn={pn}&type=1&oid=19390801
其中pn为第几页,目前看到评论有1129页,这些数据我们用作简单的数据分析基本够用了。
下面就可以编写我们的代码了,这里我采取的是异步网络请求模块aiohttp。然后保存下了每条评论的所以网页可以得到的信息,后期获取每条评论的内容,为后面数据分析使用
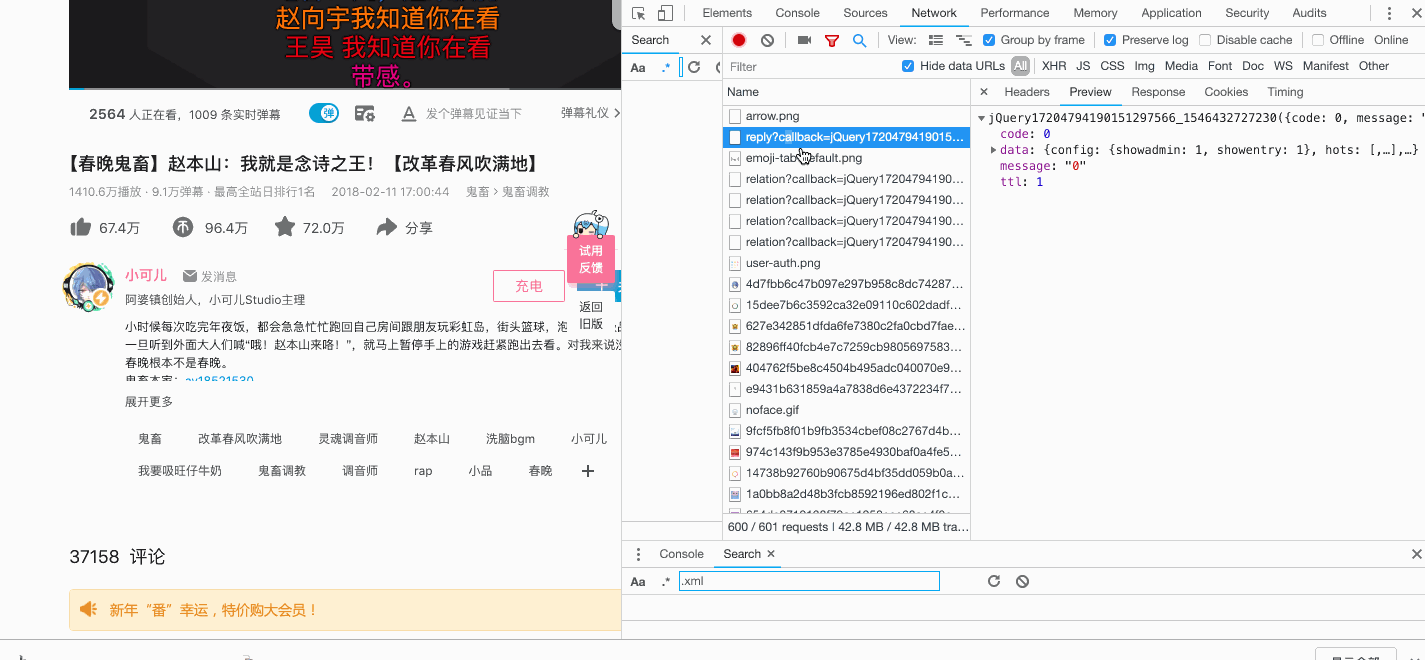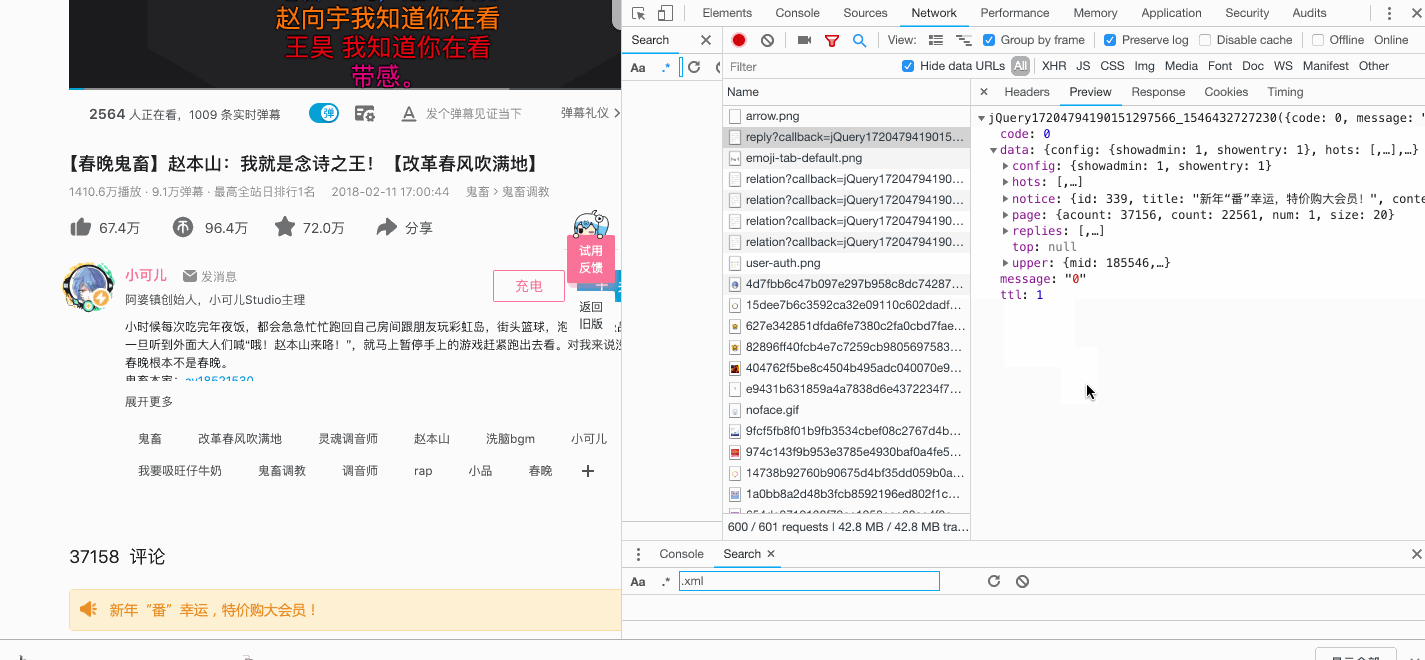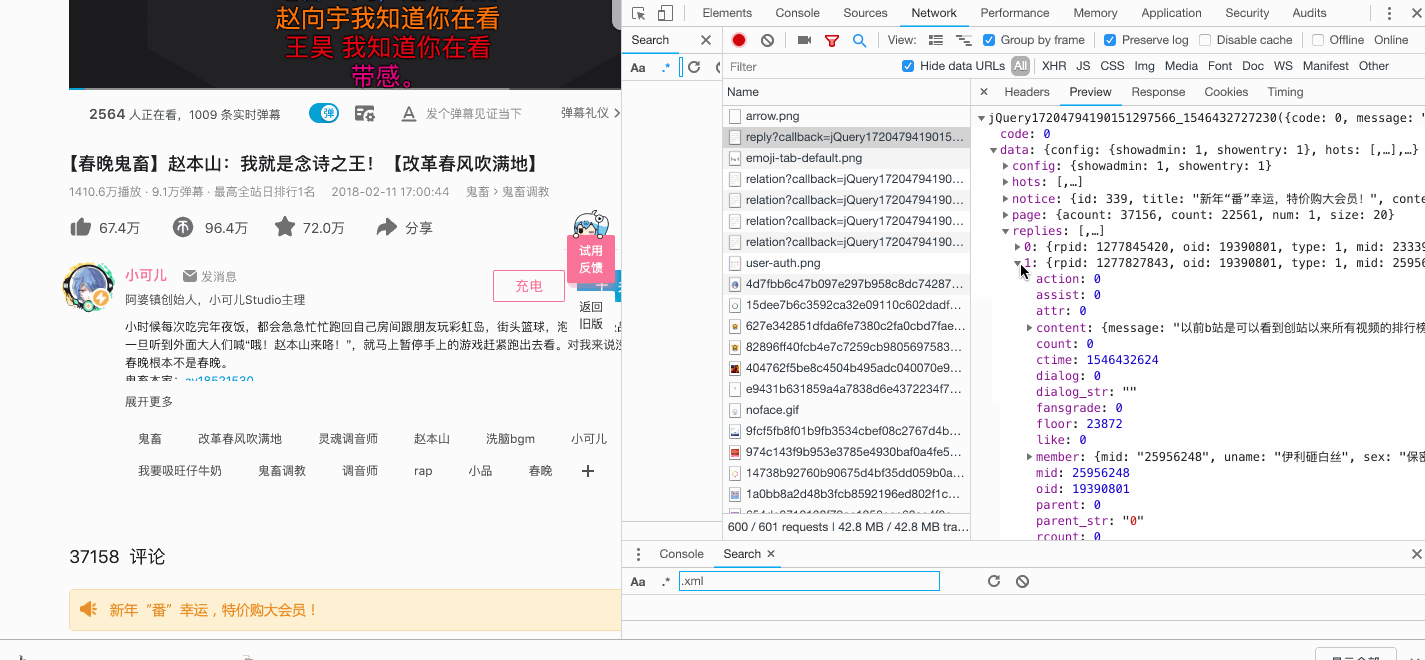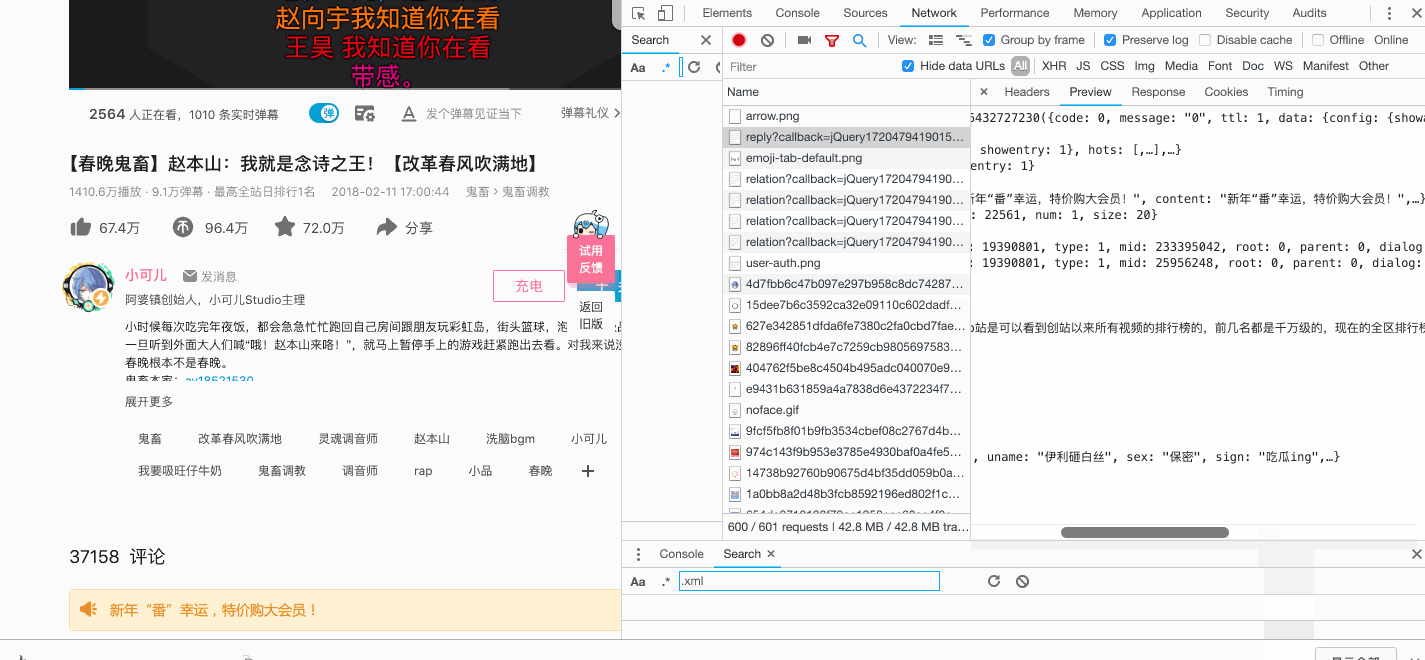
下面是主要爬取逻辑
base_url = "https://api.bilibili.com/x/v2/reply?pn={pn}&type=1&oid=19390801"
async def fetch(url):
async with sem: #并发个数控制
async with aiohttp.ClientSession() as session: #创建session
with async_timeout.timeout(10): #等10s
async with session.get(url) as res:
data = await res.json()#通过await获取异步过程中的数据
print(data)
await asyncio.sleep(2)#加个异步等待防止被封。
await save_data(glom.glom(data, "data.replies"))#glom模块json数据解析用。
这里需要用到以下模块,使用pip install即可安装
aiohttp
async_timeout
uvloop(windows就不用了,只支持unix系统)
glom
需要说明的是之前我就是因为没有加等待时间,所以被b站这个接口的链接给封了,造成的现象就是视频可以看但是评论是刷新不出来的,挺有意思的。关于aiohttp的使用方法,有兴趣的朋友可以看我之前写的文章:aiohttp地址放这。
到这里数据下载逻辑就完事了,下面是数据存储逻辑。
. 数据存储
因为上面的下载的结果是json格式,所以首先数据库就是mongodb,这里为了统一使用了异步mongo数据模块motor,一个基于事件循环的模块。
首先创建数据链接
class MotorBase:
_db = {}
_collection = {}
def __init__(self, loop=None):
self.motor_uri = ''
self.loop = loop or asyncio.get_event_loop()
def client(self, db):
self.motor_uri = f"mongodb://localhost:27017/{db}"
return AsyncIOMotorClient(self.motor_uri, io_loop=self.loop)
def get_db(self, db='weixin_use_data'):
if db not in self._db:
self._db[db] = self.client(db)[db]
return self._db[db]
这里使用模块有:
asyncio
motor
然后开始使用类似pymongo的方式插入数据,具体代码如下
async def save_data(items):
mb = MotorBase().get_db('weixin_use_data') #获取链接对象,weixin_use_data是我的数据库名。
for item in items:
try:
await mb.bilibili_comments.update_one({
'rpid': item.get("rpid")},
{'$set': item},
upsert=True)#bilibili_comments是我的表名,update_one方法的作用是不存在就插入存在更新。
except Exception as e:
print("数据插入出错", e.args,"此时的item是",item)
然后通过执行这个事件循环,事件循环是这里所有异步的基础。
loop = asyncio.get_event_loop()#创建一个事件循环
loop.run_until_complete(get_data())#开始运行直到程序结束
. 数据解析
上面我们拿到了作出数据,但是数据都是json格式的,而且量很大,我们需要的只有评论内容,所以我们需要进一步对数据进行处理,同样的这里我也使用了文件读写异步模块aiofiles
。
这部分代码量也很少,用法和open file差不多,多了些异步的形式而已。
首先读取mongo里的数据
async def get_data():
mb = MotorBase().get_db('weixin_use_data')
data=mb.bilibili_comments.find()
return data
读取还是用的motor模块为了配合后面的文件读入使用。
async def m2f():
data = await get_data()
async for item in data:
t = item.get("content").get("message").strip()
fs = await aiofiles.open(pathlib.Path.joinpath(pathlib.Path.cwd().parent, "msg.txt"), 'a+')#pathlib路径拼接
await fs.write(t)
到目前为止数据获取部分基本结束了,后面就是对上面的文本文件进行分析了。
. 数据分析
为了清晰的表达数据所带来的信息,对于评论信息,我们选用直观的方式--词云图
准备工作
安装包
jieba
wordcloud
matplotlib
生成词云需要用的图

字体文件
mac中默认字体显示乱码,这里指定了别的字体msyhbd.ttf,网上随便搜了一个,windows可以或其他系统支持字体即可
停用词设置
经过分析大概设置了如下停用词:
哈
哈哈
哈哈哈
xa0
一个
u3000
什么
视频
这个
up
看到
怎么
播放
真的
知道
已经
改革
春风
满地
鬼畜
抖音
现在
春晚
千万
助攻
停用词设置是为了去除一些没有意义的词,比如这个,那个之类的。或者当前文件的标题
代码如下
# -*- coding: utf-8 -*-
# @Time : 2019/1/2 7:52 PM
# @Author : cxa
# @File : cutword.py
# @Software: PyCharm
# coding=utf-8
import jieba
import matplotlib.pyplot as plt
from wordcloud import WordCloud
# 获取所有评论
comments = []
with open('msg.txt', mode='r', encoding='utf-8') as f:
rows = f.readlines()
for row in rows:
comments.append(row)
# 设置分词
comment_after_split = jieba.cut(str(comments), cut_all=False) #分词,cut_all=false
words = ' '.join(comment_after_split) # 以空格进行拼接
# 设置屏蔽词
STOPWORDS = set(map(str.strip, open('stopwords').readlines()))
print(STOPWORDS)
# 导入背景图
bg_image = plt.imread('1.jpeg')
# 设置词云参数,参数分别表示:画布宽高、背景颜色、背景图形状、字体,屏蔽词、最大词的字体大小
wc = WordCloud(width=2024, height=1400, background_color='white', mask=bg_image,font_path='msyhbd.ttf',stopwords=STOPWORDS, max_font_size=400,
random_state=50)
# 将分词后数据传入云图
wc.generate_from_text(words)
plt.imshow(wc)
plt.axis('off') # 不显示坐标轴
plt.show()
# 保存结果到本地
wc.to_file('ggcfcmd.jpg')
最终结果

由此可以看出这视频最重要的还是洗脑,导致进来就出不去了,同样的也是追忆本山大叔多年来带给大家的无数快乐时光,总之洗脑就完事了
一直以为这个视频是年底的时候才开始传播的,然而事情并不是这样。。。
评论发布时间分析
从mongodb中抽取评论时间
分析了之前爬取的json数据,其中每一组有一个ctime参数,根据经验可知这是一个时间戳,
于是使用tool文件夹下的mongo_to_csv.py文件的get_ctime方法取出每一条记录的时间戳,同时转换成年月日的形式存入到ctime.txt文件中。对后续的操作作准备。
对时间排序并计数
这一步核心代码如下
from collections import Counter, Mapping
from operator import itemgetter
with open("ctime.txt") as fs:
data = (i.strip() for i in fs.readlines())
d = dict(sorted(Counter(data).items(), key=itemgetter(0)))
print(d)
首先,读取文件循环去除换行符,生成新的数据,生成的是个生成器对象,目的是省内存。
然后调用python标准库的collections模块的Counter方法,做一个计数参做,因为isinstance(Counter,Mapping)会输出True,可知其属于映射类型,因此有着类似字典的方法,于是对该对象做一个排序,其中这里的key=itemgetter(0),表示按照第一个元素排序,
itemgetter来自python标准库的operator模块,之后转换成字典,为后面的数据显示作准备。
最后的结果如下:
我们可以发现评论开始日期是从2018-02-11开始的,一开始我也没有去注意视频的发布时间,我以为分析错了呢,赶紧去看了一眼视频,还真是 2018-2-11发布
然后评论数越来越少,然后到11左右再次上来了,为了知道原因,我去翻阅了下该段时间评论大致知道了,由于抖音的传播和微博的传播,以其后来bgm成了微博的热搜关键字,也就是不难想象这段时间评论量的上升了,其实大家还可以对这段时间的评论内容做个词云分析,去看关键字,或者去做个情感分析。这就交给大家去完成了。
总结
通过这次对评论内容以及时间的分析,尤其是评论数的时间,真正的感受到了数据分析的乐趣。好了本次的内容就结束了,喜欢大家能够喜欢。
为了方便大家的阅读代码,本文中所有涉及到的代码,已经传到https://github.com/muzico425/bilibilianalysis.git
如果您喜欢我的文章就点击右下角的好看吧![]()
![]()
![]() ,谢谢。加微信:italocxa进群。
,谢谢。加微信:italocxa进群。
为了方便大家的阅读代码,本文中所有涉及到的代码,已经传到https://github.com/muzico425/bilibilianalysis.git

 浙公网安备 33010602011771号
浙公网安备 33010602011771号