selenium 元素定位
开头
简单介绍selenium的元素定位,主要集中在 xpath中
xpath
- XML Path Language
- 用于解析html和xml
xpath 的缺点比css慢,是从头到尾的便利
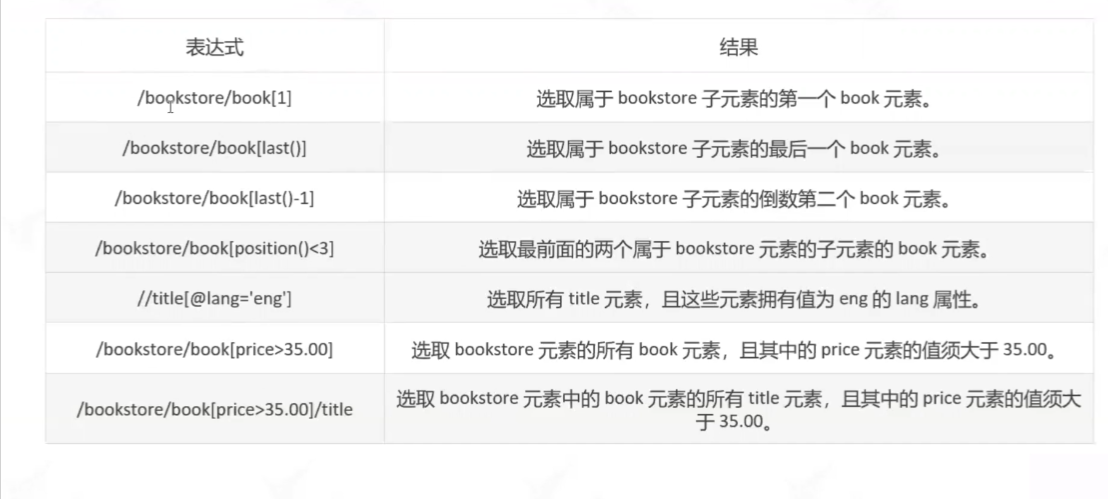
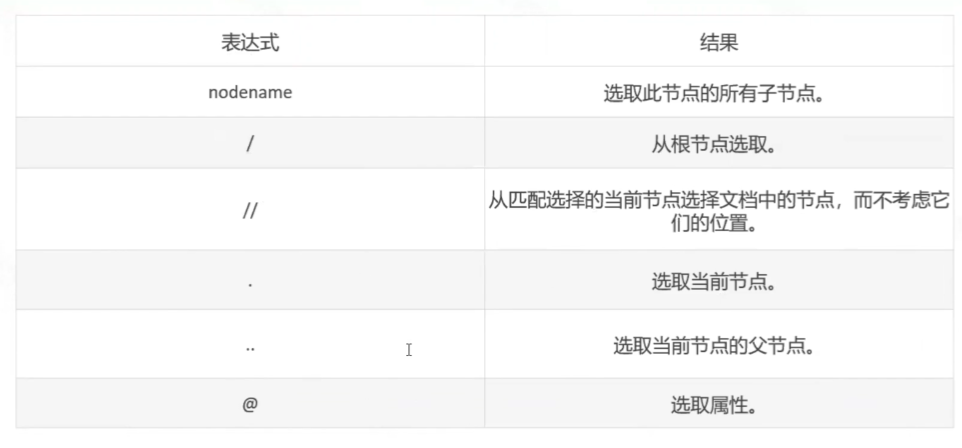
常用的表达式
常用在网页端进行测试,在想匹配的地方, 打开控制台,进行匹配测试, 可以先用clear() 清除控制台无用信息
在控制台中 匹配想要的结果并查看,需要写完xpath定位式之后填写回车
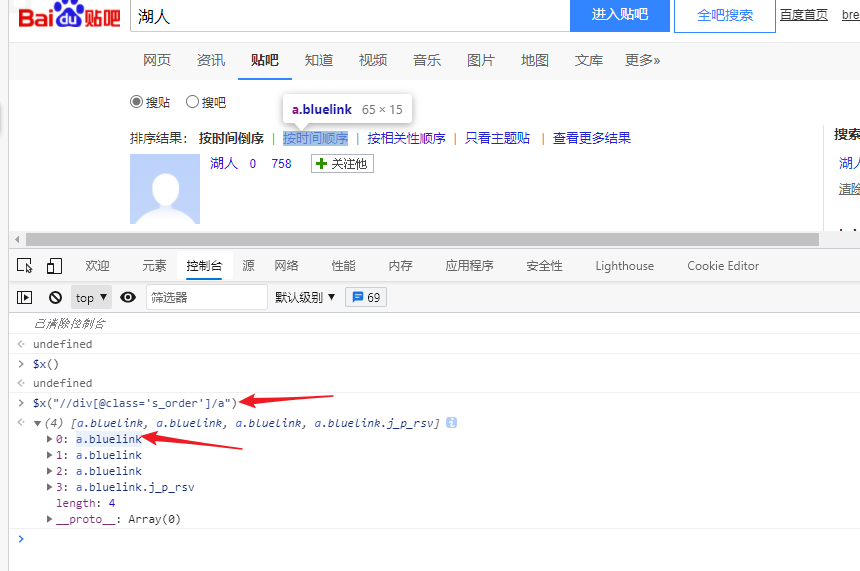
匹配最后一个的 xpath 写法:
$x("//div[@class='s_order']/a[last()]") # 匹配列表元素的最后一个
$x("//div[@class='s_order']/a[last()-1]") # 匹配列表元素的倒数第二个
测试例子
# xpath的使用
from lxml import etree
html = '''
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
doc = etree.HTML(html)
# 拿到指定的标签下的原代码,因为etree.tostring是拿到brary所以需要decode转为str
ul_list = doc.xpath('//ul[@class="list"]')
ul_html = etree.tostring(ul_list[0]).decode('utf-8')
# print(ul_html) # 拿到ul下的
li_list = doc.xpath('//li')
for li_s in li_list:
li_html = etree.tostring(li_s).decode('utf-8') # 拿到li下的所有文字
# 父节点的选择 在这里我们可以用 .. 来获取父节点。
par_list = doc.xpath('//ul[@class="list"]/..')
par_html = etree.tostring(par_list[0]).decode('utf-8')
# print(par_list)
# print(par_html)
# 属性匹配
# result = doc.xpath('//li[@class="item-0"]')
# for i in result:
# print(i.xpath('.//text()'))
# 文本获取 只要在Li下的文本都匹配
result = doc.xpath('//li')
# for i in result:
# # print(i.xpath('.//text()')) # // 拿到全部的文本
# print(i.xpath('./text()')) # 拿到 只在这个标签下的 text
# 拿到标签里面的属性
# for i in result:
# print(i.xpath('./a/@href'))
# 多属性匹配
text = '''
<li class="li li-first" name="item"><a href="https://ask.hellobi.com/link.html">first item</a></li>
'''
html = etree.HTML(text)
result = html.xpath('//li[contains(@name, "item")]/a/@href')
print(result)
# 如果还含有name,有and
result = html.xpath('//li[contains(@class, "li") and @name="item"]/a/@href')
print(result)
# 读一个html文件,构建一个xml dom树
# html = etree.parse('./test.html', etree.HTMLParser())
# result = html.xpath('//ul//a')
# print(result)
html = '''
<div class="wrap">
Hello, World
<p>This is a paragraph.</p>
</div>
'''
# print(html)
html = etree.HTML(html)
resp = html.xpath('//div[@class="wrap"]/text()') # 只提取当前标签下的
print(resp)
############两个办法提取某标签下全部文本#########
resps = html.xpath('//div[@class="wrap"]//text()')
print(resps)
con = []
for x in resps:
con.append(x.strip()) # 得到的text会去掉所有换行
print(con)
# print('--')
re_ = ''.join(con)
print(re_)
############2222#########
print('='*30)
resps = html.xpath('//div[@class="wrap"]') # 提取全部的文本
# print(resps)
con = []
for x in resps:
# print(x.xpath('string(.)'))
con.append(x.xpath('string(.)').strip()) # 会更完整的保留text
print(con)
# print('--')
re_ = ''.join(con)
print(re_)
# xpath取其中几个使用position 的使用,可以用 > 或者 <
# path:"//*[@id='nav']/ul/li[position()>1 and position()<7]"
resps = html.xpath('//td[@valign="top"][2]/div[@class="ut"]/span[position()>1 and contains(@class, "ctt")]')
# 关于xpath下载到二进制的问题
with open('t1.html', 'r', encoding='utf-8') as f:
html = f.read()
html = bytes(bytearray(html, encoding='utf-8')) # 撞成二进制的格式然后bytearray() 方法返回一个新字节数组。转为bytearray数组之后再转为二进制B 最后可以生成dom树
# 参考 https://blog.csdn.net/songhao8080/article/details/103670324 如果text读取不出来,就需要放二进制读取
# scrapy中response.body 与 response.text区别
# body http响应正文, byte类型
# text 文本形式的http正文,str类型,它是response.body经过response.encoding经过解码得到
完。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号