深度学习加速小技巧
 一些小技巧来加速你的深度学习模型训练
一些小技巧来加速你的深度学习模型训练
前言
作为时常需要训练深度学习模型的“炼丹师”,我们肯定是想又快又好的训练出一个模型。
但是事与愿违,在当前深度学习任务愈发复杂,模型深度越来越深的时代,如果又刚好你没有很多了计算资源,那么调参过程可能对于你来说比较的痛苦。训练得到一个结果需要几十小时甚至几天,如果和原文的数据对不上,你还得苦思冥想,再等几天😭
所以为了更加有效率的进行炼丹,这里也总结了一些能加速训练过程的技巧

开始加速
模型的训练也遵循了木桶原则,对于不同的任务,出现短板的地方也会不一样,所以不能直接照搬,需要根据自己的训练任务对症下药。
数据读取
对于一般的深度学习任务,正常的数据流就是CPU负责将磁盘中的数据读取到内存中,这一部分就是数据读取部分,对应Pytorch中的Dataloader,如果发现显卡在训练的过程中使用率很波动,会经常的掉到0%,那么很有可能是数据读取部分出了问题。
-
设置num_worker > 0
你可以在
DataLoader(dataset=train_data, batch_size=train_bs, shuffle=True, num_worker=4)中找到num_worker这一属性,这个参数负责指定创建多少个进程同时去读取硬盘中的数据,如上面num_worker=4,表示创建了4个worker进程读取数据,但是这个worker并不是设置的越大越好,根据前人的经验,一般是num_worker = 4 * GPU数量,如果你只用一个显卡进行计算,那就设置为4。这个值默认为0,表示让Pytorch自己自动的去创建进程来读取,因为只有当Pytorch发现进程数量不够的时候,才会动态的增加进程数量,所以往往设置为0的时候会比手动指定的时候慢。 -
设置pin_memory=True
这一个属性同样是在
Dataloader中,将这个属性设置为True表示将Dataloader读取的数据保存在主机内存的锁页内存中,至于这个锁页内存是什么,这里引用一下网上的解释:主机中的内存根据是否与虚拟内存(虚拟内存指的是硬盘)进行交换分为两种,一种是锁页内存,另一种是不锁页内存。
- 锁页内存指存放的内容在任何情况下都不与主机虚拟内存进行交换。
- 不锁页内存指在主机内存不足时,数据存放在虚拟内存中。
显卡中的显存全部是锁页内存!
所以如果你读取的数据保存在锁页内存中,那么你的数据在之后传输到显卡的内存中的时候,会快一点。默认情况下,pin_memory设置为False,因为开启此项会加大内存的消耗,需要根据机器的实际内存占用来判断能否开启(一般都是够的)
-
使用封装的数据格式
如果使用过TensorFlow,应该会对TensorFlow的专有数据格式TFRecord有印象,TFRecord将各类数据,例如图,音频等数据以二进制的格式保存起来,这样虽然会在最开始的时候花一些时间将常见的JPG、PNG、MP3文件转换为TFRecord文件,但是在这之后读取的时候会快很多,实现了高速的数据读取。
对于现在主流的Pytorch框架来说,虽然官方没有出一个专用的数据格式,但是由于各路大佬的帮忙,Pytorch已经可以读取TFRecord文件了,这里附上GitHub链接:https://github.com/vahidk/tfrecord
那么我们什么时候需要将直接读取图片转变为读取封装的格式呢?对于有一些任务,在图片读取进来之后,图片还需要进行非常多的预处理,这样子就会非常的耗时,导致数据读取效率比较低,从而造成了上面说的显卡在等待CPU处理数据,导致占有率变为0%的情况。所以对于封装的数据格式,我们就可以先将数据预处理之后,直接用封装的数据格式保存下来,这样子在训练的时候,就避免了在训练的时候执行耗时的预处理了,可以说是一劳永逸了。
当然,除了TFRecord,还有很多的封装格式,比如npy,LMDB,H5,bin等文件格式,都可以实现一样的效果
-
使用DALI Dataloader

DALI Dataloader是Nvidia编写的用于快速读取数据的Dataloader库,与Pytorch官方实现的Dataloader使用CPU读取不同,因为Nvidia是生产GPU,那么DALI Dataloader当然是用Nvidia的显卡对数据进行读取。Nvidia对许多的数据预处理进行了专有的优化,可以让数据在GPU上预处理得到更快的速度。Nvidia官方描述的Pipeline如下:
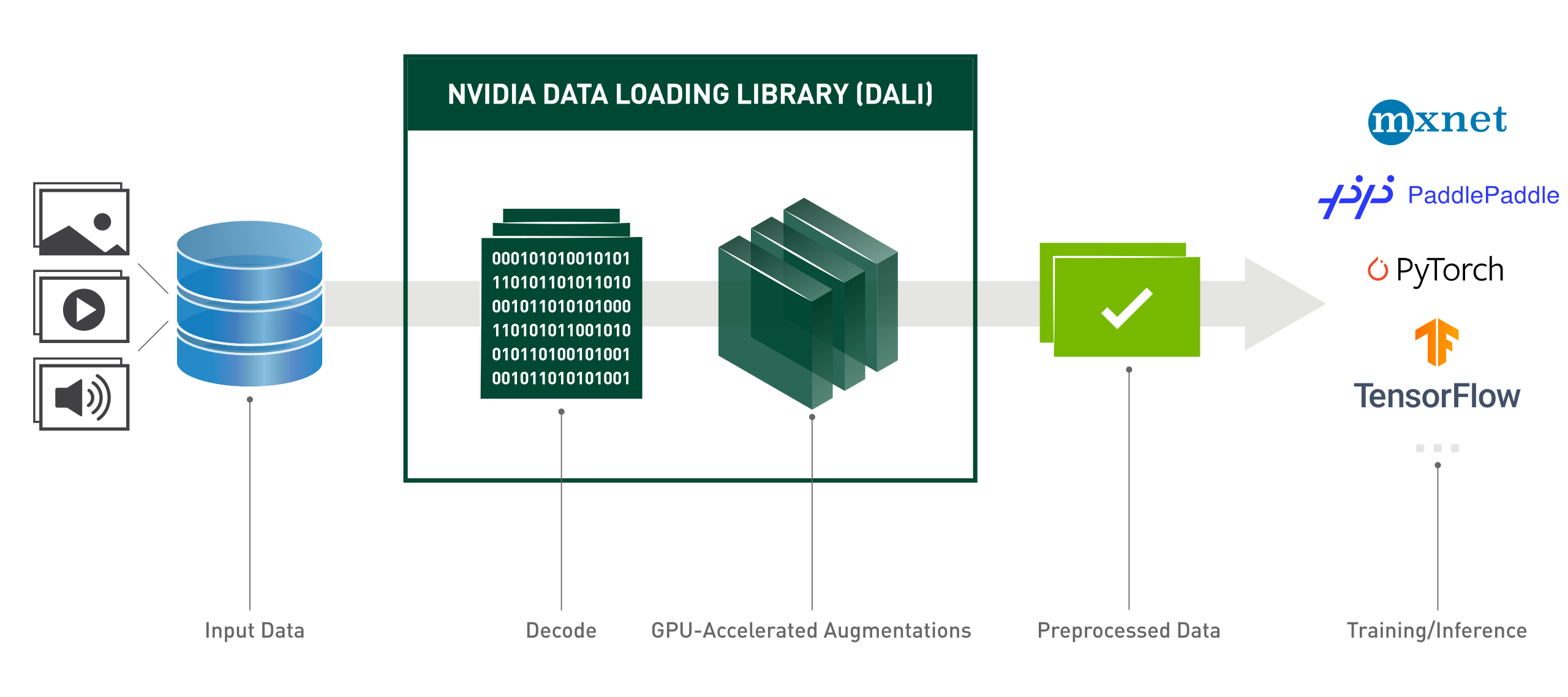
但是DALI的坑还是很多,例如内存泄漏,显存占用不断上升的问题,尤其是你要自定义数据集,难度会更大,但是加速效果是不容置疑的。
训练
-
加大Batch Size(不推荐)
增大Batch Size可以更好的利用显卡的大显存,通过减少数据放入和拿出显存的次数达到加速训练的目的,这个技巧也十分的直观,但是在更多的时候,增大Batch Size会带来更多的副作用,例如更大的Batch Size会让训练出来的网络泛化性能变差。如果只是为了加快网络的训练速度而改变了Batch Size,许多的超参也需要一起变化,一个经验就是当Batch Size翻倍的时候,需要将学习率也一起翻倍。
-
使用自动混合精度
深度学习一般采用的是Float32这一数据类型来储存模型的参数与中间变量,Float32带来了高精度的同时也带来了高内存占用与高计算量。在实验中也发现,如果将Float32降为Float16,在精度没有下降很多的情况下,显存占用可以减少一半,训练速度也可以加快很多,这一发现对不需要特别高精度的炼丹师尤为有用。
在Pytorch更新之后,也把原来由Nvidia第三方实现的AMP划入了Pytorch的官方库中,在最新的Pytorch中,可以直接使用下面的代码导入AMP模块
from torch.cuda.amp import autocast as autocast详细的使用方法已经有很多人进行了介绍,这里附上链接:PyTorch的自动混合精度(AMP)
在最近发布的显卡中,都将重心转移到了Float16、Float8和Int8的推理速度上,这也许是未来的一种趋势,因为庞大的模型在边缘计算中实在负担不起,牺牲掉一部分的速度来达到实时的检测是一笔划算的买卖。但是如果你是要复现论文或者要超越SOTA的同学,那最好还是老老实实的去使用Float32训练模型,因为用AMP图一时之快而掉了两个点,在某些领域就和SOTA有很大的差距了。
-
使用更快的优化器
如果你还在使用比较古老的优化器例如SGD,不妨换成AdamW之类最新的优化器,这类优化器在很多实验中表现出的误差和拟合速度上都会好于之前的优化器,在新优化器的加持下,更少的epoch就可以达到相同的效果,从而节约训练的时间。
-
不要频繁的在CPU和GPU之间传输数据
如果你在训练过程中,频繁的将数据在CPU和GPU之间传输,那么机器有很大一部分时间都在忙着传输数据,而不是真的在计算,因为变量转换储存的设备真的非常耗时!一般需要移动到CPU上给Numpy计算的操作,在Pytorch中都能找到替代的操作,这样就能避免移动到CPU上计算,然后在搬回来。
-
避免使用循环操作
在Python语言上,如果你使用for循环去计算一列的数据,那耗时会远远大于将一列的数据向量化之后在计算的时间。这是因为如果你向量化之后,例如使用Numpy或者Pytorch向量化,计算的时候实际调用的是底层的C\C++操作,这回远快于自己用for循环一个个算。如果数据量很庞大,实测会有百倍的差距。
验证
-
使用
torch.no_grad()torch.no_grad()的作用是让Pytorch运算的时候不计算梯度,也不保存梯度。这在每个训练轮次结束后的验证很有用,这不仅可以加快你的验证速度,也可以节约显存,以使用更大的Batch Size去验证。.eval()的作用是告诉模型每个Layer的工作模式,主要的操作对象就是Batch Normal层和DropOut层,当处在eval模式的时候,BatchNorm会停止更新,DropOut也会停止使用,这对验证出的结果是很重要的
加速效果很小?
就像上面说的,训练过程是遵循了木桶原理。例如,在你的训练过程中,CPU读取数据已经足够快了,可能这一轮数据还没被GPU计算得到结果,CPU都把下一轮的数据读取出来了。这时候你再去加速数据的读取速度,基本上不会对你的训练起到加速作用。这时候你应该做的应该是如何加速你显卡的计算速度,例如买更好的显卡🙀
优化的尽头是升级硬件

最后
深度学习在现在为止还是一门以实验为主导的学科,并没有非常坚实的理论基础,所以在更多的时候还是要不断的做实验,也就是调参。调参的过程是枯燥的,所以优化自己的训练流程可以更有效率的调到最优的参数,也希望上面的一些优化技巧能加速一下你的调参过程。

