Pytorch多卡训练
前一篇博客利用Pytorch手动实现了LeNet-5,因为在训练的时候,机器上的两张卡只用到了一张,所以就想怎么同时利用起两张显卡来训练我们的网络,当然LeNet这种层数比较低而且用到的数据集比较少的神经网络是没有必要两张卡来训练的,这里只是研究怎么调用两张卡。
现有方法
在网络上查找了多卡训练的方法,总结起来就是三种:
- nn.DataParallel
- pytorch-encoding
- distributedDataparallel
第一种方法是pytorch自带的多卡训练的方法,但是从方法的名字也可以看出,它并不是完全的并行计算,只是数据在两张卡上并行计算,模型的保存和Loss的计算都是集中在几张卡中的一张上面,这也导致了用这种方法两张卡的显存占用会不一致。
第二种方法是别人开发的第三方包,它解决了Loss的计算不并行的问题,除此之外还包含了很多其他好用的方法,这里放出它的GitHub链接有兴趣的同学可以去看看。
第三种方法是这几种方法最复杂的一种,对于该方法来说,每个GPU都会对自己分配到的数据进行求导计算,然后将结果传递给下一个GPU,这与DataParallel将所有数据汇聚到一个GPU求导,计算Loss和更新参数不同。
这里我先选择了第一个方法进行并行的计算
并行计算相关代码
首先需要检测机器上是否有多张显卡
USE_MULTI_GPU = True
# 检测机器是否有多张显卡
if USE_MULTI_GPU and torch.cuda.device_count() > 1:
MULTI_GPU = True
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "0, 1"
device_ids = [0, 1]
else:
MULTI_GPU = False
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
其中os.environ["CUDA_VISIBLE_DEVICES"] = "0, 1"是将机器中的GPU进行编号
接下来就是读取模型了
net = LeNet()
if MULTI_GPU:
net = nn.DataParallel(net,device_ids=device_ids)
net.to(device)
这里与单卡的区别就是多了nn.DataParallel这一步操作
接下来是optimizer和scheduler的定义
optimizer=optim.Adam(net.parameters(), lr=1e-3)
scheduler = StepLR(optimizer, step_size=100, gamma=0.1)
if MULTI_GPU:
optimizer = nn.DataParallel(optimizer, device_ids=device_ids)
scheduler = nn.DataParallel(scheduler, device_ids=device_ids)
因为optimizer和scheduler的定义发送了变化,所以在后期调用的时候也有所不同
比如读取learning rate的一段代码:
optimizer.state_dict()['param_groups'][0]['lr']
现在就变成了
optimizer.module.state_dict()['param_groups'][0]['lr']
详细的代码可以在我的GitHub仓库看到
开始训练
训练过程与单卡一样,这里就展示两张卡的占用情况
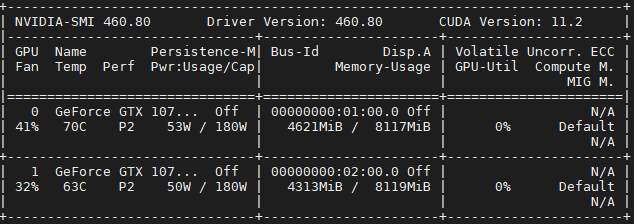
可以看到两张卡都有占用,这说明我们的代码起了作用,但是也可以看到,两张卡的占用有明显的区别,这就是前面说到的DataParallel只是在数据上并行了,在loss计算等操作上并没有并行
最后
如果文章那里有错误和建议,都可以向往指出😉

 浙公网安备 33010602011771号
浙公网安备 33010602011771号